從前一天的文章(Day 02-如何用一個晚上的時間復刻出 Netflix 的「類似影片」功能?)裡面,我們知道要做出「類似影片」的功能,就要找出任兩部影片之間的相似度,再利用相似度的數值做排序,找出最像的影片推薦給使用者。
相似度這個詞非常的模糊,身為人類的我們可以隱隱約約的知道什麼東西跟什麼東西像。但是就算是我們把影片資訊轉換成向量,那到底相似度的計算邏輯是什麼?我們可以怎麼樣用現成的工具來計算相似度呢?
一個蛋糕不見的故事,剛好可以來說明這一件事情。
今天早上起來發現我的蛋糕被偷吃了。還好昨晚有目擊者看到有人從冰箱裡拿走了我的蛋糕。
據目擊者的描述,嫌犯是一個眼睛大、臉圓、長尾巴的傢伙。
很快的,我們就鎖定3個嫌疑犯,分別是 Hello Kitty、Pikachu 和 Sonic,每個都很可疑,但每個都說不是他。

我們把目擊者看到的人稱作嫌犯X好了。
把他的眼睛、大臉圓、長尾巴的程度都標成 1.0 。然後也幫 3 個嫌犯,測定特徵的程度。如此,每一個人的特徵向量都被做出來了。如下表所示:
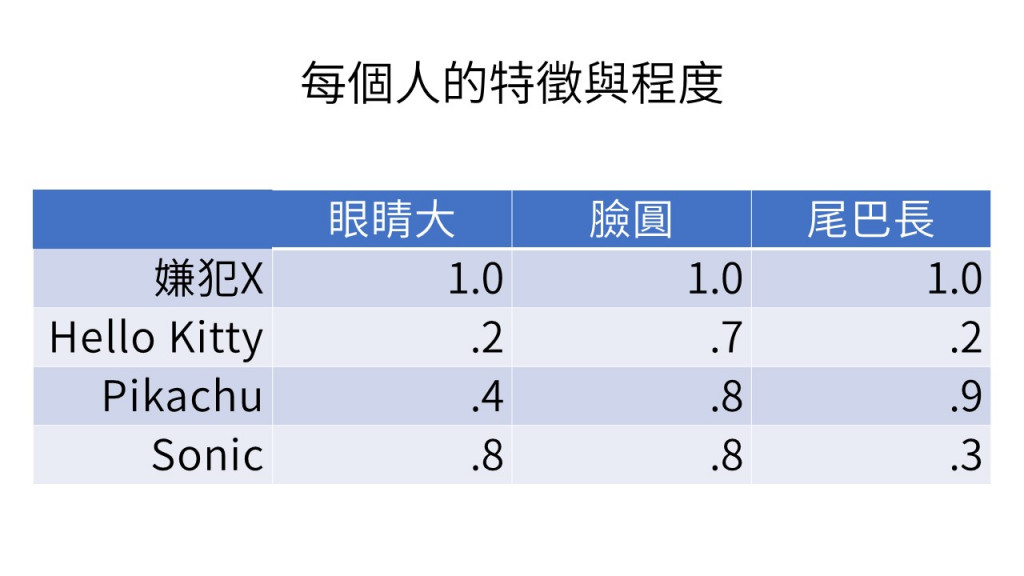
現在只要能夠算出誰和X最像,誰就最有可能是偷吃我蛋糕的傢伙。
這裡介紹兩種相似度的算法。
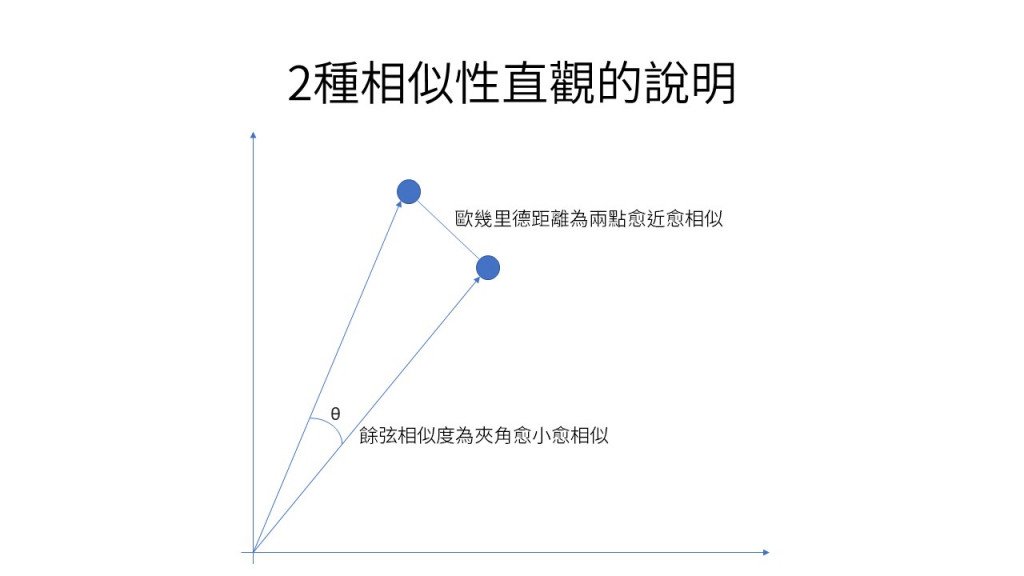
就是計算兩點間直線距離。
這應該是最直覺的相似度算法,就把每一個向量當成是空間上的一個點,計算每個點之間的直線距離,越近的就越相似,也就是越趨近於零的就是越相似。
致於怎麼計算兩個點之間的距離,應該不用我再多說!真的要看的話,可以參考這邊。
餘弦相似度,簡單來說就是去計算每個向量之間的夾角大小,夾角越小的就相當於是越相似。
這種用在文件的相似性比較上效果較佳,至於它的計算公式也請看這邊。
計算相似度是一個非常常見的事情,很多的機器學習工具都有提供。以下我們使用 sklearn ,來示範怎麼樣計算相似度?
from sklearn.metrics.pairwise import euclidean_distances, cosine_similarity
# 每個人的特徵向量
x = [1.0, 1.0, 1.0] # 嫌犯 X 的特徵
kitty = [ .2, .7, .2] # kitty 的特徵
pikachu = [ .4, .8, .9] # 皮卡丘 的特徵
sonic = [ .8, .8, .3] # 索尼克 的特徵
# 把特徵向量集合成一個串列,好讓 sklearn 方便直接計算任兩個向量間的相似度
feature_vectors = [x, kitty, pikachu, sonic] #
