GPU記憶體類別有非常多種,各有所長,如果善用可進一步提升執行效能,參考下圖: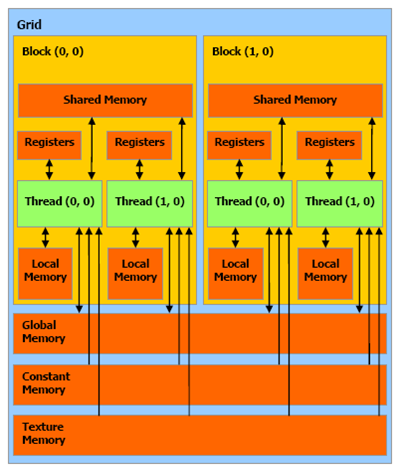
圖一. GPU記憶體類別,圖片來源:『CUDA Tutorial by Jonathan Hui』
比較說明如下表: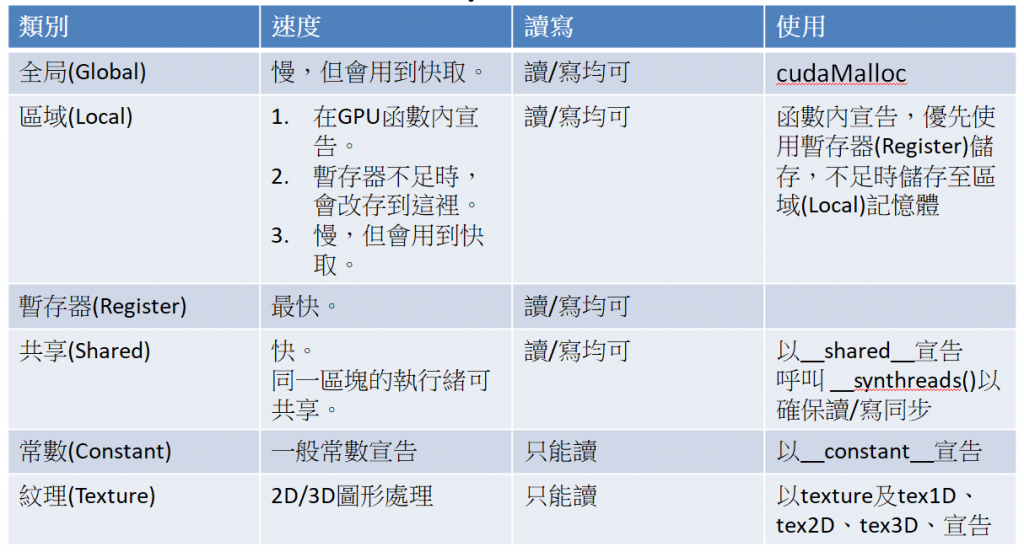
圖二. GPU記憶體類別與比較
__global__ void gpu_function(int* d_a, int* d_b, int* d_c) {
// 區域(Local)變數
int tid = threadIdx.x;
...
}
int* d_a;
...
cudaMalloc((void**)&d_a, N * sizeof(int));
// 宣告常數
__constant__ int d_f;
__global__ void gpu_function(float *d_in, float *d_out) {
// 使用常數
d_out[tid] = d_f * d_in[tid];
}
int main(void) {
// 設定常數
int h_f = 2;
// 複製 h_f 至 d_f
cudaMemcpyToSymbol(d_f, &h_f, sizeof(int),0,cudaMemcpyHostToDevice);
gpu_function << <1, N >> >(d_in, d_out);
}
當多執行緒運算時,會使用到同一個變數時,我們就可以利用共享記憶體,例如『上一篇』矩陣運算,由於全局(Global)記憶體較共享(Shared)記憶體存取較慢,故可將來源矩陣(a、b)複製到共享變數,再進行計算。
__global__ void gpu_inner_product_shared(float* d_a, float* d_b, float* d_c)
{
// 輸出所在格子的座標
int row = threadIdx.x;
int col = threadIdx.y;
//Defining Shared Memory
__shared__ float shared_a[A_ROW_SIZE][A_COLUMN_SIZE];
__shared__ float shared_b[B_ROW_SIZE][B_COLUMN_SIZE];
for (int k = 0; k < A_COLUMN_SIZE; k++)
{
shared_a[row][k] = d_a[row * A_COLUMN_SIZE + k];
}
for (int k = 0; k < B_ROW_SIZE; k++)
{
shared_b[k][col] = d_b[k * B_COLUMN_SIZE + col];
//__syncthreads();
}
// // 點積
// printf("row=%d, col=%d\n", row, col);
for (int k = 0; k < A_COLUMN_SIZE; k++)
{
// 第一個輸入矩陣的【列】與第二個輸入矩陣的【行】相乘
d_c[row * B_COLUMN_SIZE + col] += shared_a[row][k] * shared_b[k][col];
//printf("result=%d, A=%d, B=%d\n", row * B_COLUMN_SIZE + col, row * A_COLUMN_SIZE + k, k * B_COLUMN_SIZE + col);
//__syncthreads();
}
}
宣告與複製動作都在多執行緒完成,不會有重複宣告的困擾,真是太神奇了。
完整程式放在『GitHub』的InnerProduct目錄。
 I code so I am
I code so I am
