以下內容來自這裡
此處將會練習創建 Azure ML,使用其內建的筆記本功能(內容來自這裡)
所有服務 → AI + 機器學習服務 → 機器學習
基本
資源群組:RG1(隨便取)
工作區名稱:WS(隨便取)
區域:美國西部(此處建議美西或日本,網路比較順)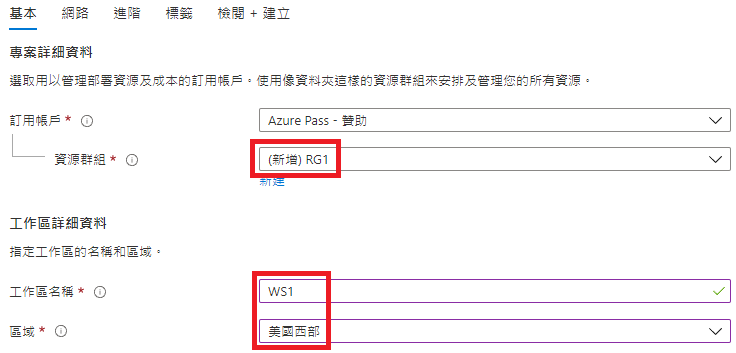
建立
前往資源 → 啟動工作區
新增筆記本
在左側可以發現互動按鈕,點選「計算」後,上方出現四個選項
此時,我們先選擇建立計算執行個體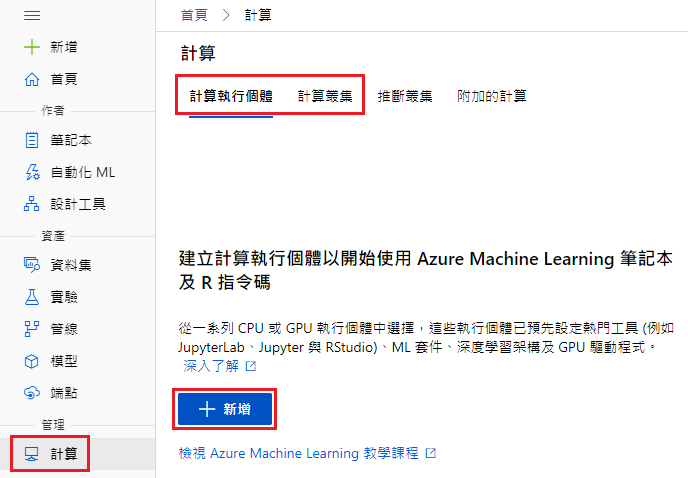
必要設定
計算名稱:myCP(隨便取)
虛擬機器類型:CPU(比較省錢)
核心類型選:Standard_DS11_v2(比較省錢)
進階設定
使用預設即可
建立
回到筆記本,會發現已經可以選用剛建立的虛擬機來計算
這時我們用以下程式碼,試著把連線到這的主機名稱印出來
首先,安裝套件
pip install azureml-sdk
嘗試印出所有連線的主機名稱
from azureml.core import Workspace
ws = Workspace.from_config()
for compute_name in ws.compute_targets:
compute = ws.compute_targets[compute_name]
print(compute_name, ':', compute.type)
此時會發現下方出現一排文字:
To sign in, use a web browser to open the page https://microsoft.com/devicelogin and enter the code EET7MBNGK to authenticate.
