CUDA Toolkits 是 NVIDIA GPU 卡的程式工具箱,可呼叫相關函數,在GPU卡上進行相關數學運算,尤其是張量(Tensor),常用於圖形處理或深度學習的計算。
使用TensorFlow一段時間,常發生GPU記憶體不足(OOM),因此,想直接使用 CUDA Toolkits,看看是否有改善空間,或許也可以更了解GPU的運作,因此,就來一趟 CUDA 學習之旅吧 !!
安裝 CUDA Toolkits 之前,須確定驅動程式是否安裝,對應可安裝的CUDA Toolkits版本。步驟如下:
GPU卡驅動程式:一般而言,GPU卡驅動程式會隨PC購買就已安裝妥當,可在桌面按滑鼠右鍵,選擇【NVIDIA 控制面板】,視窗出現後點選左下角的【系統資訊】,即可看到GPU卡相關訊息,相關說明可參閱『Win10 安裝 CUDA、cuDNN 教學』。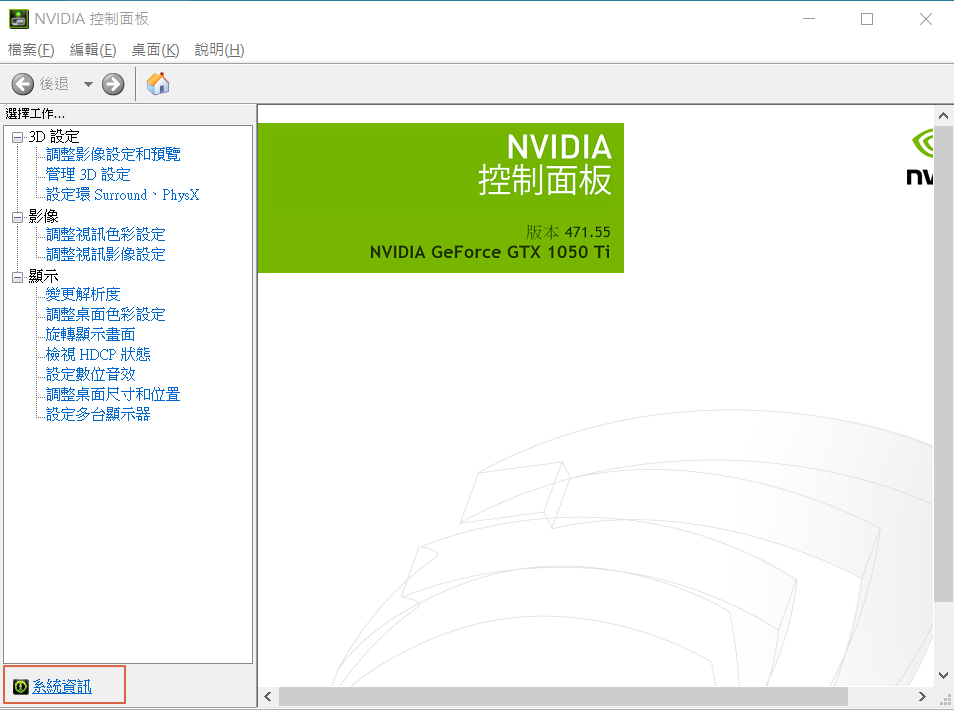
圖一. GPU卡系統資訊
安裝 Visual Studio(簡稱 vs):自微軟官網下載Visual Studio,目前CUDA的範例支援vs 2017/2019,故安裝 vs 2019。
安裝 CUDA Toolkits:筆者有使用TensorFlow,故配合TensorFlow規定安裝相對的版本,目前為v11.2。
CUDA Toolkits 安裝後,可以在 C:\ProgramData\NVIDIA Corporation\CUDA Samples 目錄下找到一堆範例程式,我們就先來執行看看吧。
