今天我們來用基於內容過濾(Content Based Filtering)的推薦,來復刻版像 Netflix 的類似影片功能,然後來看看我們與 Netflix 的距離 ... 有多大 XD
要推薦一部好電影,要從哪裡開始呢?
如果有人喜歡某部影片,那和這部影片「很像」的影片是不是也有可能會喜歡?
這是非常直覺的想法,過去在百事達,都可以請店員的推薦。但現在連百事達全世界只剩一間,沒有店員可以問,那我們能不能用 AI 找出相關影片來推薦呢?
我已實作了第一版的推薦系統,我稱他為復刻版,我們來比較我們和 Netflix 的差別吧!
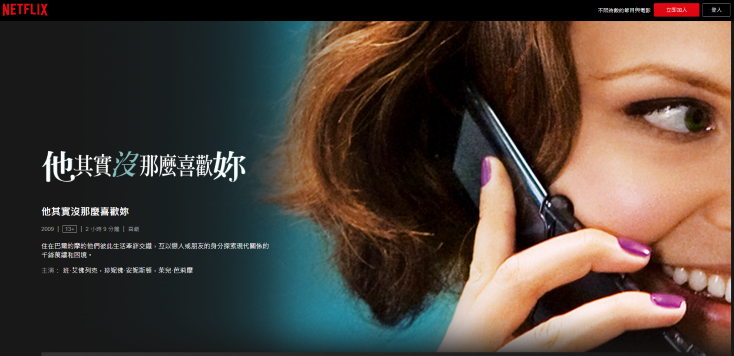
主要是敘述九個俊男美女陷入錯綜複雜的愛情蜘蛛網,究竟這九個人會怎樣面對自己的情感?怎樣抉擇自己的終身?又是否能夠有情人終成眷屬呢?
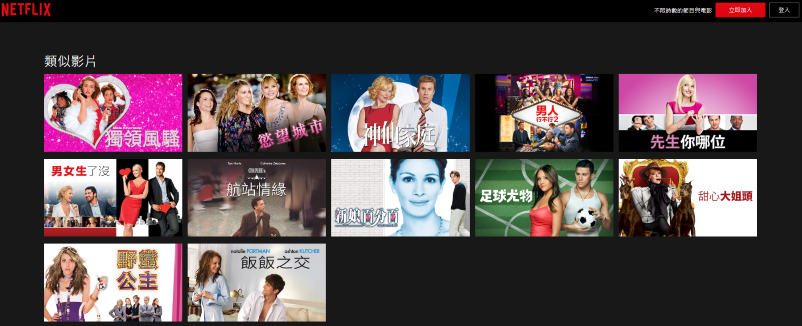
Netflix 推薦的都是愛情喜劇,也算是和「他其實沒那麼喜歡妳」對得上。
我們的復刻版,沒有一部片子和 Netflix 推薦的相同,不過除了藥命關係和非法制裁外,都還算說得過去。
看來我們的復刻版還有要調的地方。

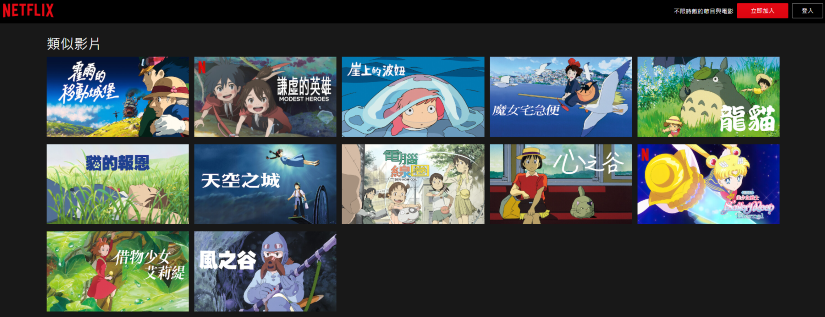
除了龍貓外,兩邊沒有相同的影片。Netflix 推的大都是吉卜力的動畫。而我們雖然不都是吉卜力,但也起碼都是溫馨的動畫電影,看起來也不算跑題。
以一個晚上就做出來的復刻版而言,這樣的效果還不錯,未來再做些調整,看來就是可以用了!