照著指示點擊網站,輸入驗證碼(也就是 EET7MBNGK)並登入就可以了
>> myCP : ComputeInstance
此處將會練習創建 Automated ML,並用其評估模型(內容來自這裡)
計算 → 計算叢集 → 新增
虛擬機器
位置:美國西部(連線比較快)
虛擬機器類型:CPU(比較省錢)
核心類型選:Standard_DS11_v2(比較省錢)
進階設定
計算名稱:Cluster(隨便取)
節點數目下限:0(閒置的時候會自動關閉多餘此數量的虛擬機)
節點數目上限:2
建立
首先把這裡的資料下載下來,存成 diabetes.csv 檔名
接著選擇資料集 → 建立資料集 → 來自本機的檔案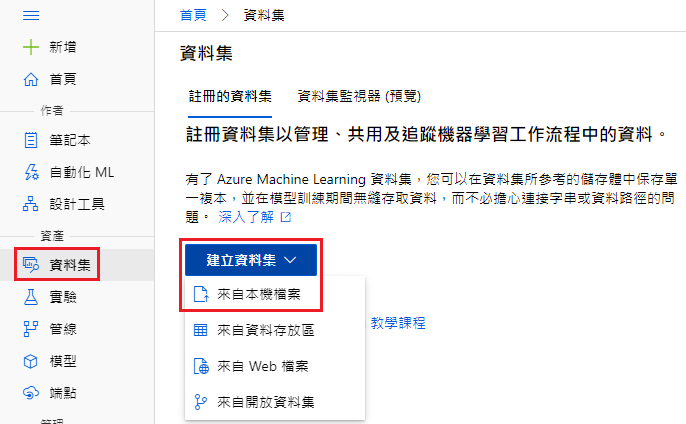
基本資訊
名稱:diabetes.csv
資料集類型:表格式
描述:Diabetes data(隨便)
資料存放區與檔案選取
為你的資料集選取檔案 → 上傳檔案 → 找到剛才存到電腦中的 diabetes.csv
設定與預覽
檔案格式:分隔符號(其它選項還有純文字、Parquet 檔案、JSON 行等)
分隔符號:逗號(看你的檔案用什麼分隔資料)
編碼:UTF-8
資料行標頭:所有檔案都有相同的標頭
