那麼在先前實作中,我們業已將 WordPress 網站建築在 AWS 環境中(可以詳【Day 05】 實作 - 設置初始環境於 AWS 建置個人的 WordPress 網站),那在 AWS 上要怎麼進行伺服器效能監控呢?
其實 AWS 業已建立良好的機制可以讓使用者來查看目前伺服器( EC2 )的情況,我們這兩天會一一來介紹並且也會實作如何設定 Alarm 以讓客戶能及時收到告警並進行後續處理
大家可以先至 AWS console 搜尋 EC2 ,並選取先前的主機的 Status checks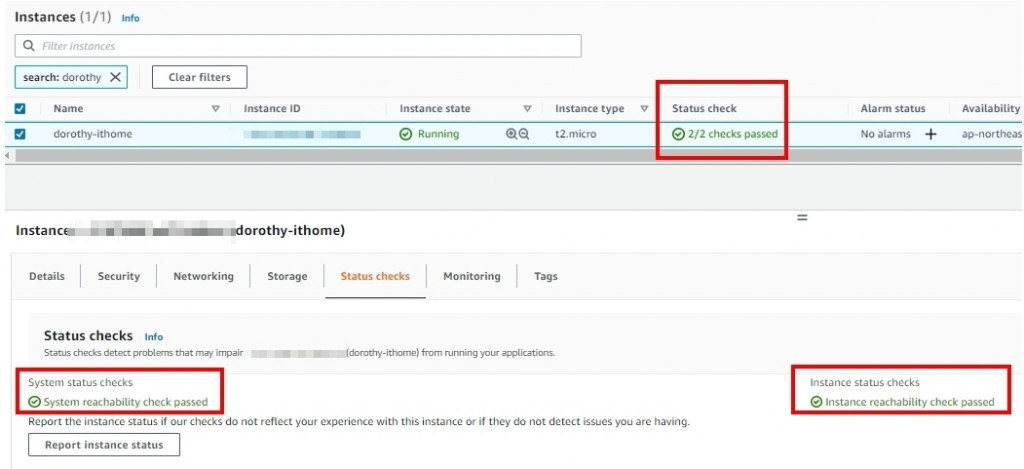
系統狀態檢查主要針對『伺服器所在的 AWS 環境中』是否有異常狀況,像是:
網路連線中斷
AWS 機房電力中斷
實體主機的軟體問題
實體主機上會影響網路連線的硬體問題
.
.
.
而關於雲端提供所有服務的相關基礎設施問題則是由 AWS 負責處理、介入修復的問題,我們使用者只要催促 AWS 趕快修好就好 XD
狀態檢查會每分鐘執行一次,AWS EC2 會傳送 ARP 請求封包至網路介面卡 (NIC),以便檢查主機的運作狀態、監控個別伺服器的軟體和網路組態,像是:
系統狀態檢查失敗
網路或啟動組態不正確
記憶體用盡
檔案系統毀損
核心不相容
.
.
.
若發生這類型的異常問題,則需要客戶/使用者自行進行修復,故我們應要設定告警機制以防止當發生 Instance status checks fail 的情況時,需要立即通知相關的 IT 人員,明天我們則會來實作設定告警機制的部分
我們可以透過 AWS CloudWatch 來監控主機資源狀況,預設情況下,AWS EC2 會每隔 5 分鐘將主機資料傳送到 CloudWatch,也可以啟用詳細監控,這樣會每隔 1 分鐘就會將資料傳送到 CloudWatch,而這些資料會保留 15 個月的時間供使用者存取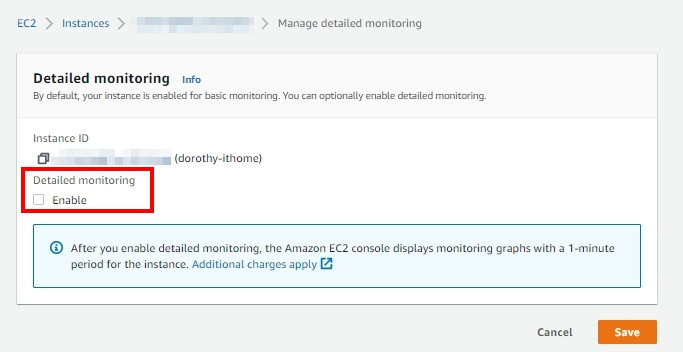
大家可以點選 AWS console 搜尋 EC2 、選取先前的主機的 Monitoring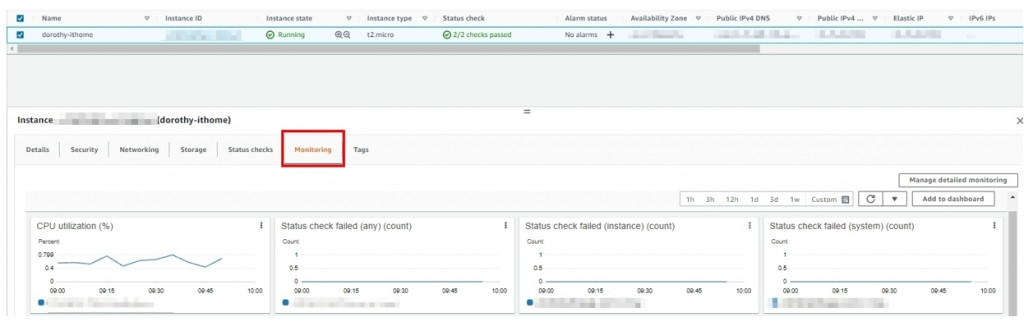
可以看到 Console 上業已針對主機 CPU、硬碟的讀取寫入、網路流量等指標進行資料蒐集並於 console 端以圖表呈現其波動(詳細指標說明請詳[1]),因當某些指標數值突然衝高,可能會導致主機無法承受負載進而服務中斷,故我們可以進行設定若指標達到某個百分比/數值時,則觸發告警並通知相關同仁進行處理或者設定自動擴展機制以因應突如其然的流量暴增
明天我們則會實作如何設定 AWS 伺服器告警機制,明天見啦~
參考&相關來源:
[1] Instance metrics
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/viewing_metrics_with_cloudwatch.html

