一般訓練模型上,都會建議採用 transfer learning ,可以參考 Day 1 的內容實務,可以節省更多的時間和運算資料。但是如果自己重頭訓練模型的時候,就會需要用到極巨大的 dataset。例如說,GPT-2 的 WebText dataset 超過 40 GB,檔案超過 800萬個。這種這麼巨大的資料集,要載入到電腦裡,那麼記憶體會吃不消的。
在 Hugging Face 裡透過 Arrow 和 Stream 兩種機制,讓我們可以有效率的來操作資料,節省記憶體。
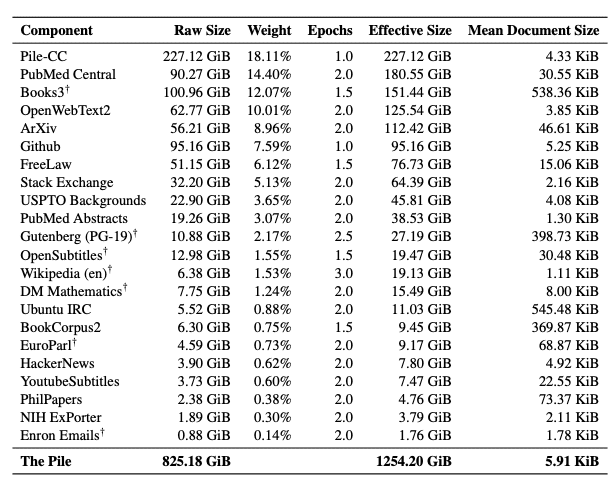
The Pile 是一個高達 800 GB 的 dataset,由 22 個不同的 subsets 所組成的,表格摘錄自論文如下圖。有興趣的朋友可以去看這篇論文。
我們可以去 The Pile 提供的網址下載 dataset。
https://mystic.the-eye.eu/public/AI/pile_preliminary_components/
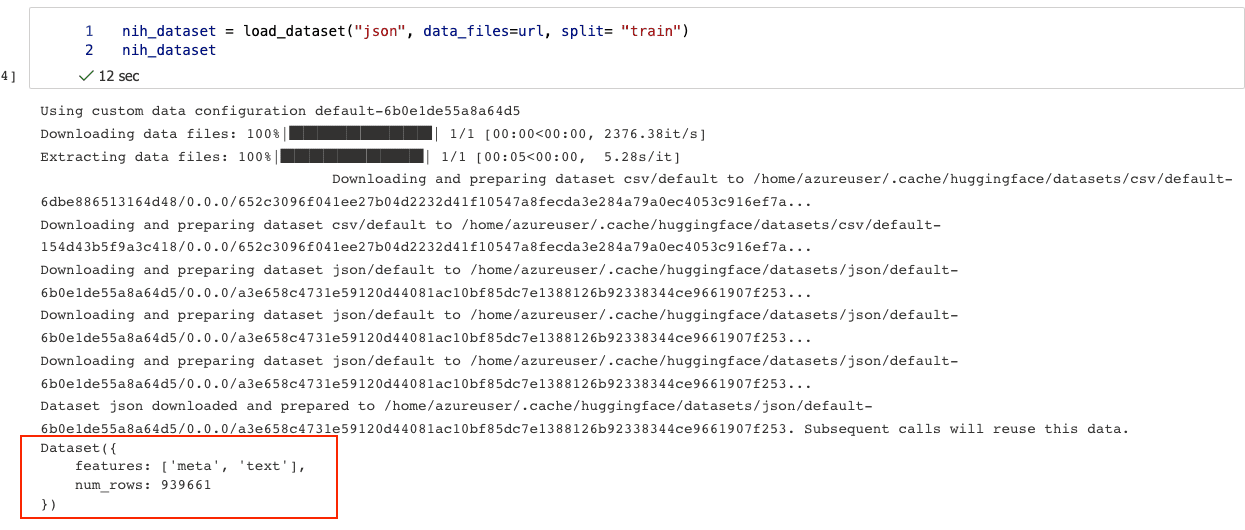
選好你要的 dataset 之後,打開你 Azure Machine Learning 的 Notebook,可以用下面的程式碼載入,我們找一個小一點的、 JSON 格式的dataset,才不會花太久的時間。我們這裡載入 NIH 的 dataset。
from datasets import load_dataset
url = "https://mystic.the-eye.eu/public/AI/pile_preliminary_components/NIH_ExPORTER_awarded_grant_text.jsonl.zst"
nih_dataset = load_dataset("csv", data_files=url, split= "train")
nih_dataset
pip install zstandard 來安裝。

5. 接著我們安裝 psutil,這是可以看記憶體目前消耗量的套件。!pip install psutil
import psutil
print(f"RAM used: {psutil.Process().memory_info().rss / (1024 * 1024):.2f} MB")
print(f"Number of files in dataset : {nih_dataset.dataset_size}")
size_gb = nih_dataset.dataset_size / (1024**3)
print(f"Dataset size (cache file) : {size_gb:.2f} GB")
這裡我們可以看到資料集雖然 1.91 GB 這麼大,但是 RAM 的使用卻沒有這麼大,只有688.48 MB。如下圖。這就是 Hugging Face Dataset 厲害的地方了。它應用了 Apache Arrow 來把資料轉換成 Columnar format 的形式,因此可以用更少的記憶體。詳細的原理可以參考這裡。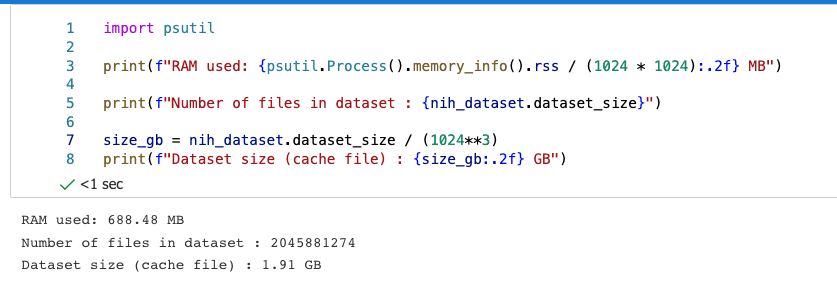
Hugging Face 官方給了這段程式碼,可以讓你測看看這讀資料的效能多好。
import timeit
code_snippet = """batch_size = 1000
for idx in range(0, len(nih_dataset), batch_size):
_ = nih_dataset[idx:idx + batch_size]
"""
time = timeit.timeit(stmt=code_snippet, number=1, globals=globals())
print(
f"Iterated over {len(nih_dataset)} examples (about {size_gb:.1f} GB) in "
f"{time:.1f}s, i.e. {size_gb/time:.3f} GB/s"
)

明天我們就來看 Stream dataset 的部分。