(V) 資料集包含多行資料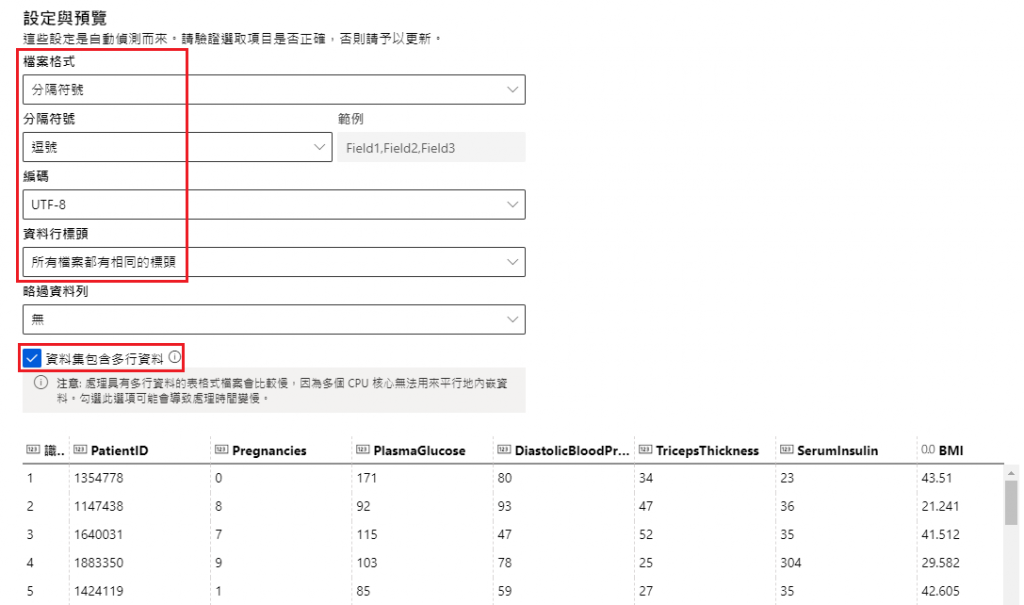
結構描述
使用預設即可
確認詳細資料
建立
自動化 ML 即是讓 Azure ML 自動幫你使用資料集計算,找出最佳 model
自動化 ML → 新增自動話 ML 回合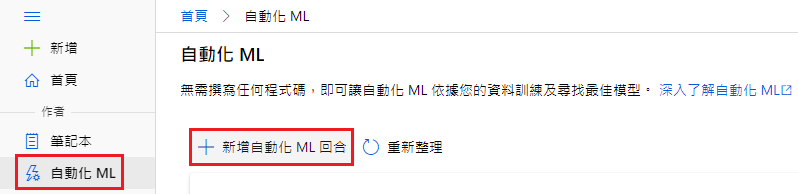
選取資料集
選取 diabetes.csv
實驗名稱
新增實驗名稱:mslearn-automl-diabetes(隨便)
目標資料行:Diabetic(這個欄位是選擇資料集中的 y 值)
選取計算類型:計算叢集
選取 Azure ML 計算叢集:Cluster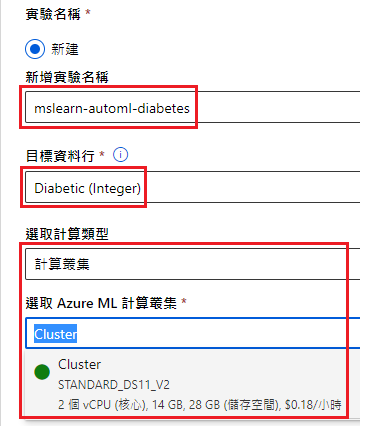
選取工作和設定
因為這個資料集是糖尿病,因此選擇分類(預設就是分類)
點選下方「檢視其他組態設定」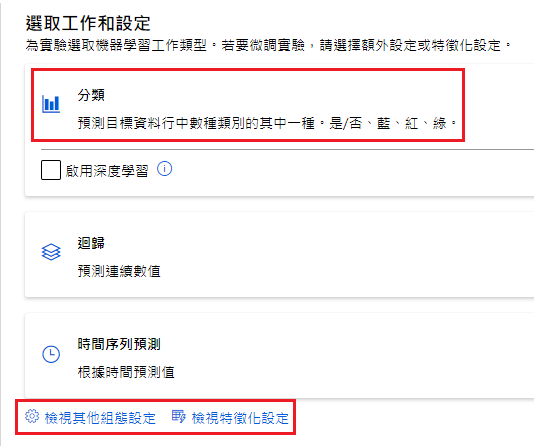
其他組態
主要計量:加權後的 AUC(採用 AUC 對模型評分)
(V) 解釋最佳模型
封鎖的演算法:(有些模型不適合演算此類型資料,可以從這裡剃除)
訓練作業小時:0.5(作業超過半小時就結束演算)