首先,找一支向量運算的專案 v11.2\0_Simple\vectorAdd,滑鼠雙擊(double click) vectorAdd_vs2019.sln,會以vs 開啟專案,在專案名稱按滑鼠右鍵,選擇【屬性】,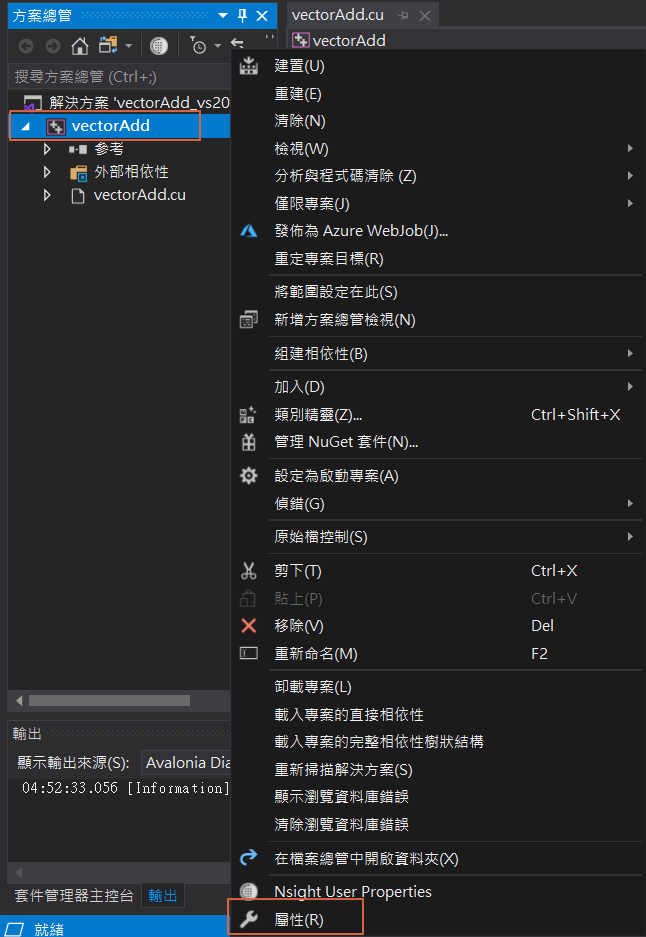
圖二. vs 專案屬性
點選【CUDA C/C++】> 【Common】,在【CUDA Toolkits Custom Dir】輸入CUDA Toolkits安裝目錄,通常是【C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2】,注意目錄最後的版本別,要隨安裝版本不同而修改,按確定後,即可建置專案。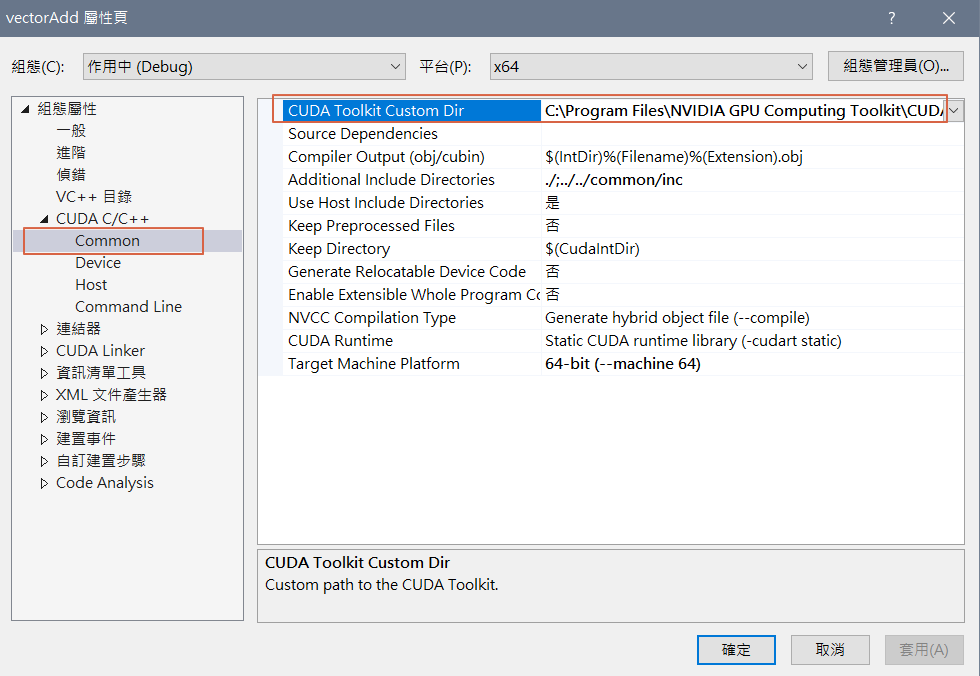
圖三. 設定 CUDA Toolkits 安裝目錄
執行:出現以下訊息即大功告成。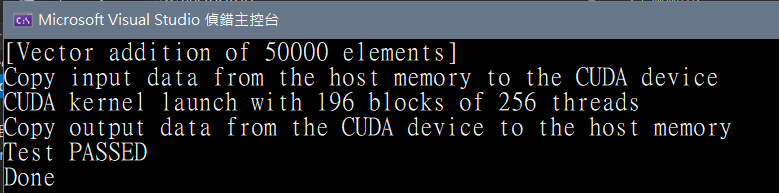
圖四. 執行結果
再測試另一專案 v11.2\1_Utilities\deviceQuery\deviceQuery_vs2019.sln,執行結果如下,可得知GPU卡相關訊息。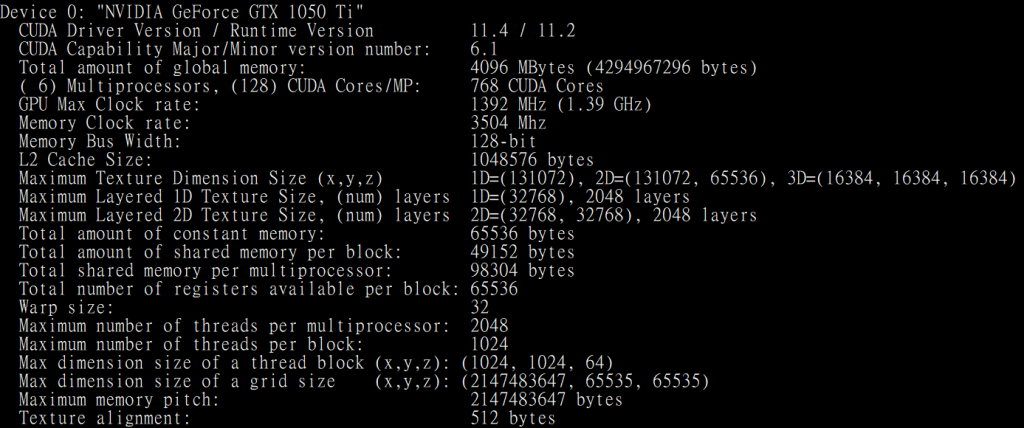
圖五. deviceQuery 執行結果
接下來從無到有,寫一支全新的程式,步驟如下:
建立新專案,選擇【CUDA 11.2 Runtime】範本,按【下一步】。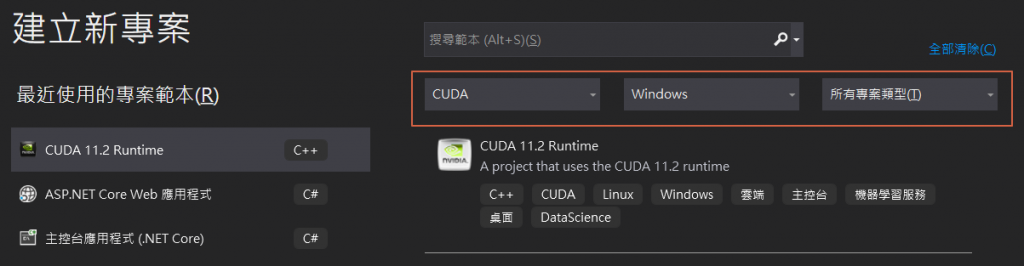
