在變數過多時,往往會使用許多不同的特徵選取的方法來選取重要的特徵,機器學習模型中常使用的變數挑選方法為正規化迴歸(Lasso, Ridge, Elastic net)。在深度學習中,可使用一個非監督式學習的類神經網路進行挑選,其結構可以用下面的圖來做範例,整個結構可分為Encoder、Bottleneck、Decoder。
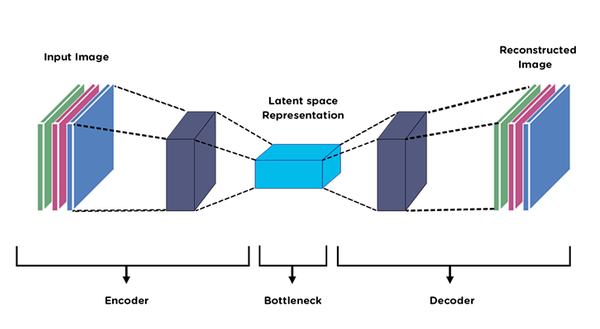
圖片來源:連結
如何衡量Autoencoder的表現?
-> 比較原始資料與還原後的資料之間的相似度,相似度越高,可判斷Autoencoder的表現較好,所選取的特徵向量較有代表性。
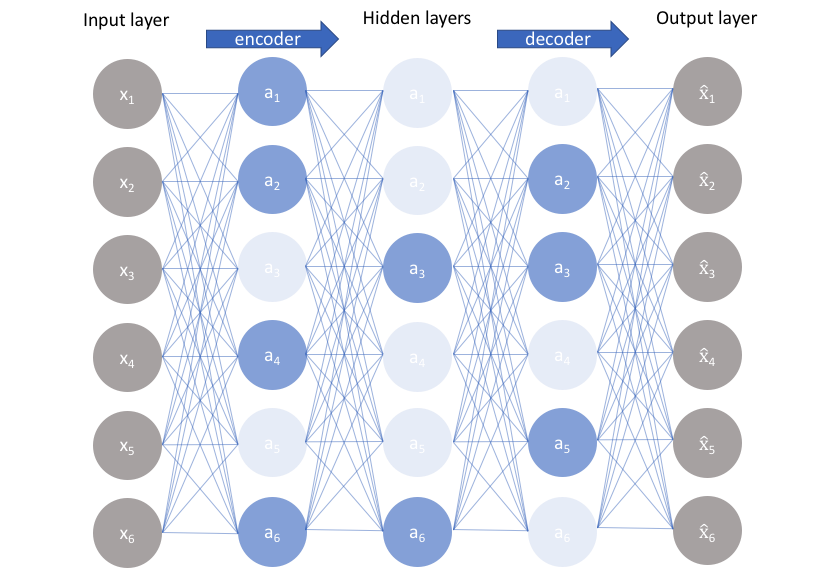
1.** Variational Autoencoder(VAE)**
圖片來源:連結
為Autoencoder的進階版,其架構與Autoencoder相同,最大的差異在於Encoder所產生的結果。在Autoencoder將每筆資料視為獨立,因此Encoder產生的會是一個非連續的向量(One Hot Label),而VAE的Encoder所產生的則是連續數值,期望能夠利用VAE找到資料的分佈情形,因此輸出的則是平均數和變異數。為了要考量encoder輸出包含變異數,因此則會在Loss function內加上限制。
這裡目前列舉兩種,但Autoencoder有更多種類,如:Denoising AE, CNN/LSTM AutoEncoder等。
由於本次實作不考量channel之間的關係,因此將每個channel所產生的時頻圖當作一個樣本,因此建立3維的矩陣儲存資料
### create 3D CNN
gesture = []
segment_store = []
segment_index = [ i for i in range(0,11500,125)]
for segment in range(0,91):
for channel in range(0,64):
freq, times, spectrogram = signal.spectrogram(EMG_total.iloc[segment_index[segement]:segment_index[segement+1],channel], fs=25,nperseg=25)
if channel == 0 and segment == 0:
segment_store = spectrogram
else:
segment_store = np.dstack([segment_store,spectrogram])
gesture.append(EMG_total.iloc[segment_index[segment],64])
data = segment_store # dim = (13, 5, 5824)
gesture = np.array(gesture) # dim = (5824,)
data = np.transpose(data, (2,0,1))
data.shape # dim = (5824, 13, 5)
autoencoder為非監督式學習方法,因此訓練時可選擇使用全部資料集或是部分資料集
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(data, gesture, test_size=0.2)
x_train.shape # dim = (4659, 13, 5)
encoder_input = keras.Input(shape=(13, 5, 1), name='img')
x = keras.layers.Flatten()(encoder_input)
encoder_output = keras.layers.Dense(32, activation="relu")(x)
encoder = keras.Model(encoder_input, encoder_output, name='encoder')
decoder_input = keras.layers.Dense(32, activation="relu")(encoder_output)
x = keras.layers.Dense(65, activation="relu")(decoder_input)
decoder_output = keras.layers.Reshape((13, 5, 1))(x)
opt = tf.keras.optimizers.Adam(lr=0.001, decay=1e-6)
autoencoder = keras.Model(encoder_input, decoder_output, name='autoencoder')
autoencoder.summary()
autoencoder.compile(optimizer='adam', loss='categorical_crossentropy')

history = autoencoder.fit(
x_train, x_train,
epochs=100,
batch_size=250, validation_split=0.10)

使用encoder所計算的feature當作資料的新的feature,利用K-Means進行分群
x_test_encoded = encoder.predict(x_test)
from sklearn import cluster
from sklearn import metrics
# KMeans 演算法
pred_kmean = cluster.KMeans(n_clusters = 4,algorithm="elkan")
pred_kmean.fit_predict(x_test_encoded)
pred_labels = pred_kmean.labels_
print(metrics.classification_report(pred_labels, y_test))
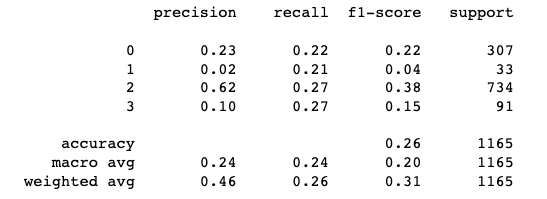
本次實作僅提供概念上的實作,根據分群結果,其實結果並不理想。可能的原因在於不同channel的數值差異較大,因此需將這個部分納入考量,或是可使用更加複雜的autoencoder結構來改善。


 iThome鐵人賽
iThome鐵人賽