終於到了文件範例的最後一幕了。
以目前SRE如日中天的推廣下,適當的告警工具總是能讓運維人員預先處理硬體方面可能會面對的問題,例如: 硬碟空間剩下20%就將滿了。不過,這裡我不會介紹任何的告警工具就是了。
【重點提示】
基本的文件架構如下:
【問題描述】
...
【解決方法】
...
整個文件範例 :
【問題描述】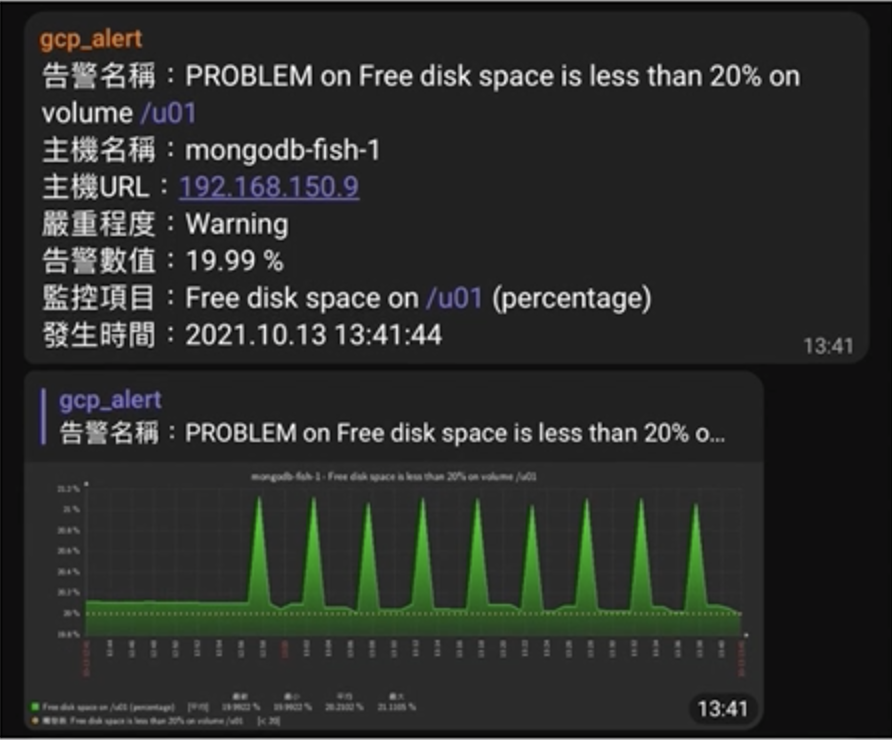
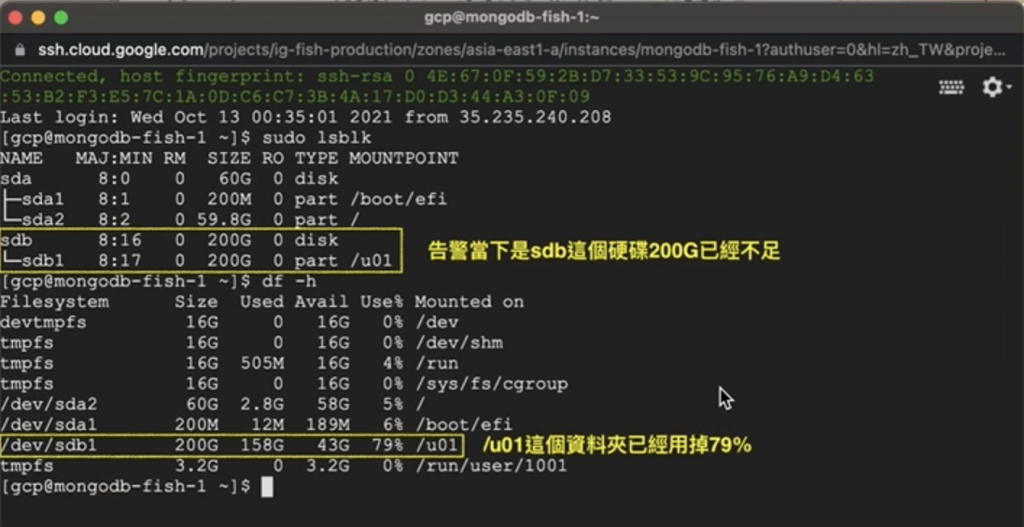
【解決方法】
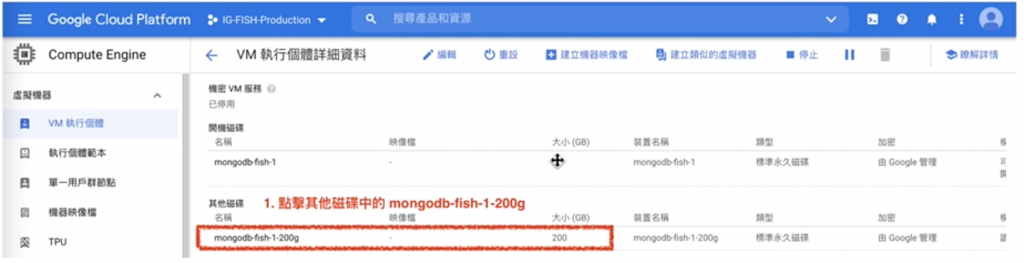
$ sudo lsblk