修改專案屬性及位置,按【下一步】。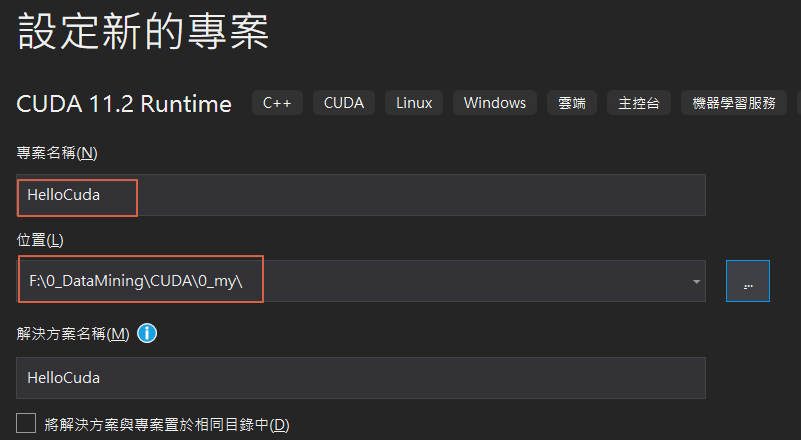
專案建立後,會自動產生一個程式檔kernel.cu,為兩向量相加的範例。
同上,點選【CUDA C/C++】> 【Common】,在【CUDA Toolkits Custom Dir】輸入CUDA Toolkits安裝目錄,通常是【C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2】,按【確定】。
執行:出現以下訊息即大功告成。
{1,2,3,4,5} + {10,20,30,40,50} = {11,22,33,44,55}
#include <iostream>
#include <stdio.h>
__global__ void myfirstkernel(void) {
}
int main(void) {
myfirstkernel << <1, 1 >> > ();
printf("Hello, CUDA!\n");
return 0;
}
Hello, CUDA!
global 表示 myfirstkernel 函數在 GPU 執行,目前函數內容是空的。而 main() 仍然是在 CPU 執行。
<< <1, 1 >> > :<<<block 數目, thread 數目>>>
