今天會帶大家來看看我們的觀察值的區間,通常可以算出來的話就會直接算出最大最小值,不過如果沒辦法計算的話,通常我就會不斷紀錄每一step的觀察值並決定區間要落在哪,另外隸屬函數我也會設定每一個觀察值都有一組。今天會使用Triangular mf,明天會使用GeneralizedBell_mf。
我們的專案總共用到7個觀察值,我會分別列出來。
1.R2D2的x座標:最小值設定在-4.5,最大值設定在4.5
2.R2D2的y座標:最小值設定在-4.5,最大值設定在4.5
3.目標點x座標:最小值設定在0,最大值設定在2
4.目標點y座標:最小值設定在-2,最大值設定在2
5.R2D2跟目標點的距離:最小值設定在0,最大值設定在5
6.R2D2的方向:最小值是-pi/2,最大值是2pi/3
7.目標點的方向:最小值是-pi/2,最大值是pi/2
令我有點意外的是R2D2的方向,還好有把所有觀察到的值再拿出來檢查才能發現程式中回傳的值是長這樣。既然觀察值的最大最小值都找好了以後就可以來設計隸屬函數了,這次我打算用一個最大最小值,每個觀察值的隸屬函數比例都是一樣的,只有定義域的不同而已。
我打算將隸屬函數切成相等的四等分,所以兩條黑色垂直邊應該為最大值跟最小值的1/4處跟3/4處,正中間就是一半,比例設定好了我們就可以直接來撰寫程式了。老話一句,這種設定沒有絕對,也可以將黑色垂直邊設定為最大值跟最小值的1/5處跟4/5處等等。
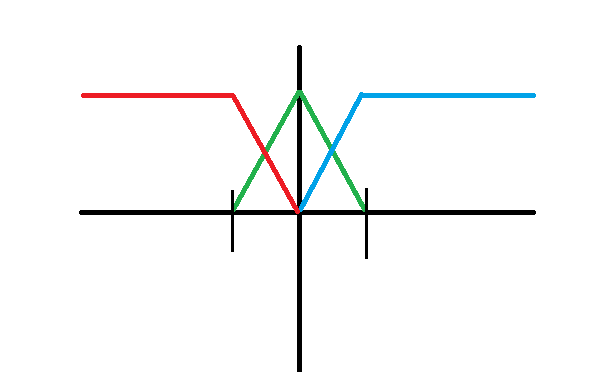
程式如下:我打算將九個觀察值都送進此副程式然後透過迴圈一個一個處理,最後輸出為21個值,值的區間落在0~1。要記得改觀察空間喔!
fuzzy_obs是7個觀察值,每個觀察值會模糊化成三個變量
d1、d2、d3是將隸屬函數分段後的結果,看觀察值落在哪個區間就去進行那個區間的運算,並且直接更改fuzzy_obs的值,可以參考註解跟上圖來幫助理解喔。接下來送入的參數obs, min_obs, max_obs分別是將7個觀察值、觀察值最大值、觀察值最小值直接送入,所以會輸入三個長度為9的陣列,輸出一個長度為21的陣列(fuzzy_obs.flatten()會將7*3陣列展平成長度為21的陣列)。
self是因為要放在環境的類別中,故加上去。
def triangular_mf(self, obs, min_obs, max_obs):
fuzzy_obs = np.zeros(shape=(7,3))
for i in range(len(obs)):
d1 = min_obs[i] + (max_obs[i] - min_obs[i]) * 3/4
d2 = (max_obs[i] + min_obs[i]) * 1 / 2
d3 = min_obs[i] + (max_obs[i] - min_obs[i]) * 1/4
print(d1,d2,d3)
if obs[i] <= d1:#最左邊紅色部分
fuzzy_obs[i][0] = 1
fuzzy_obs[i][1] = 0
fuzzy_obs[i][2] = 0
elif (obs[i] > d1 and obs[i] <= d2):#紅色線降低且綠色線升高的部分
fuzzy_obs[i][0] = (obs[i] - d2) / (d1 - d2)
fuzzy_obs[i][1] = (obs[i] - d1) / (d2 - d1)
fuzzy_obs[i][2] = 0
elif (obs[i] > d2 and obs[i] <= d3):#綠色線降低且藍色線升高的部分
fuzzy_obs[i][0] = 0
fuzzy_obs[i][1] = (obs[i] - d3) / (d2 - d3)
fuzzy_obs[i][2] = (obs[i] - d2) / (d3 - d2)
elif (obs[i] > d3):#最右邊藍色線部分
fuzzy_obs[i][0] = 0
fuzzy_obs[i][1] = 0
fuzzy_obs[i][2] = 1
return fuzzy_obs.flatten()
接下來就要來改寫環境啦!我們將這個副程式放在環境中任一個你喜歡的地方,接著改掉obs的部分跟觀察空間後就可以開始訓練啦,首先先把觀察值的最大最小值加入到__init__(self)中,接著更改觀察空間。
self.min_obs = [-4.5, -4.5, 0, -2, 0, -np.pi / 2, -np.pi / 2]
self.max_obs = [4.5, 4.5, 2, 2, 5, 3 * np.pi / 2, np.pi / 2]
self.observation_space = spaces.Box(low=0,high=1,shape=(21, ), dtype=np.float32)
接著來改get_obs(self)方法,只需要在最後面加上我們自己設定的副程式就好了。
