接續上一篇[股價預測篇-爬蟲part2(金融類)],這篇教大家如何設定使用者代理,爬到所需的數據(收盤價)。
1.開啟上篇的url,在頁面按右鍵,進入檢查。
2.點Network > 重新整理頁面,輸入網頁上任一要爬的關鍵字(如「2021」) > 搜尋,
3.選一個搜尋到的結果,點Headers,往下滑找到user-agent,複製後面那段(如下圖)『Mozilla.....』
(小技巧:直接在網址欄輸入about:version,裡面有使用者代理程式可以複製拉!!)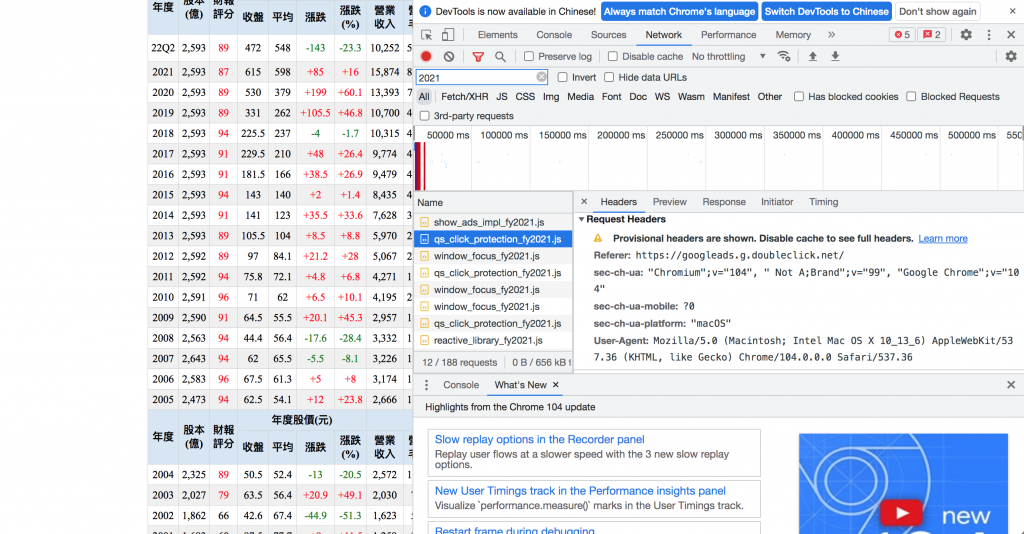
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
}
res = requests.get(url,headers = headers)
res.encoding = "utf-8"
res.text