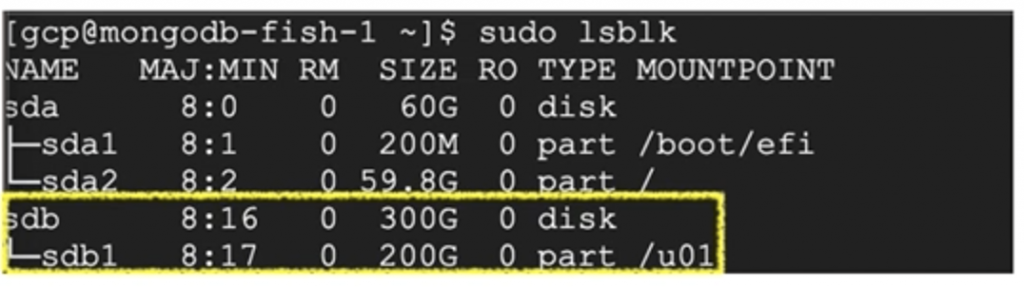
此時可看到『sdb硬碟』已經是 300 G,不過 /u01 所在的『sdb1磁區』仍只有 200 G 可用。
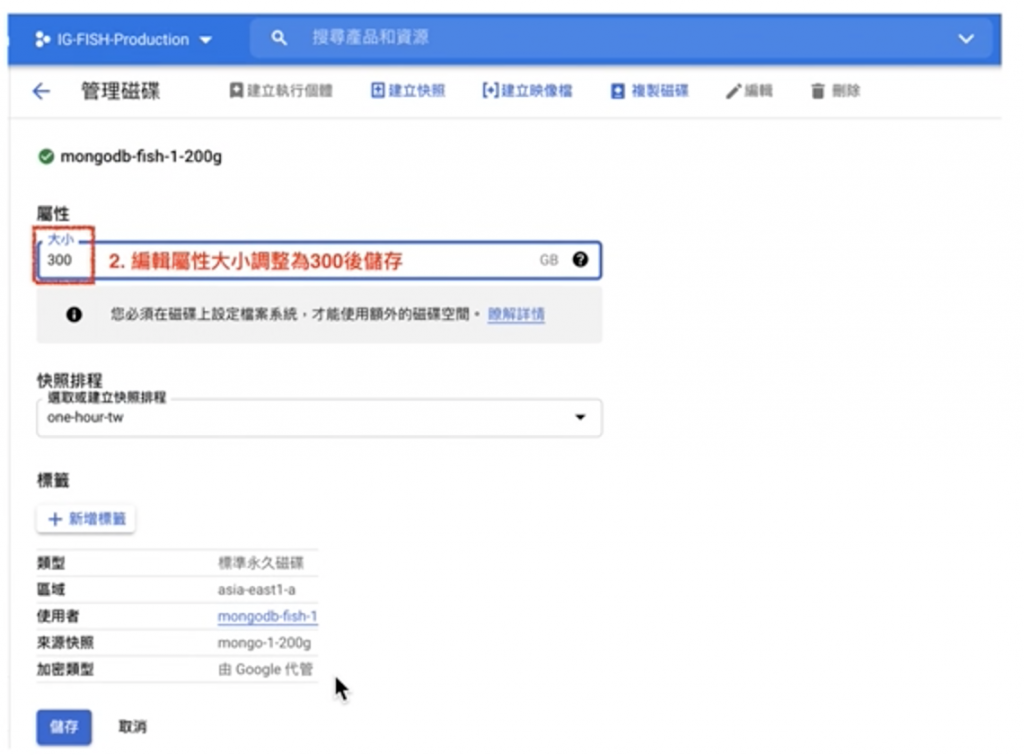
接下來就是要將『sdb1磁區』調整為 300 G。
$ growpart --help
有的話會出現下圖結果 :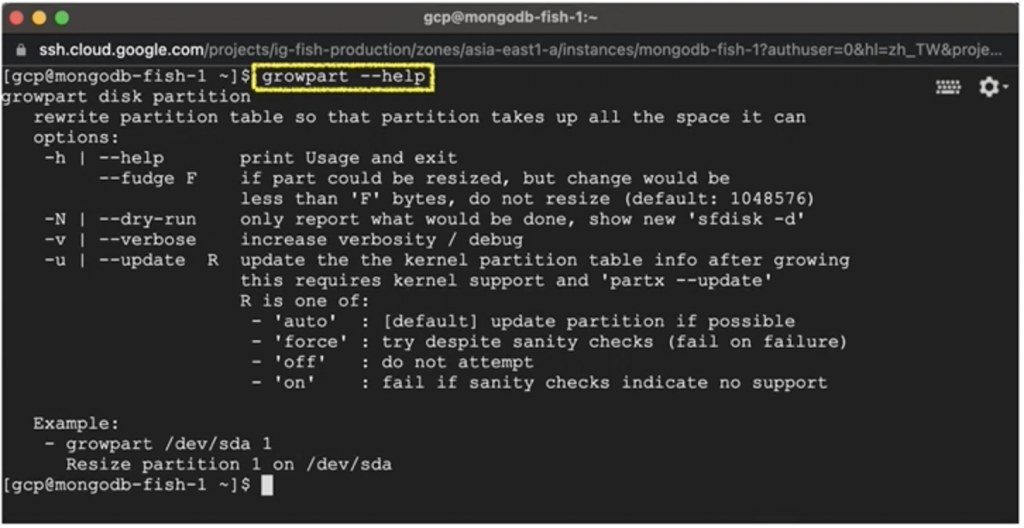
沒的話請執行以下指令安裝 :
$ sudo rpm -ivh cloud-utils-growpart-0.29-5.e17.noarch.rpm
