昨天註冊好了環境,今天終於可以正式踏入強化學習的部分了。stable-baselines3是一個很好用的模組,接下來我就來向各位介紹這個模組吧!
stable-baselines3是集合了很多強化學習演算法的一個模組,演算法是使用pytorch建立的。它的優點有以下:
1.所有演算法都擁有一個統一結構
2.高程式碼覆蓋率和許多類型的提示
3.程式碼編排整齊清潔,相當容易閱讀。
這幾點使得我在使用上都很得心應手,除了模組本身以外,RL Baselines3 Zoo也提供了一組預訓練代理、用於訓練、評估代理、調整超參數、繪製結果和錄製影片的功能。連結會放在下面。另外此模組也有擴充功能stable-baselines3 Contrib,這個擴充功能大致上是用來測試一些實驗性強化學習程式碼以及一些最新的演算法,不過這個擴充功能我比較少使用到。
官方文檔中有非常多的教學,以及建議,甚至也有其他強化學習的資源。要介紹真的介紹不完,各位也可以治官方文檔中尋寶。去找吧,我把網址都放在文章最底下了!
模組中提供的演算法如下:
以下演算法在stable-baselines3 Contrib中,各位也可以去試試看。
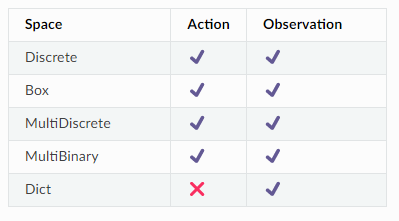
這次專案中我們會用PPO,文檔內有說明PPO的動作空間跟觀察空間可以使用的類型,參考以下表格可看到除了在動作空間中使用Dict以外其他都是被允許的。
接下來我們要來安裝了,在終端機輸入以下兩個來安裝pytorch跟stable-baselines3
pip install torch
pip install stable-baselines3
今天介紹了stable-baselines3這個好用的模組,明天會帶大家跑一次他所提供的範例,讓各位可以看看他實際訓練的情況是如何。同時也會介紹演算法中的一些常用的超參數。各位也可以先去逛逛官方文檔。我們明天見!
stable-baselines3官方文檔
stable-baselines3的訓練框架
stable-baselines3 Contrib