計量分數閾值:0.90(90% AUC 以上會結束演算)
儲存
驗證和測試
實驗 → mslearn-automl-diabetes → khaki_rhubarb_3p1l7btj → 詳細資料
最佳演算法名稱:MaxAbsScaler, LightGBM
加權後的 AUC:0.98996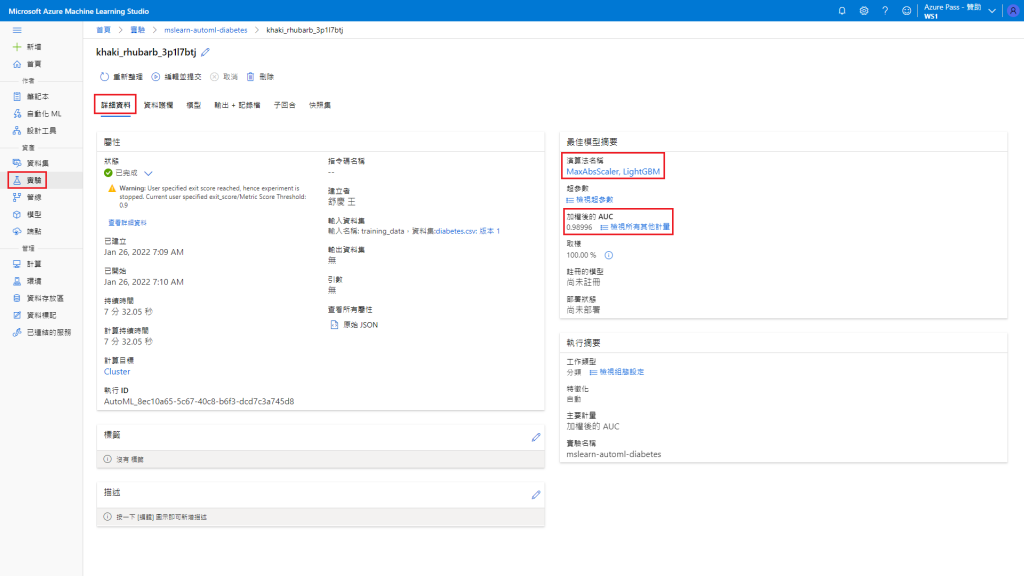
接續上一步驟,點擊 MaxAbsScaler, LightGBM → 部屬 → 部屬到 Web 服務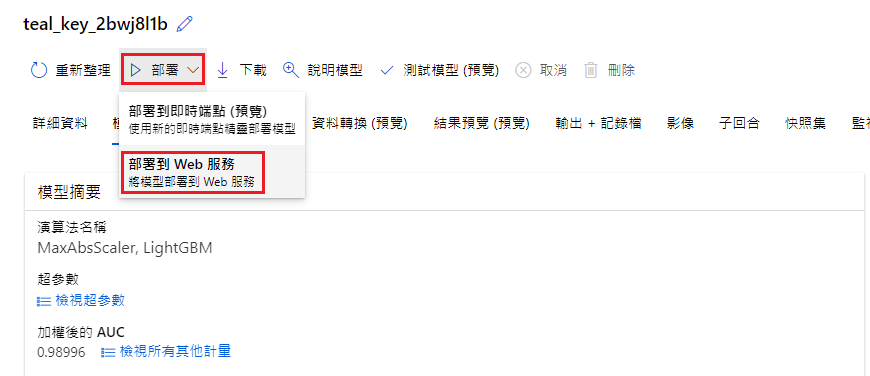
部屬模型
名稱:auto-predict-diabetes(隨便)
描述:Predict diabetes(隨便)
計算類型:Azure 容器執行個體
(V) 啟用驗證
(X) 使用自訂部屬資產
部屬
端點 → 測試 → 選擇資料輸入方式(此處為 csv) → 測試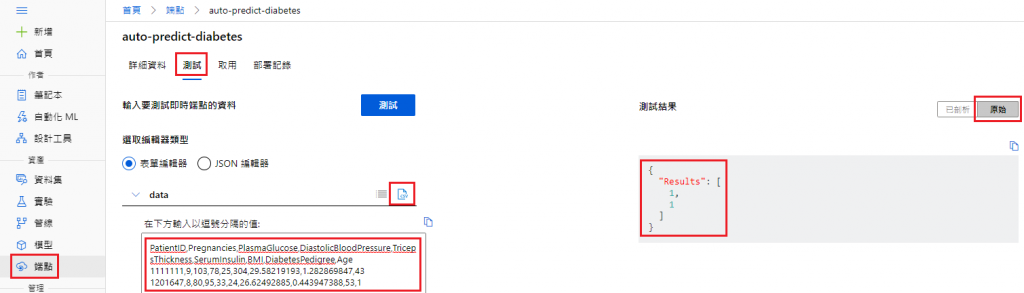
此處將會練習 Azure Machine Learning Designer 創建模型(內容來自這裡)
Azure ML 提供了設計 pipeline 的功能,可以自定義想要的生產管線;或者使用現成的範本操作。
