造成遺失值的機制可分為三大類,
完全隨機遺失(missing completely at random, MCAR)
遺失值的產生皆為隨機的
隨機缺失(missing at random, MAR)
遺失值的產生並非完全隨機,但可觀察資料得到有些變數與資料缺失是有相關的。因此當控制這些變數,缺失資料的情形就可視為隨機。
非隨機缺失(missing not at random, MNAR)
遺失值的產生並不隨機。當資料並不是MCAR和MAR時,此情況下的資料缺失並不能忽視,必須進一步確認研究資料為何出現缺失。
若遺失資料被判斷為MNAR時,則變數則會將填入NA;若遺失資料被判斷為MCAR,則可使用以下幾種方法進行處理。
1. 產生具有遺失值的資料
由於資料是完整的,我們選取不同動作的一段加速度資料,並使用function隨機生成NA值
library(missForest)
### 在其中一顆加速度計資料(alx,aly,alz),產生10%的遺漏值
data <- prodNA(dataset2[c(6657:6757,12801:12901,37377:37477),c(1:3)], noNA = 0.1) ###在其中一顆加速度計資料(alx,aly,alz),產生10%的遺漏值
### 合併另一顆加速度資料(arx,ary,arz)
data <- cbind(data,dataset2[c(6657:6757,12801:12901,37377:38377),c(7:9,13)])
choose_data = dataset2.iloc[list(range(6656,6756,1))+list(range(12800,12900,1))+list(range(37376,37476,1)),[0,1,2]]
### 在其中一顆加速度計資料(alx,aly,alz),產生10%的遺漏值
data = choose_data.mask(np.random.random(choose_data.shape) < .1)
### 合併另一顆加速度資料(arx,ary,arz)
data = pd.concat([data, dataset2.iloc[list(range(6656,6756,1))+list(range(12800,12900,1))+list(range(37376,37476,1)),[6,7,8,12]]], axis=1)
data
產生的遺漏值如下:
2.填補資料
(1) 直接移除有遺漏值的資料
R
### complete.case() 會給予bool值,判斷該index是否NA
rm_data <- data[complete.cases(data), ]
Python
rm_data = data.dropna(axis = 0, how = 'any', inplace = False)
rm_data
整理後的資料如下(移除94筆資料,減少了大量的資料,因此不建議此作法)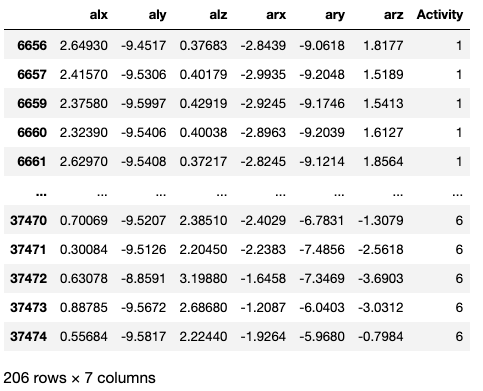
(2) 使用平均值、中位數進行插補
R
### 對於alx進行補值
data$alx[is.na(data$alx)] <- mean(data$alx, na.rm = TRUE)
data$alx[is.na(data$alx)] <- median(data$alx, na.rm = TRUE)
Python
### 對於alx進行補值
data['alx'] = data['alx'].fillna(data['alx'].mean())
data['alx'] = data['alx'].fillna(data['alx'].median())
使用平均數的結果如下:
(3) 使用距離最近的點進行補值
R
library(tidyverse)
data%>%
group_by(Activity) %>% ### 根據Activity 進行分組,分別補值
fill(alx, .direction = "down") ###填補alx
### direction有四個方向
### down: default,向下補值;up: 向上補值;downup: 先向下再向上;updown: 先向上再向下
Python: 參考
data['alz'] = data.groupby('Activity')['alz'].ffill() ###forward fill
data['alz'] = data.groupby('Activity')['alz'].bfill() ### backward fill
Forward fill結果如下: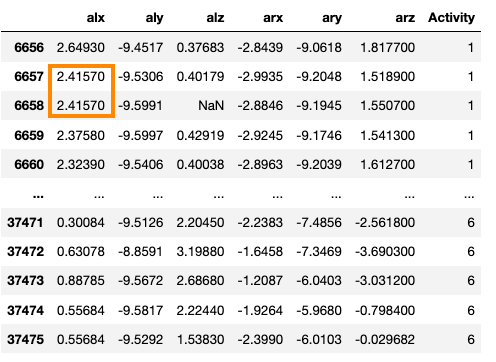
Backward fill結果如下: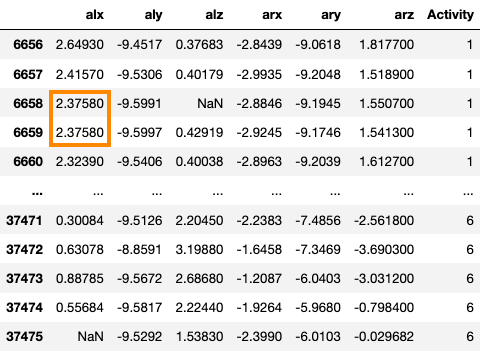
(4) 使用機器學習的方法進行補值
R: 參考
library(simputation)
### 使用CART進行補值,填補alx, aly, alz
data <- impute_cart(data,alx+aly+alz~arx+ary+arz+Activity)
Python
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.neighbors import KNeighborsRegressor
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
#### estimator 可更換成上面import的model
impute = IterativeImputer(estimator=RandomForestRegressor(), random_state=0)
impute.fit(data)
display(pd.DataFrame(impute.transform(data)))
使用Random forest補值的結果如下: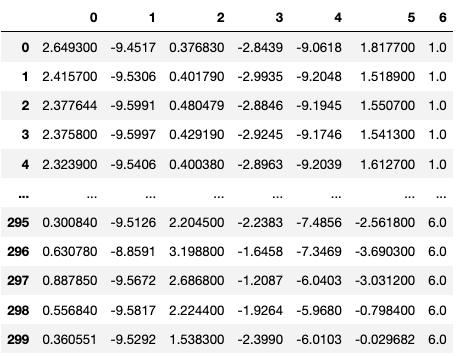


 iThome鐵人賽
iThome鐵人賽