$ sudo growpart /dev/sdb 1
將多出來的空間都配給『sdb1磁區』即完成。結果如下圖。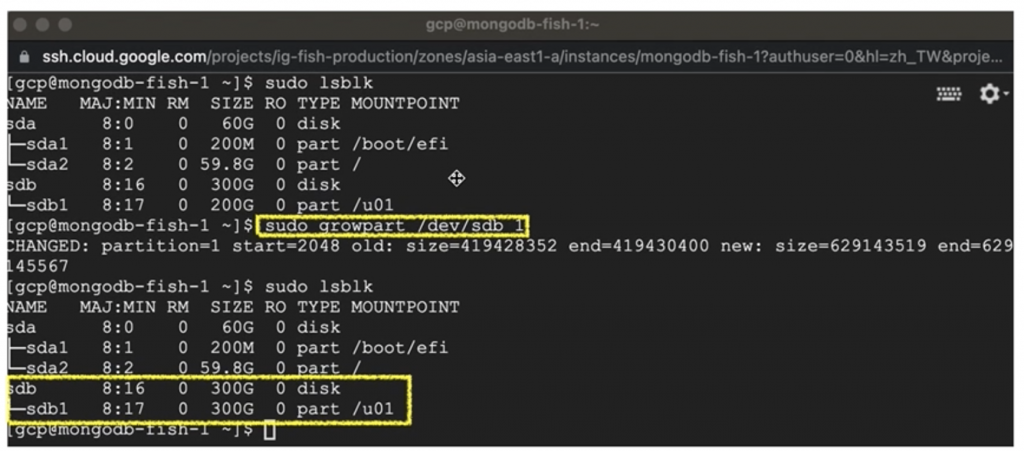
Day 17所提到的4W1H原則在撰寫排查文件時,仍需要被遵守。
只是今天引用了監控的黑科技 。一張監控的告警就幫我們把
。一張監控的告警就幫我們把4W1H原則給達成了。
在CI/CD的潮流下,Site Reliability Engineering(SRE) 的角色逐漸重要。
類似
客服說 : 客戶反映無法上傳資料,因為硬碟空間不足。
這種問題描述,在成熟的CI/CD開發模式下只會越來越少。