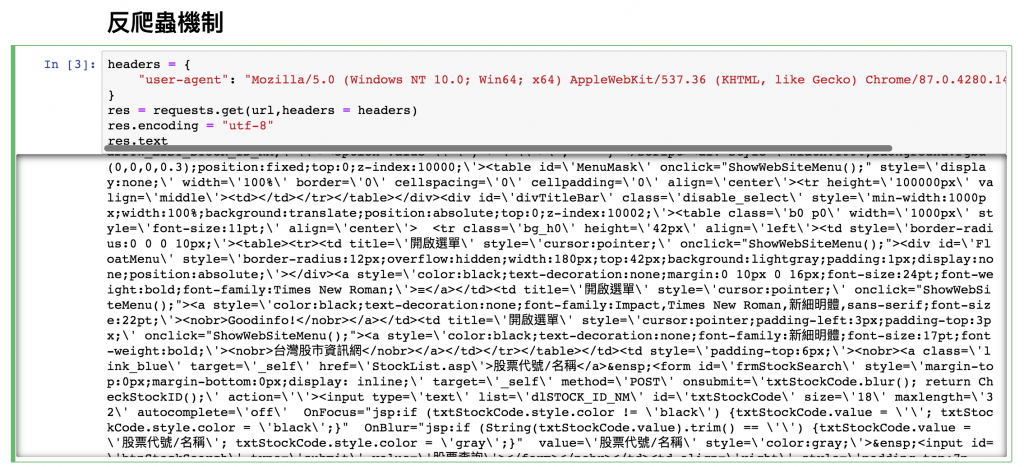
耶~~~可以到網頁的所有資料了。
繼續縮小我們要爬取的收盤價,只針對特定表格元素去爬取。

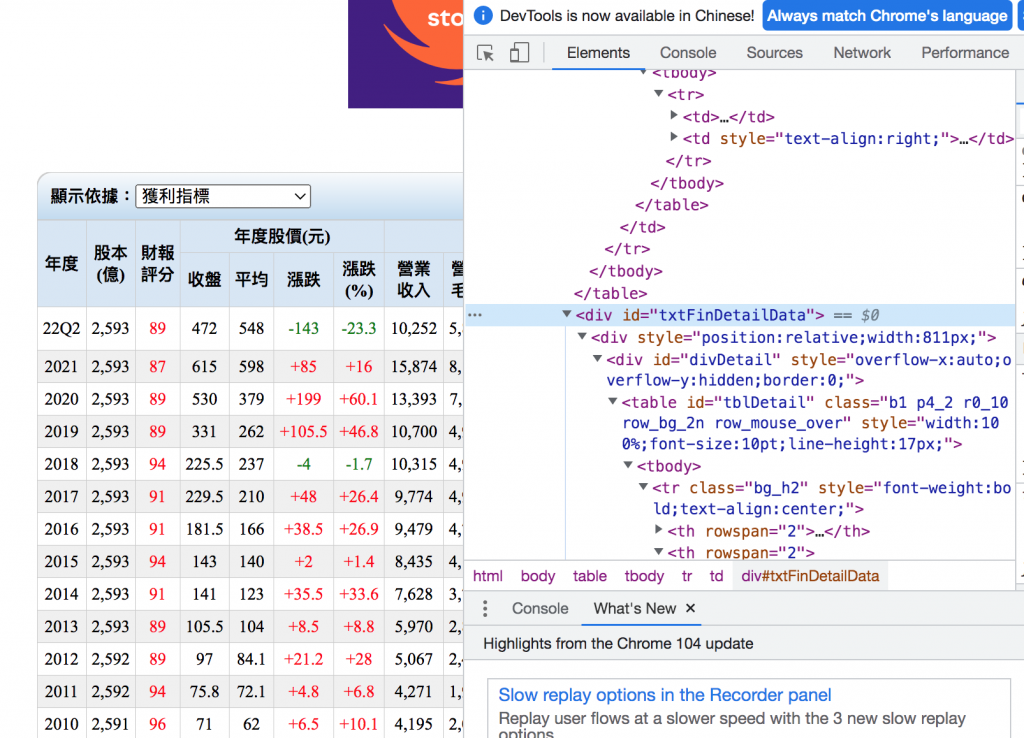
from bs4 import BeautifulSoup
soup = BeautifulSoup(res.text,"lxml")
data = soup.select_one("#txtFinDetailData")
data
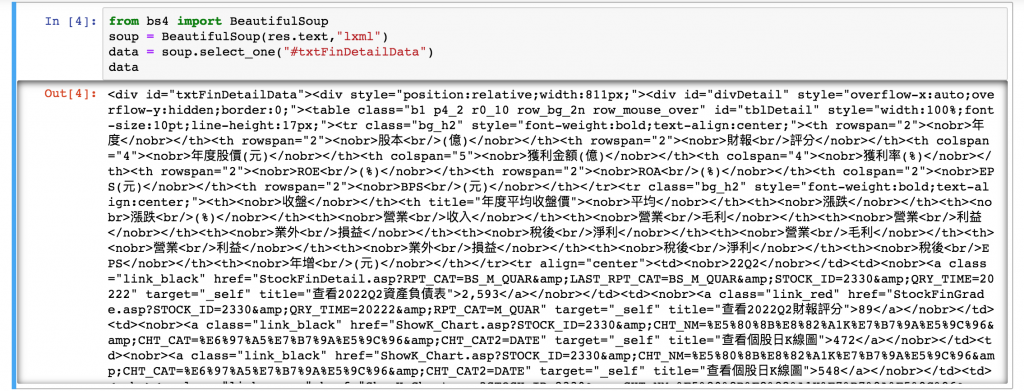
有沒有比較像了!
import pandas as pd
dfs = pd.read_html(data.prettify())
df = dfs[0]
df
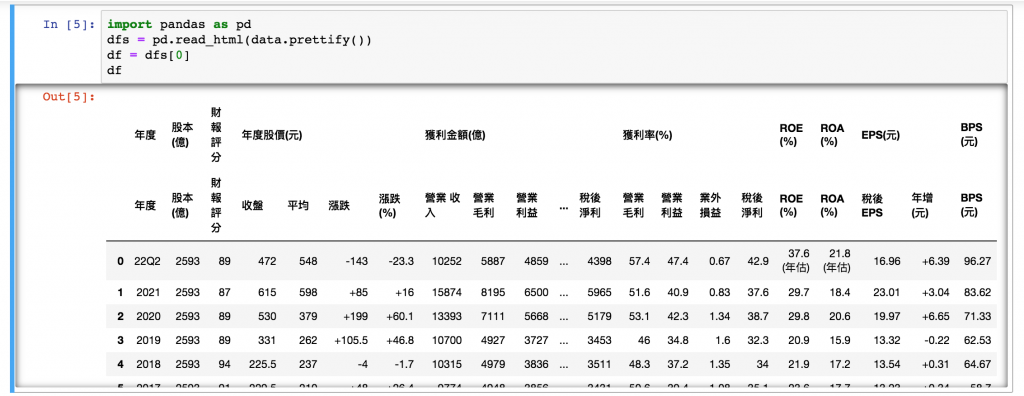
把html的資料變dataframe,有看到收盤價了!!!!

