今天要繼續介紹另外兩個集成學習的方法 max-out unit 結合與內插(interpolation)。
max-out unit 的結合方式如圖 1。為了使三種模型最後輸出的向量維度一致,做了些以下的修改:
經過上述的修改後,三種模型具有相同維度的輸出向量(60維)。接著我們使用 max-out unit 從三個60維的向量中選出最大值並將此經過挑選後的60維向量傳遞至輸出層中(dim=5, softmax)。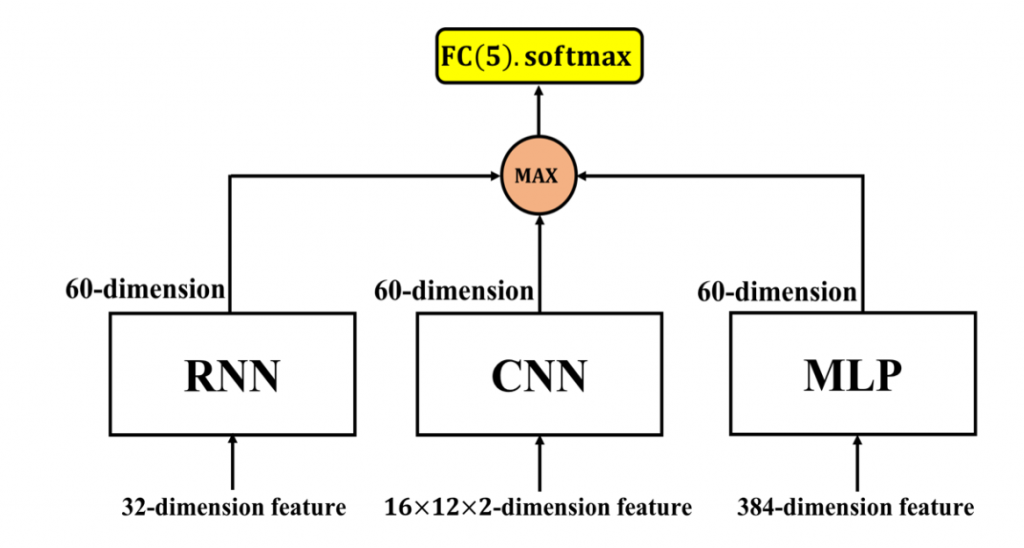
圖 1: 透過 max-out unit 結合靜態(MLP、CNN)、動態模型(RNN)
分類結果如表 1:
/ | A | E | N | P | R | UA recall
------------- | -------------
A | 387 | 111 | 63 | 29 | 21 | 63.3%
E | 285 | 831 | 308 | 42 | 42 | 55.1%
N | 736 | 966 | 2,639 | 719 | 317 | 49.1%
P | 8 | 9 | 41 | 144 | 13 | 67.0%
R | 108 | 83 | 161 | 120 | 74 | 13.6%
Avg.recall | - | - | - | - | - | 49.6%
表 1: Maxout-unit 結合分類結果混淆矩陣
集成學習的最後一部份我們採用內插的方式做結合
其中,、
與
分別為三種模型(LSTM-RNN with attention mechanism、multi-
scale CNN with attention mechanism 及 MLP)對於測試集所輸出的事後機率, 即為內插後的事後機率 (
)。
結果如下表2:
/ | A | E | N | P | R | UA recall
------------- | -------------
A | 382 | 102 | 64 | 29 | 30 | 63.2%
E | 281 | 811 | 301 | 40 | 75 | 53.8%
N | 713 | 853 | 2,599 | 737 | 475 | 48.3%
P | 8 | 6 | 39 | 148 | 14 | 68.8%
R | 107 | 75 | 140 | 123 | 101 | 18.5%
Avg.recall | - | - | - | - | - | 50.5%
表 2: 內插結合分類結果混淆矩陣
從所有模型的結果來說,rest 類別的分類是最困難的部份。與其它四類(angry、emphatic、neutral、positive)不同的是,rest 類是由所有不屬於其它四類的類別所組成的。因此,rest 類別資料的特徵具有高度的差異性,使得神經網路的學習變得更加困難。