我們就直接使用 Part2. 建立的「計算叢集」與「資料集」來操作,不額外建立。
設計工具 → 新增管線 → 易於使用的預建模組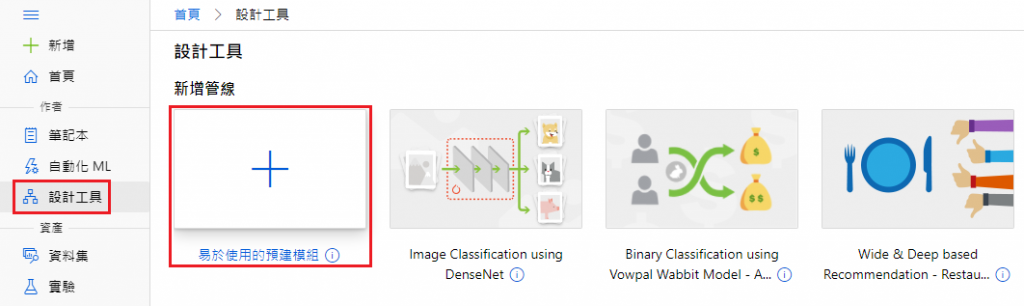
點選小齒輪進入設定
選取計算類型:計算叢集
選取 Azure ML 計算叢集:Cluster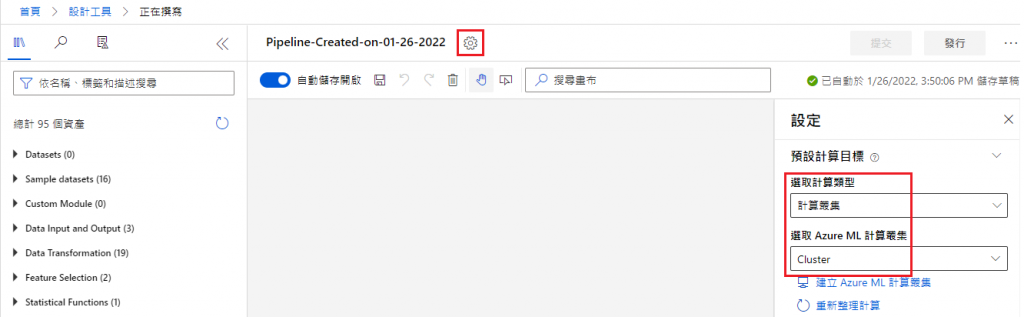
接著會看到一面灰色的畫布,我們會在這建立自訂的管線
Datasets
首先,點選 Datasets,用滑鼠將其拖曳至畫布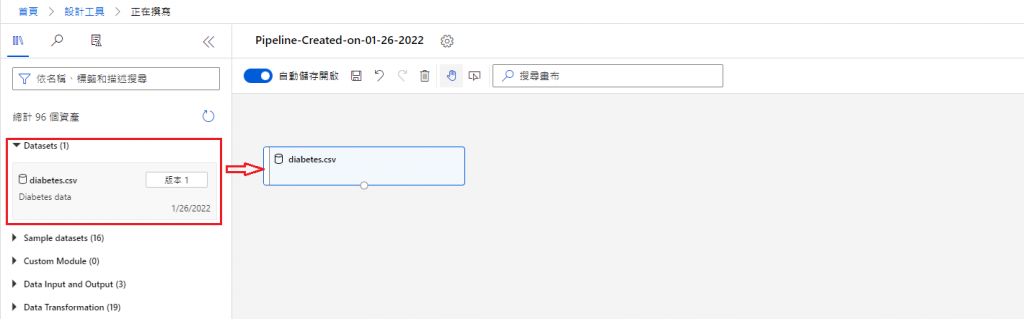
Normalize Data
接著在搜尋欄查找 Normalize Data 並拖曳到畫布,將 Datasets 連接到 Normalize Data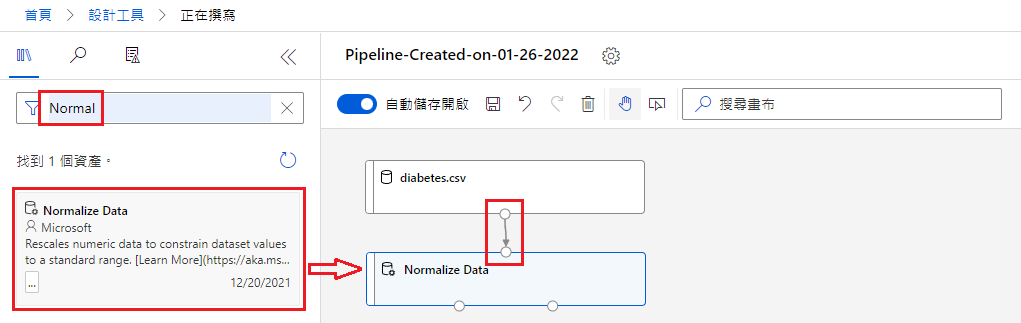
此時點選 Normalize Data,系統會要求我們選取「需要標準化」的欄位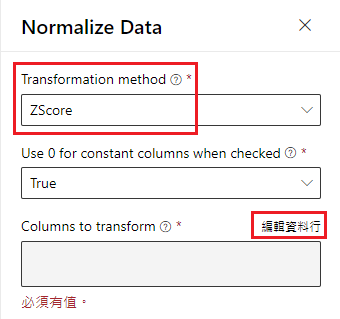
依次輸入以下欄位:
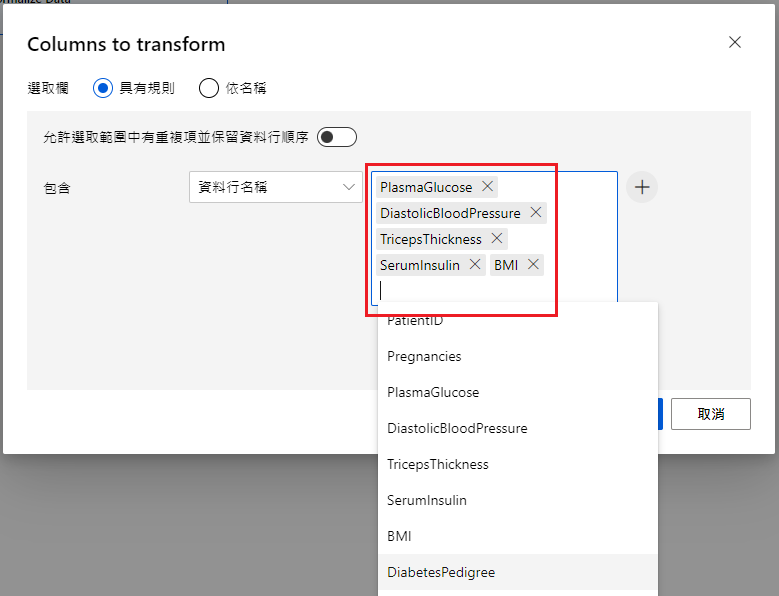
Split Data