現在 CPU、GPU都是多核心的設計,程式透過多執行緒(Multi-threads)平行處理各項子任務,可以明顯縮短執行時間,一個程式會被切割給多個執行緒區塊(blocks of threads)獨立執行,即平行處理。如下圖,在兩核(Streaming Multiprocessors, SM)及四核的GPU執行,程式會自動分配到所有的執行緒區塊,稱為『Automatic Scalability』。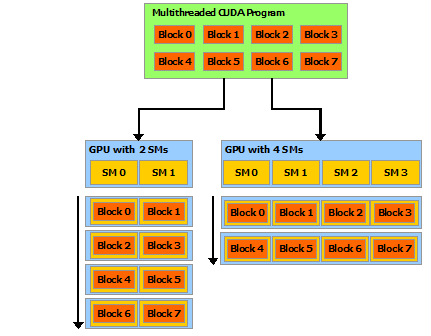
圖五. Automatic Scalability,圖片來源:CUDA C++ Programming Guide
一個區塊內的所有執行緒都會在同一核(processor core)處理,每個區塊最多可以有1024個執行緒,上述程式就是指定一個區塊,且含一個執行緒,下次我們再來測試使用多區塊、多執行緒。
其實 CUDA Toolkits 也附一個編譯器 NVCC,可直接編譯C++程式,例如一個程式 hello.cu 內容如下:
#include<stdio.h>
__global__ void cuda_hello(){
printf("Hello World from GPU!\n");
}
int main() {
printf("Hello World from CPU!\n");
cuda_hello<<<1,1>>>();
return 0;
}
執行下列指令即可建制執行檔 hello.exe。
nvcc hello.cu -o hello.exe
適合簡單的程式,但不能除錯。
 I code so I am
I code so I am

 iThome鐵人賽
iThome鐵人賽