obs = self.triangular_mf(obs=obs,min_obs=self.min_obs,max_obs=self.max_obs)
接下來就直接訓練吧,訓練的程式碼不用改變。
環境的完整程式碼:
import gym
import pybullet as p
from gym import spaces
import numpy as np
from src import Plane,R2D2,Target,Wall
class R2D2Walking(gym.Env):
def __init__(self):
physicsClient = p.connect(p.GUI)
p.setGravity(0, 0, -9.8)
p.setRealTimeSimulation(1)
Plane()
Wall()
low_action = np.array([-10, -10, -10, -10],dtype=np.float32)
high_action = np.array([10, 10, 10, 10],dtype=np.float32)
self.action_space = spaces.Box(low=low_action,high=high_action)
self.min_obs = [-4.5, -4.5, 0, -2, 0, -np.pi / 2, -np.pi / 2]
self.max_obs = [4.5, 4.5, 2, 2, 5, 3 * np.pi / 2, np.pi / 2]
self.observation_space = spaces.Box(low=0,high=1,shape=(21, ), dtype=np.float32)
self.r2d2 = R2D2()
self.target=Target()
self.targetpos=None
self.hitRayColor = [1, 0, 1]
self.missRayColor = [0, 1, 0]
self.rayFroms = None
self.rayTos = None
self.rewardlst = []
self.timesteps = 0
self.testtime = 0
self.successtime = 0
self.ori=[]
def step(self, action):
self.timesteps += 1
action *= 10
self.r2d2.move(action[0],action[1],action[2],action[3])#rf,rb,lf,lb
obs = self.get_obs()
reward=self.get_reward()
self.done = self.rz<0.2
if self.rx>4.5 or self.rx<-4.5 or self.ry>4.5 or self.ry<-4.5:
reward -= 2
self.done=True
results = p.rayTestBatch(self.rayFroms, self.rayTos)
p.removeAllUserDebugItems()
for index, result in enumerate(results):
if result[0] != -1:
p.addUserDebugLine(self.rayFroms, self.rayTos, self.hitRayColor)
reward += 5
self.successtime += 1
self.done = True
else:
p.addUserDebugLine(self.rayFroms, self.rayTos, self.missRayColor)
self.rewardlst.append(reward)
if self.timesteps>1000:
reward-=2
self.done=True
return obs, reward, self.done, {}
def reset(self):
self.rewardlst = []
self.timesteps = 0
self.testtime += 1
self.done=False
self.targetpos = self.target.reset_spawn()
self.rayFroms = np.array(self.targetpos, dtype=np.float32)
self.rayTos = np.array(self.targetpos + np.array([0, 0, 1]), dtype=np.float32)
p.resetBasePositionAndOrientation(self.r2d2.r2d2ID,self.r2d2.r2d2StartPos,self.r2d2.r2d2StartOrientation)
obs=self.get_obs()