第三步是分割資料,一樣拖曳到畫布,將 Normalize Data 連接到 Split Data
值得注意的是,分割方法有以下三種:
Split mode:因為是分析糖尿病,所以選擇 Split Rows 就好。
Fraction of rows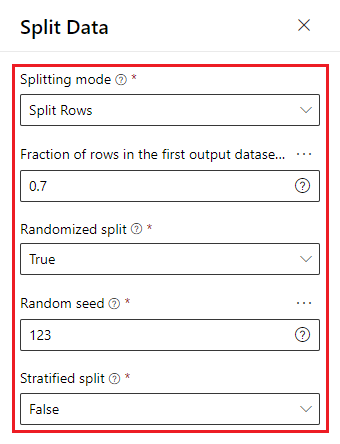
Train Model
第四步,把 Train Model 拖曳進畫布,並把 Split Data 連接到 Train Model 的「右上」(稍後會解釋)。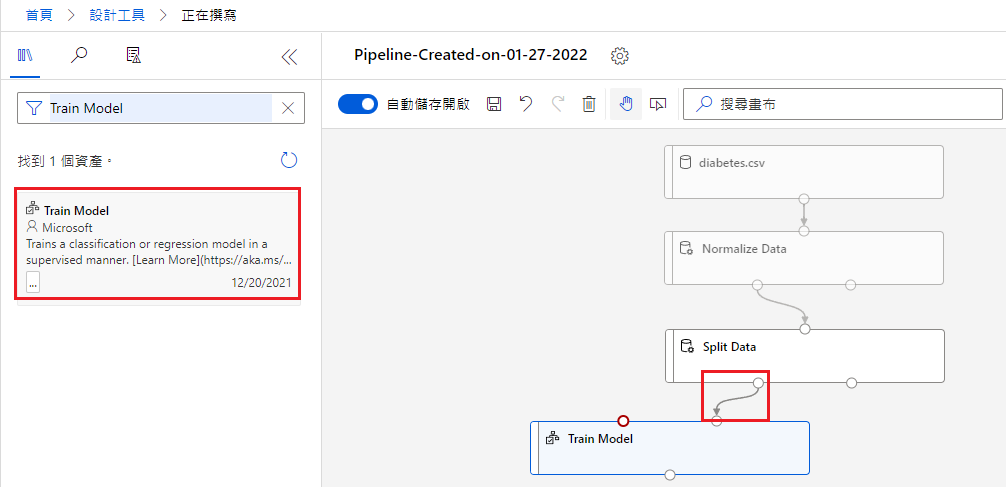
接著點畫布中的 Train Model,設定 Label Column:Diabetic(要分析的 y)
Two-Class Logistic Regression
選擇一個演算法,這邊選用的是 Two-Class Logistic Regression。
將它拖曳到 Split Data 的左方;Train Model 的上方,並將它與 Train Model 連接。
這邊的意義是,Train Model 將 Split Data 的資料用 Logistic Regression 建模。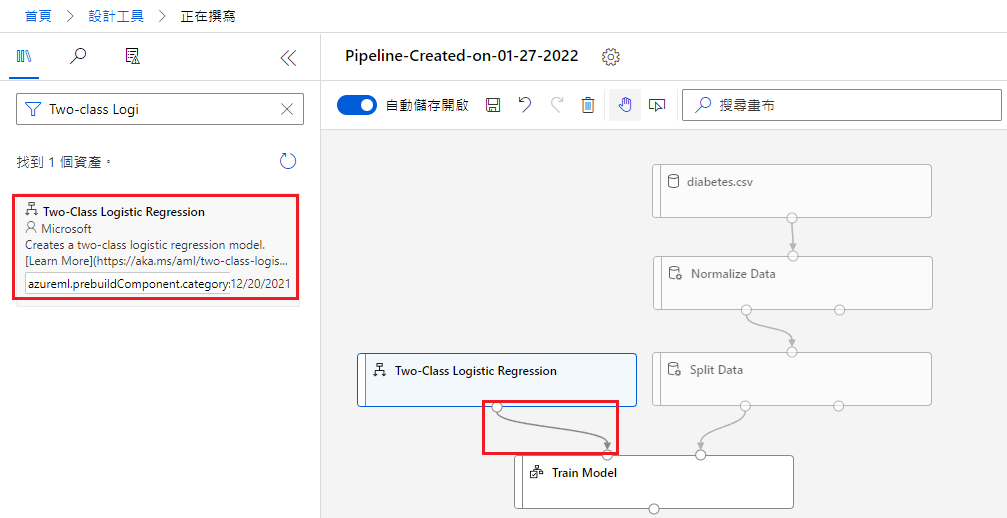