print("Feature vectors:")
print(feature_vectors)
print()
# 計算任兩個向量間的歐幾里德距離
print("Euclidean distances:")
distances_similarity_metrix = euclidean_distances(feature_vectors)
print(distances_similarity_metrix)
print()
# 計算任兩個向量間的餘弦相似度
print("Cosine similarity:")
cosine_similarity_metrix = cosine_similarity(feature_vectors)
print(cosine_similarity_metrix)
print()
只要這個程式執行下去,到底誰是犯人我們馬上就知道了。必定是和嫌犯X餘弦相似度最高的或者是歐幾里德距離裡面最小的。
以下是執行結果:
Feature vectors:
[[1.0, 1.0, 1.0], [0.2, 0.7, 0.2], [0.4, 0.8, 0.9], [0.8, 0.8, 0.3]]
Euclidean distances:
[[0. 1.17046999 0.64031242 0.75498344]
[1.17046999 0. 0.73484692 0.6164414 ]
[0.64031242 0.73484692 0. 0.72111026]
[0.75498344 0.6164414 0.72111026 0. ]]
Cosine similarity:
[[1. 0.84119102 0.95553309 0.93720088]
[0.84119102 1. 0.85597974 0.882667 ]
[0.95553309 0.85597974 1. 0.82819364]
[0.93720088 0.882667 0.82819364 1. ]]
這個結果必須要解釋一下。我第一次看的時候也研究了一下,才發現怎麼看?
我用下圖解釋

由這兩個執行結果,我們可以發現皮卡丘跟嫌犯X的距離最短(0.64031242),在餘弦相似性分數又最高(0.95553309),所以事情的真相只有一個:
蛋糕是被皮卡丘吃掉的
今天我們用了一個小故事來說明表示什麼叫做特徵向量,也用 sklearn 示範如何計算向量之間的相似性。
下一篇我會解釋要怎麼樣把電影資料轉成特徵向量,會用到如何分詞、萃取特徵等等,感興趣的朋友別忘記明天再來看囉。


 iThome鐵人賽
iThome鐵人賽