前言:網站是由許多網頁所構成,裡面有很多文字、圖片、超連結、表格等等,因此,爬網前確認資料存放的網頁及網址的組成,以下本次爬蟲說明。
- 目標網站:Goodinfo!台灣股市資訊網
- 股票代號:2330
- 目標欄位:
年度
股本 (億)
財報 評分
收盤
平均
漲跌
漲跌 (%)
營業收入
營業毛利
營業利益
稅後淨利
營業毛利
營業利益
業外損益
稅後淨利
ROE (%)
ROA (%)
稅後 EPS
年增 (元)
BPS (元)
step1: 進到goodinfo首頁
step2: 輸入股票代號
step3: 點「經營績效」,可查得歷史收盤價(以年來看)。
爬蟲 goodinfo
使用requests 模組,觀察該URL最後有一參數STOCK_ID,帶入本次所抓的股票代號(2330)即可。
import requests
url = "https://goodinfo.tw/StockInfo/StockBzPerformance.asp?STOCK_ID=2330"
res = requests.get(url)
res.text
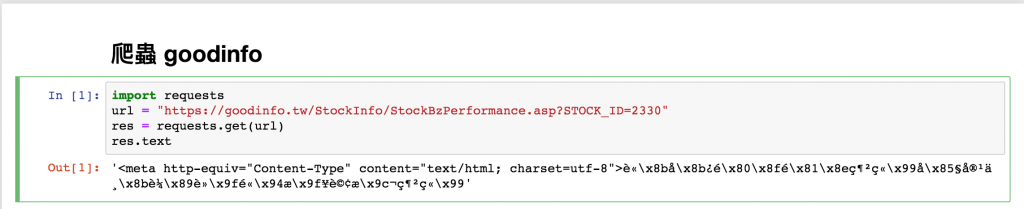
從上圖可以看一堆亂碼,可知該網址出現編碼問題,導致中文無法顯示。
設定編碼
Response 常用的屬性及說明
- url:資源的 URL 位址。
- content:回應訊息的內容 ( bytes )。
- text:回應訊息的內容字串 ( str )。
- raw:原始回應訊息串流 ( bytes )。
- status_code:回應的狀態 ( int )。
- encoding:回應訊息的編碼。
- headers:回應訊息的標頭 ( dict )。
- cookies:回應訊息的 cookies ( dict )。
- history:請求歷史 ( list )。
- json():將回應訊息進行 JSON 解碼後回傳 ( dict )。
- rasise_for_status():檢查是否有例外發生,如果有就拋出例外。
res.encoding = "utf-8"
res.text

開心不再有亂碼了,不過顯示『請勿透過網站內容下載軟體查詢本網站』。

