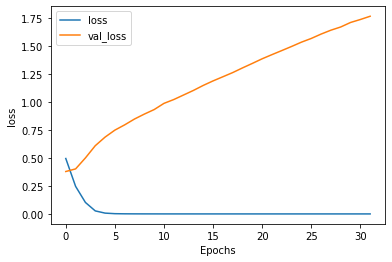
繼續昨天的例子,我們觀察在訓練過程中的loss和accuracy,可以看到訓練的accuracy已經到達1,但測試的accuracy呈現水平,而訓練的loss趨近於0,但測試的loss卻逐漸升高,又是一個熟悉的overfitting的樣子: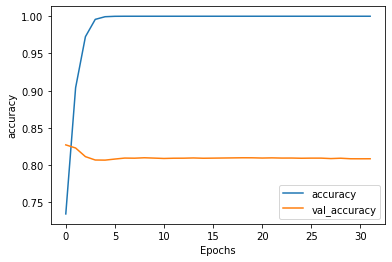
我們回去看前一天的例子,如果還記得,總共有29657個詞,26709個句子,其中最長的句子有40個詞,我們先設定到10000個單字量和每個句子最長32個字,另外將20000句子當訓練用,剩餘當測試用:
# Number of examples to use for training
training_size = 20000
# Vocabulary size of the tokenizer
vocab_size = 10000
# Maximum length of the padded sequences
max_length = 32
# Output dimensions of the Embedding layer
embedding_dim = 16
# Split the sentences
training_sentences = sentences[0:training_size]
testing_sentences = sentences[training_size:]
# Split the labels
training_labels = labels[0:training_size]
testing_labels = labels[training_size:]
import numpy as np
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# Parameters for padding and OOV tokens
trunc_type='post'
padding_type='post'
oov_tok = "<OOV>"
# Initialize the Tokenizer class
tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok)
# Generate the word index dictionary
tokenizer.fit_on_texts(training_sentences)
word_index = tokenizer.word_index
# Generate and pad the training sequences
training_sequences = tokenizer.texts_to_sequences(training_sentences)
training_padded = pad_sequences(training_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
# Generate and pad the testing sequences
testing_sequences = tokenizer.texts_to_sequences(testing_sentences)
testing_padded = pad_sequences(testing_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
# Convert the labels lists into numpy arrays
training_labels = np.array(training_labels)
testing_labels = np.array(testing_labels)
import tensorflow as tf
# Build the model
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
可以看到loss和accuracy也是有同樣的病徵,甚至測試的accuracy是下降的: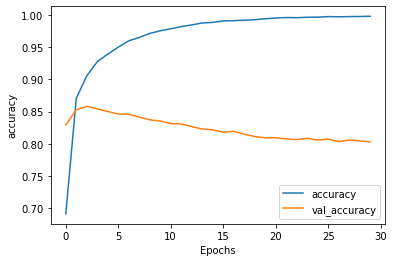
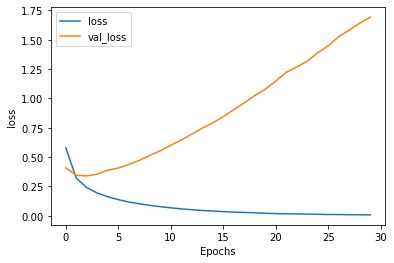
但如果我們將單字量設定到1000而句子最長只有16個字,可以看到測試的loss是持平的: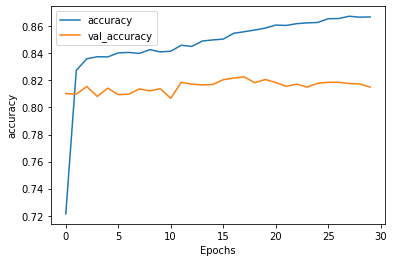
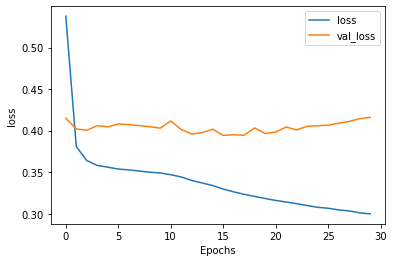
所以可以假設是因為太多字眼反而會影響測試的判斷?
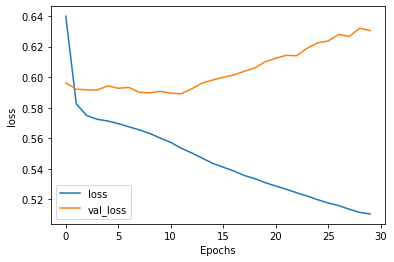
回到昨天的例子,我們用相同的設定,與相同的模型,也可看到類似的轉變,但loss和accuracy的水平都變差了,這需要多試幾次來調整。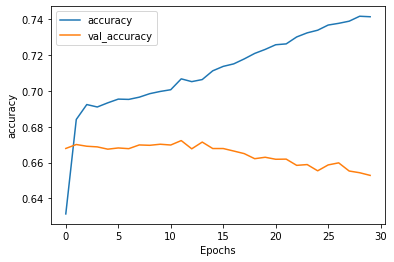


 iThome鐵人賽
iThome鐵人賽