Score Model
第五步,把 Score Model 拖曳進畫布,把 Train Model 連接到 Score Model 的「左上」;同時把 Split Data 連接到 Score Model。
這邊的意義是,Score Model 將 Split Data 的資料為 Train Model 跑分。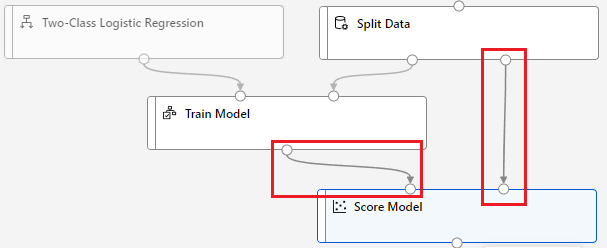
Evaluate Model
最後是評分模型,直接拖曳並將 Score Model 連接即可。可同時連接多個模型。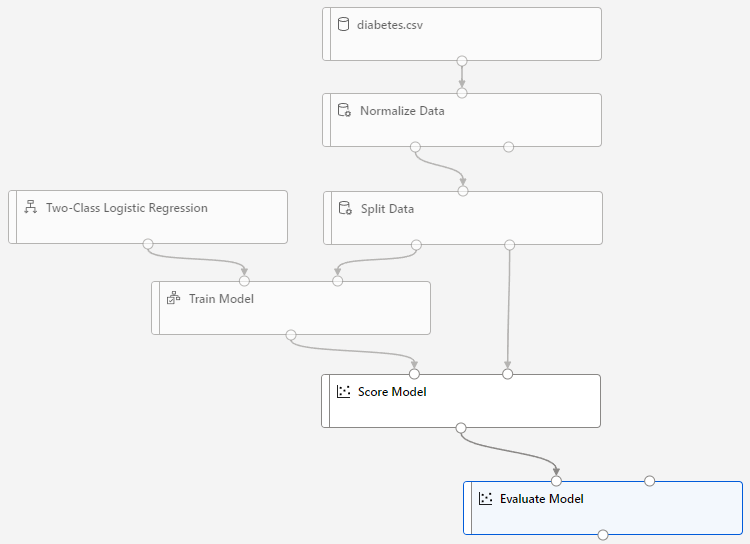
完成產線並且執行後,我們可以對單個步驟按右鍵預覽資料。
比方說,我們對 Score Model 按右鍵預覽資料,就可以看到模型的預測機率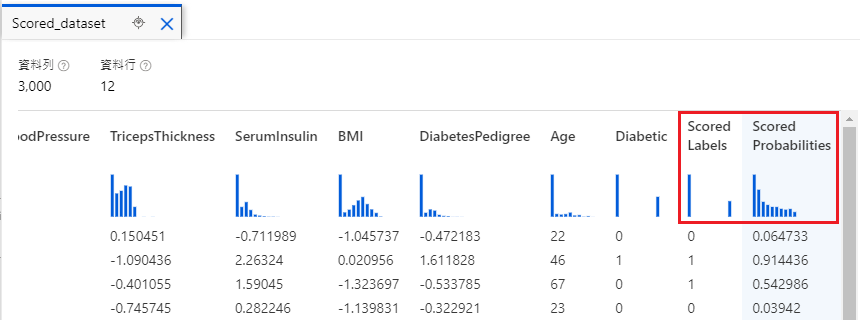
而對 Evaluate Model 查看,則會顯示 ROC (AUC),混淆矩陣等資訊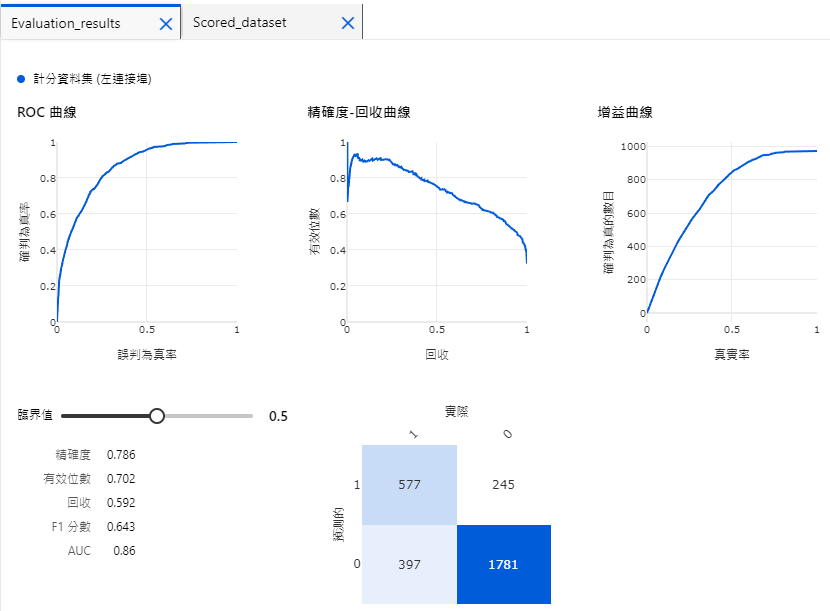
