在完成基本的清洗及加工後,我們要來針對每筆資料進行細緻的處理與分類。
在上篇最後,我們將初步處理過的字串用半形空白分割成 splittedStrArr。
首先,讓我們在主流程外面,建立一個 processSplittedStr 的 function 針對以下四個目標來加工分類:
/**
* 處理並判斷是否分割後的字串陣列符合我們想要的格式
* 如果符合,依照格式 push 到 formattedData
* 如果不符合,將原始資料 push 到 exceptions
* @param {string[]} splittedStrArr
*/
const processSplittedStr = (splittedStrArr) => {};
我們需要建立一個 deep copy 來達成資料有任何一筆不符合條件時,就應該原封不動放到 exceptions 中的需求。
因為傳進來的陣列只有一層,並非巢狀結構,所以我們單純透過 sread operator 就可以達到 deep copy 的效果。
const cloneSplittedStrArr = [...splittedStrArr];
同時我們透過另一個陣列 temp 來儲存暫時處理好的結果
const temp = [];
陣列中的第一筆資料一定是時間,所以我們只要取出第一筆後,用 validTimeRegex 的 regular expression 來判斷是否符合時間的格式。
如果是的話,在 temp 中加入小時分鐘的字串,並且在原先傳入的陣列中移除。
如果不是的話,在 exceptions 中 push deep copy 的陣列,並且透過 return 結束這筆資料的加工。
// step 1 判斷小時分鐘
const validTimeRegex = /^(0[0-9]|1[0-9]|2[0-3]):[0-5][0-9]$/;
const time = splittedStrArr[0];
const isValidTime = validTimeRegex.test(time);
if (isValidTime) {
temp.push(time);
splittedStrArr = splittedStrArr.filter((element) => element !== time);
} else {
exceptions.push(cloneSplittedStrArr);
return;
}
然而稍微觀察一下資料,我們無法確認 splittedStrArr 第二筆一定是日期資料。
所以我們要做的是透過 filter() 來篩選出符合 validDateRegex 的 element 作為日期,並且在原先傳入的陣列中移除判該 element。
如果是的話,在 temp 中加入日期,並且在原先傳入的陣列中移除該字串。
如果不是的話,在 exceptions 中 push deep copy 的陣列,並且透過 return 結束這筆資料的加工。
// step 2 判斷日期
const validDateRegex = /^[0-9]{0,2}\/?[0-9]{0,2}$/;
const [date] = splittedStrArr.filter((str) => validDateRegex.test(str));
if (!!date) {
temp.push(date);
splittedStrArr = splittedStrArr.filter((element) => element !== date);
} else {
exceptions.push(cloneSplittedStrArr);
return;
}
大致同上個步驟,不過這個階段要注意的是星期幾的表示可能是全部大寫、全部小寫、大小寫混雜,所以在 regular expression 的 option,要加上 i 啟用 case insensitive(大小寫不影響)。
// step 3 判斷星期幾
const validCaseInsensitiveWeekDayRegex = /(?:sat|sun|mon|tue|wed|thu|fri)\s?/gi;
const [weekday] = splittedStrArr.filter((str) =>
validCaseInsensitiveWeekDayRegex.test(str)
);
if (!!weekday) {
temp.push(weekday);
splittedStrArr = splittedStrArr.filter((element) => element !== weekday);
} else {
exceptions.push(cloneSplittedStrArr);
return;
}
// step 4 將剩餘的字串變成「備註」
if (splittedStrArr.length > 0) {
// 中間插入空格
const comment = splittedStrArr.join(' ');
temp.push(comment);
}
最後我們再把符合三個條件的每筆資料,push 到 formattedData:
formattedData.push(temp);
接著讓我們在主流程的迴圈中,call 剛剛實作完的 function 來處理 splittedStrArr。
最後再把 formattedData 與 exceptions print 出來。
const main = () => {
for (const str of arr) {
// step 1
const newStr = removeExtraPeriod(str);
/**
* 以空格作為分隔點,將字串切割成 array 方便後續處理
*/
const splittedStrArr = newStr.split(' ');
// 後續處理並歸類到正確的分類
processSplittedStr(splittedStrArr);
// TODO: step 3 轉成 csv 檔
}
console.log(`===exceptions=== count: ${exceptions.length}`);
console.log(exceptions);
console.log(`===successes=== count: ${formattedData.length}`);
console.log(formattedData);
};
每筆資料都有確實被處理到: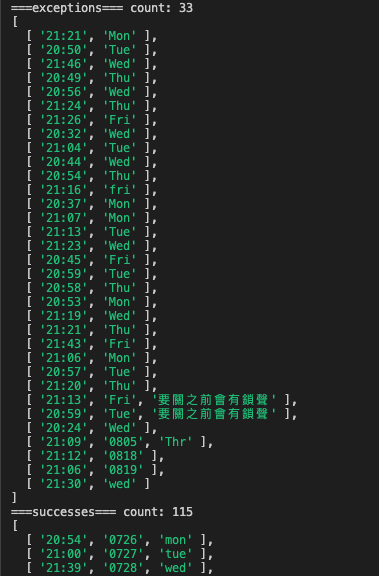
資料的形態也符合我們預期: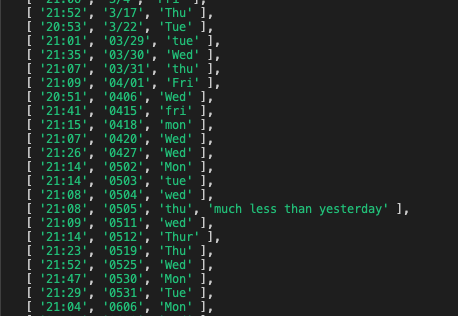
剩最後一個轉 csv 的步驟就完成結構化了呢。
今天收工!

