本文說明使用scrapy爬蟲函式庫抓取海運FBX指數。
波羅的海貨櫃運價指數[FBX]
波羅的海貨運指數(Freightos Baltic Index, FBX)是線上貨運平台 Freightos、波羅的海交易所(Baltic Exchange)共同編製指數,反映亞洲、歐洲、美洲之間12條全球主要航線的40呎貨櫃現貨運價,包括海運費及相關附加費(燃油附加費、旺季附加費、港口擁擠附加費、運河附加費等),不含進口關稅、出發港/目的港之港口費用。FBX 指數在於其彙整國際貨運承攬業 (freight forwarder) 商業資料庫的實際價格,提供貨櫃報價的綜合指數。
pip install scrapy
scrapy startproject crawlerFBX
建立好crapy專案後,即建立以下目錄結構檔案
scrapy genspider fbx_spider fbx.freightos.com
於spiders目錄下,建立抓取fbx.freightos.com之fbx_spider範例程式
import scrapy
import json
import matplotlib.pyplot as plt
import pandas as pd
class FbxSpiderSpider(scrapy.Spider):
name = 'fbx_spider'
allowed_domains = ['fbx.freightos.com']
start_urls = ['https://fbx.freightos.com/api/lane/FBX?isDaily=true']
def parse(self, response):
dict_day2FBX = {}
#使用body_as_unicode()方法處理unicode編碼資料
jsonresponse = json.loads(response.body_as_unicode())
print("jsonresponse:",jsonresponse)
#解析Json存成dict
for item in jsonresponse["indexPoints"]:
fbxvalue = item["value"]
indexDate = item["indexDate"]
print("fbxvalue:",fbxvalue," indexDate:",indexDate)
dict_day2FBX[indexDate] = fbxvalue
print("dict_day2FBX:\n",dict_day2FBX)
#將字典( dict)結構轉成DataFrame
df = pd.DataFrame(list(dict_day2FBX.items()), columns=['Date', 'FBXValue'])
df['Date'] = pd.to_datetime(df['Date'])
print("df:\n",df)
#繪圖
df.plot(x='Date', y='FBXValue', figsize=(16, 9),color='red'); plt.legend(loc='best')
plt.ylabel("FBX Value")
plt.savefig("FBX.png")
scrapy crawl fbx_spider
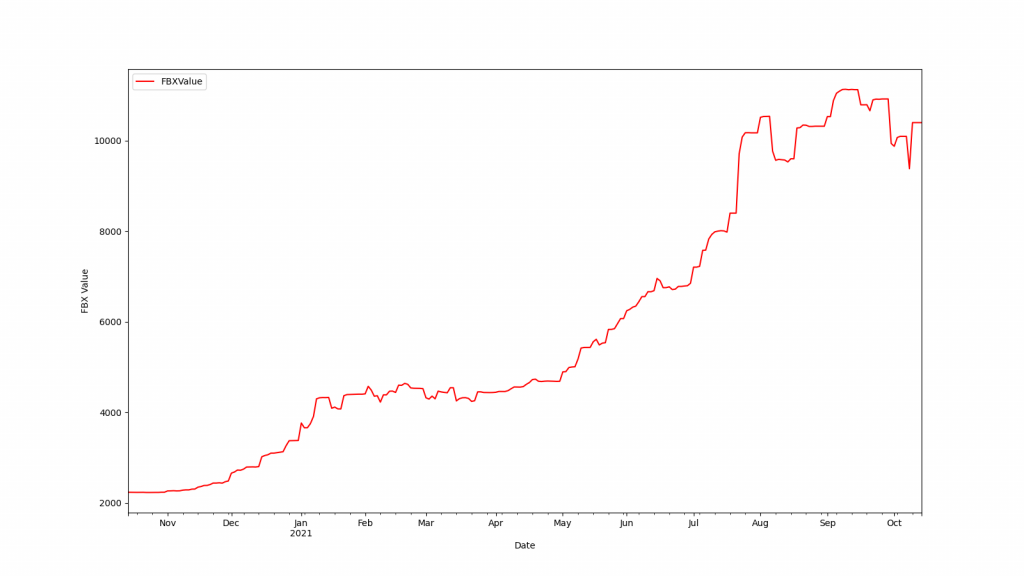
使用scrapy爬蟲函式庫抓取海運FBX指數及利用matplotlib函式庫繪出成果。