print(f'[INFO] testtime: {self.testtime}')
print(f'[INFO] successtime: {self.successtime}')
print(f'--------------------------------------')
return obs
def render(self, mode='human', clode=False):
pass
def close(self):
p.disconnect()
def get_obs(self):#r2d2_x,r2d2_y,r2d2_z,target_x,target_y,target_z,dis
left = np.array(p.getLinkState(self.r2d2.r2d2ID, 0)[0])#0,4是左腳右腳關節處 所以要取平均
right = np.array(p.getLinkState(self.r2d2.r2d2ID, 4)[0])
self.rx, self.ry, self.rz = pos = (left+right)/2
dis = np.linalg.norm(pos-self.targetpos)
r2d2_quaternion = p.getBasePositionAndOrientation(self.r2d2.r2d2ID)[1]
self.r2d2_angle = p.getEulerFromQuaternion(r2d2_quaternion)[2] + np.pi / 2
tx, ty, _ = self.targetpos
self.target_angle = np.arctan(ty / tx); # print(f'r2d2:{r2d2_angle},target:{target_angle}')
obs = np.array([self.rx,self.ry,tx,ty])
obs = np.append(obs, dis)
obs = np.append(obs, self.r2d2_angle)
obs = np.append(obs, self.target_angle)
obs = self.triangular_mf(obs=obs,min_obs=self.min_obs,max_obs=self.max_obs)
return obs
def get_reward(self):
pos=self.get_obs()[0:2]
pos_reward = -np.linalg.norm(pos-self.targetpos[0:2])
angle_reward = -abs(self.r2d2_angle-self.target_angle)
return pos_reward+angle_reward
def triangular_mf(self, obs, min_obs, max_obs):
fuzzy_obs = np.zeros(shape=(7, 3))
for i in range(len(obs)):
d1 = min_obs[i] + (max_obs[i] - min_obs[i]) * 3 / 4
d2 = (max_obs[i] + min_obs[i]) * 1 / 2
d3 = min_obs[i] + (max_obs[i] - min_obs[i]) * 1 / 4
if obs[i] <= d1:
fuzzy_obs[i][0] = 1
fuzzy_obs[i][1] = 0
fuzzy_obs[i][2] = 0
elif (obs[i] > d1 and obs[i] <= d2):
fuzzy_obs[i][0] = (obs[i] - d2) / (d1 - d2)
fuzzy_obs[i][1] = (obs[i] - d1) / (d2 - d1)
fuzzy_obs[i][2] = 0
elif (obs[i] > d2 and obs[i] <= d3):
fuzzy_obs[i][0] = 0
fuzzy_obs[i][1] = (obs[i] - d3) / (d2 - d3)
fuzzy_obs[i][2] = (obs[i] - d2) / (d3 - d2)
elif (obs[i] > d3):
fuzzy_obs[i][0] = 0
fuzzy_obs[i][1] = 0
fuzzy_obs[i][2] = 1
return fuzzy_obs.flatten()
雖然模糊控制算是一個相當神秘的領域,此概念也算是比較新穎的概念,今天帶大家實作了triangular_mf,不知道各位有沒有藉此更認識模糊控制跟隸屬函數了。因為此次任務較簡單,所以可能成效不會太過明顯,往後各位有用到強化學習或者在其他領域有需要的話也可以將上述的程式碼改寫一下方便提供給自己使用喔,也不用從頭開始寫了。


 iThome鐵人賽
iThome鐵人賽