昨天我們用 Hugging Face 做了QA ,但是大家想必發現了很麻煩的一件事情:每次都要把 context 送進去才行。這真的很麻煩,而且處理 context 的時間,很容易讓使用者不耐。為了解決這類的問題,QA 系統一般發展為 retriever-reader 的架構。
我們給出一個問題,retriever 就會根據這個問題,來搜索相關的文檔。一般分為下面兩種機制。
負責從 retriever 所提供的文檔中提取答案。這部份也可以用 transformers 來扮演這個角色。
大部份都使用 document-oriented 的資料庫, 像是 Elasticsearch 或是其他 In-memory 的儲存方式。傳統的關聯式資料庫很少在這樣的場景做用。
合併來自多個 retriever 的文檔,或是資料流時使用。就是把大家串在一起的方式。
下圖是筆者參考眾多文獻畫出來的架構圖,可以方便大家理解。
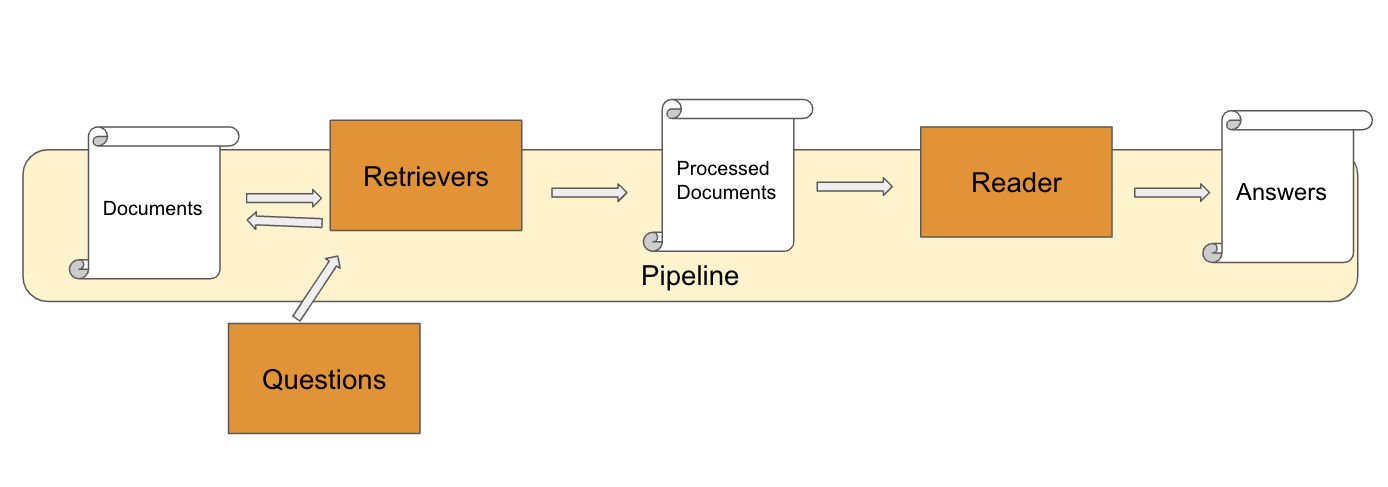
Haystack 是一間全球知名的 NLP 團隊 Deepset 所開發出來的工具,昨天我們使用的 roberta-base-squad2 也是這個團隊所開發出來的。Haystack 可是說是目前建構 QA 系統的主流工具。
因為本次系列主題是講 Hugging Face 因此我們不在 Haystack 的部份著墨太多了,以後有機會再來為 Haystack 寫系列專文。我們可以這個網站試玩 Haystack 和 Hugging Face 的整合。
該網站是基於冰與火之歌的 QA 系統,我們可以輸入問題來問問它。像我就輸入 who is Queen of Meereen, Queen of the Andals and the Rhoynar and the First Men?。它就會檢索冰與火之歌的文本,並且告訴我答案是 Daenerys Targaryen。

