水平切分的其中一種方式:依資料範圍進行分片。這種方式很直覺,以會員資料為例,將會員依名字首字字母、生日、Id,甚至星座進行分片,再將分片分別存放在不同主機中。因為資料分布可能不平均,像是以 A ~ G 開頭的名字遠比 H ~ N 開頭的名字多,所以分片的範圍不一定是固定的,通常會按照實際資料的數量,希望盡量讓每台主機負擔差不多數量的資料。
| DB | 字母 | 數量 |
|---|---|---|
| 1號 | A~D | 109k |
| 2號 | E~K | 103k |
| 3號 | L~S | 101k |
| 4號 | T~Z | 98k |
理想中,資料的分片會依照數量的增減自動平衡,但這有可能會造成資料被連續搬動,浪費大量資源。例如 T ~ Z 區間的會員人數突然大幅減少剩下 70k,因此 L ~ S 區間將 R ~ S 開頭的資料搬到4號主機,接著因為 L ~ Q 區間的人數也減少了,所以將 J ~ K 開頭的資料搬到3號主機,又因為 E ~ I 區間的人數減少,所以再將 D 開頭的資料搬到2號主機。
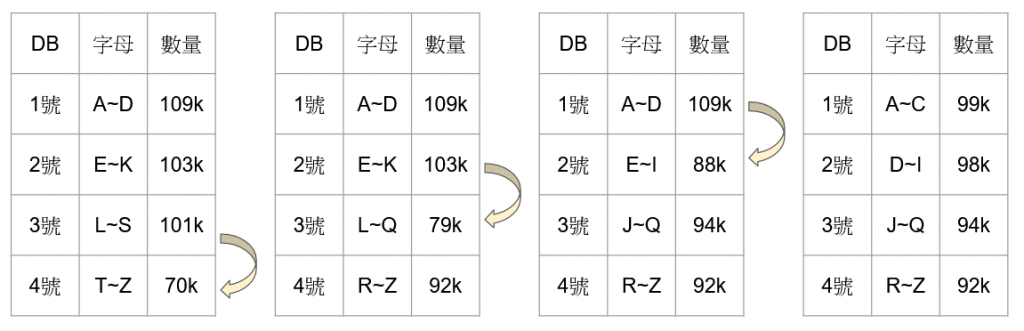
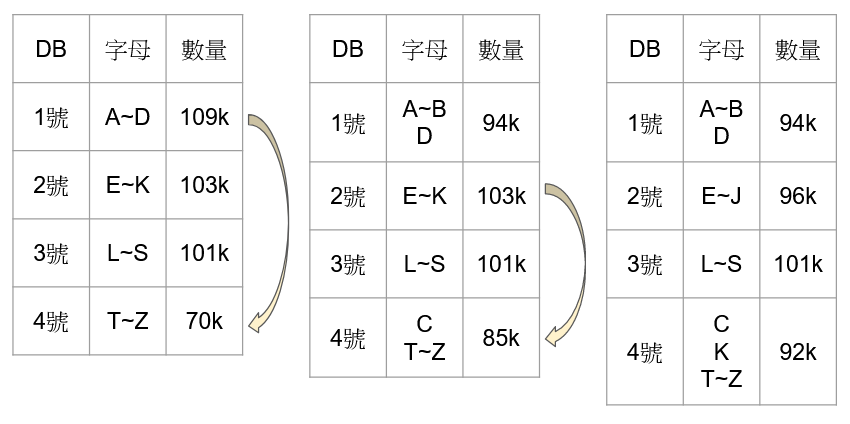
因為這樣連續搬動會造成效能浪費,為了避免這個狀況,儘管是以資料範圍作為切分依據,但每台主機上存放的區間不一定要連續,在這個情境就可以直接從1號主機搬動 C 開頭的資料般到4號主機,再將2號主機 K 開頭的資料搬動到4號主機即可。
前一篇文章有提過,最理想的情況是每一次的查詢都只要讀取一次,不必跨表也不用跨主機,因此依資料範圍切片在選擇欄位時務必考慮到資料性質,以最常用區間查詢的欄位作為切片依據。

