K-近鄰演算法是一個以已知的資料作為輸入,為資料進行分類的演算法,在日常生活中有非常多應用。
舉例來說,假設我們想要幫一些不知道是章魚還是烏賊的動物分類,我們依照這些動物的特徵,把過往的資料用像下方的圖表表示,例如x軸代表身體長度,y軸代表顏色深淺,圖中紅色的點都是烏賊(體型細長、顏色較淺),綠色的點都是章魚(體型較短、顏色較深)。

那麼當今天碰了兩隻未知的新動物,將牠們的資料也加進圖表中(如下圖白色三角型)。
我們可能會將左邊的點(2.5, 7)歸類為章魚,而右邊的(5.5, 4.5)歸類為烏賊,因為它們分別靠近綠色和紅色兩堆資料。
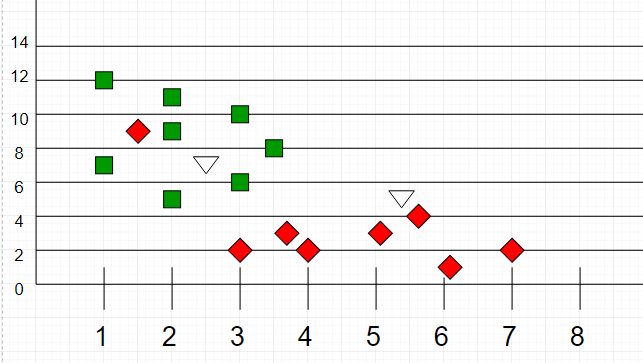
這就是k-近鄰演算法的想法,以距離最近(也就是相似度高)的已分類資料來為新的資料分類。
具體來說,k-近鄰指的是「最近的K個鄰居」,代表以K個鄰居中佔多數的分類,作為新資料的分類。k的大小會因資料而異,基本上是不會太大的正整數。而距離遠近則可以以幾種方式計算,常見的方法如計算平面座標兩點距離。以上圖為例,如果k=5,這時有一個新的點要進行分類,就計算出距離最近的五個點,如果其中有三個紅色,兩個綠色,則新的資料被歸類為紅色。
k-近鄰演算法是機器學習(machine learning)中很重要的演算法。例如運用在臉部、筆跡、語音等圖形識別(pattern recognition)的工作中,就是給電腦有明確分類以及特徵的樣本,訓練電腦作出一定準確度的判斷和辨別。
另外一個應用的地方,就是隨處可見的各種影片、音樂、商品推薦系統。例如一個影片播放平台可能會請用戶為電影作出評分,分數相仿的用戶便是特徵相似的近鄰,以此就可以把電影推薦給有相似喜好的人。而當評分的影片越多、種類越廣,就越能知道哪些用戶相似度高,並更精準地作出推薦。
以上提到的輸出大多是資料的分類。除此之外,輸出也可以以k個近鄰的值來計算的平均值。
假設一個農夫想要知道今年要買多少種子,或者經營燒烤店的老闆想知道要進貨多少肉,他們就可以參考k-近鄰演算法得出的平均值。只要找出跟答案相關性高的特徵(例如是否下雨、有無節/假日、疫情狀況如何),接著以這些特徵找出相似度高的過往資料(例如過去k個都是下雨天、連假的日子),計算這些過往日期訂貨量的平均值,就可以預估當前的進貨量。