未來幾天會開分享我怎麼做的。
(一個晚上當然不含寫爬蟲,影片資料都是我之前準備好的,資料來源是 yahoo 電影。)
我們這次使用的是基於內容的過濾(Content Based Filtering)來製作類似影片。
這種方法是假設使用者若對目前的影片有興趣的話,那他應會對有類似元素的影片也會有興趣。
除非他手殘不小心按到,否則他按進來一定有理由,只要有理由進來,那推薦成功的機會就大大增加。
這種做法簡單、直覺、可解䆁性強、需要資料不多又容易實作,效果也不錯,所以使用非常的廣泛。
它的想法是這樣的:如果我有1萬部電影,只要我能知道每一部電影和其它部「有多像」,那當使用者選其中一部時,就把最像它的前 N 部拿出來給他挑,總有一部他有興趣吧!
這也就是說,若我可以準備一個類似以下的矩陣,每個矩陣內的值就是任2部電影間的相似度,只要針對某個電影,依相似度排序,我們就能夠做出相似影片的推薦了。
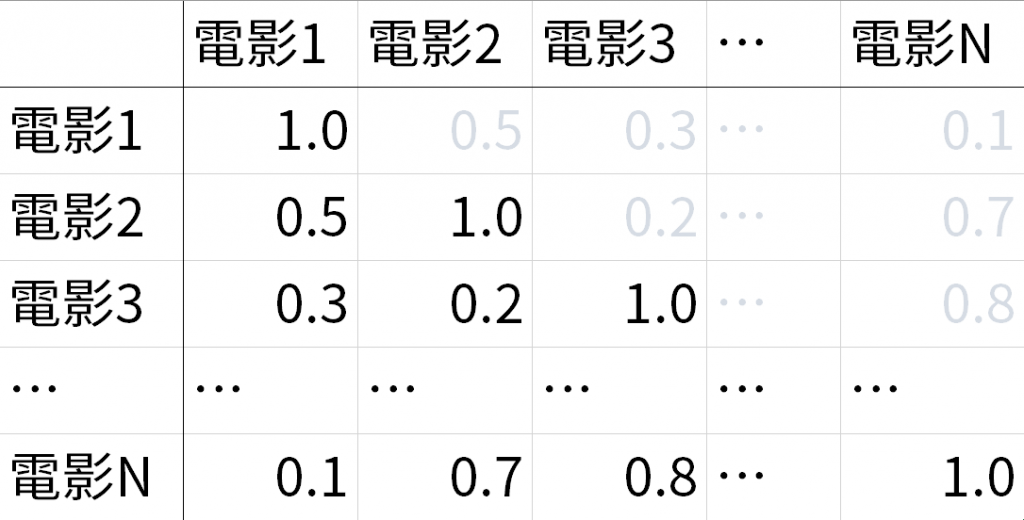
目前已有很多技術可以告訴我們兩個東西之間「有多像」,只要任選一種技術,填入相似矩陣裡就好了。
那兩部影片之間「有多像」,要怎麼計算呢?
最簡單方法就是:把影片都變成相同維度的向量,再計算兩個向量之間的相似度。
只要能把東西變成向量,這世界已經存在大量的手法可以計算出 2 個向量之間「有多像」。常用的有 Consine Similarity、Jaccard Similarity等,實作出來不滿意,再換一個就好。
那剩下的問題就是:怎麼把電影的資料轉成向量呢?
其實這裡的向量,就叫做特徵向量,找出特徵向量的行為,我們會稱為「特徵工程」。
當拿到特徵向量後,我們就可以用這個特徵向量表達這個電影有什麼特色,是和別的電影有何不同。
在我們的復刻版裡,我們是把和這電影有關的劇情大綱、得過的獎項、導演、演員等等資料集合起來成一篇文件。然後再把文件轉轉特徵向量,常見的做法會有詞頻法、tf-idf、word2vec 等。
就因為能把「特徵向量」找到,也決定了「相似度」的計算法式,所以相似度矩陣即可立馬算出來。
今天給大家看了復刻版的成果,也向大家說明了我是如何用基於內容的過濾法來「類似影片」功能。
接下來的幾天,我會和大家介紹說明電影內容要怎麼「向量化」以及向量間「有多像」有哪些方法。最後這些技術是怎麼結合起來做出「類似影片」的。
就請大家繼續看下去。


 iThome鐵人賽
iThome鐵人賽