提交完成後,右上角提交旁邊會多出一個「建立推斷管線」,其中又分成: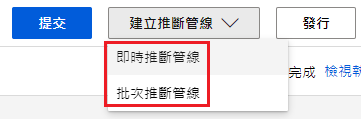
這邊為了方便,選擇即時推斷管線就好,完成後如下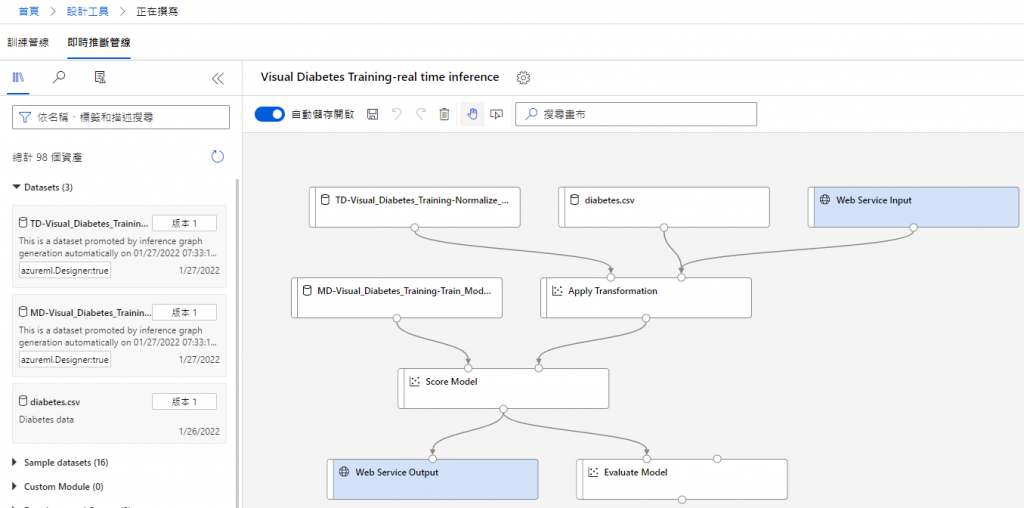
接著按右上角「提交」,新增實驗名「mslearn-designer-predict-diabetes」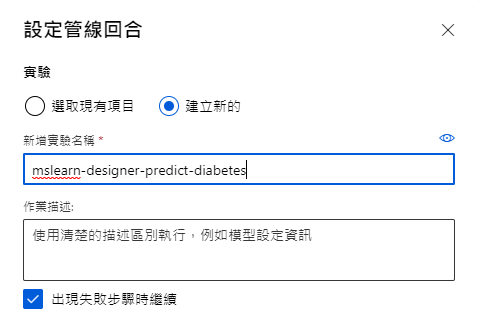
提交完成後,就可以按右上角「部屬」,進入設定畫面
名稱:designer-predict-diabetes
描述:Predict diabetes.
計算類型:Azure 容器執行個體
部屬完成後,在端點就可以看到部屬完成了!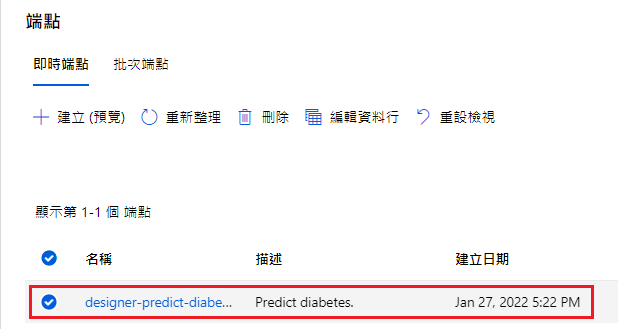
.
.
.
.
.
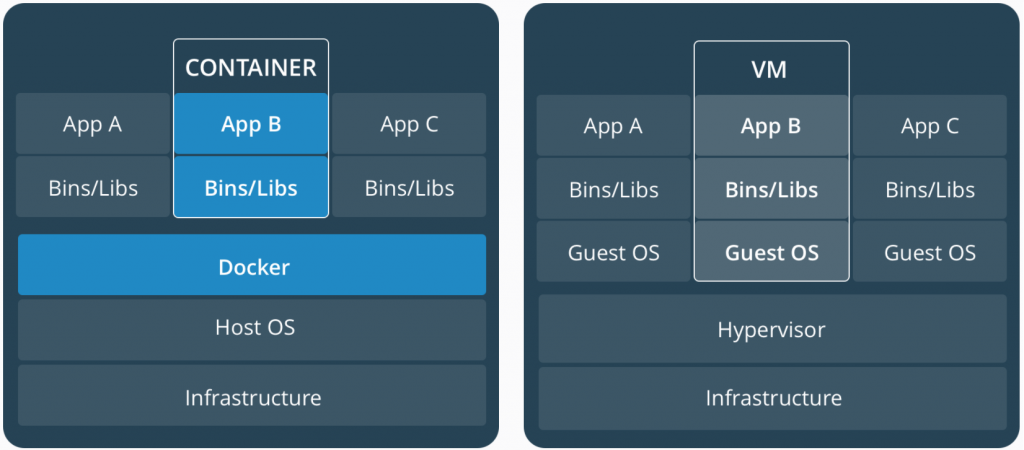
虛擬機與容器最大的差異在於,虛擬機有 Guest Operating System (Guest OS),而容器則無。
相同的資源量,Docker 的利用率更高,可以設定更多的 Containers,且啟動速度更快。
 s790502ss
s790502ss

 iThome鐵人賽
iThome鐵人賽