在現今AI技術發展越來越純熟的狀況下,人們期待可以通過「說」的方式,讓各種機器裝置「聽」得懂我們說的話。最常見的就是Apple手機的Siri:
「Hey,Siri,幫我看今天天氣」
「今天天氣很好,但你嘴巴閉閉,我在忙。」另外,在某些場景下,例如:法庭庭審、企業會議、影片字幕等等,常常需要將錄音檔,轉換為文字;又或者是針對某些電子書的「說書」、針對視障者的文字轉合成語音的應用,也會需要使用到這類型的服務。
但是輪到實際應用開發的時候,若是自己重新訓練一個模型,或者準備設備,都需要花相當多的時間與成本,同時囿於訓練資料的不足,可能訓練出來的效果也不如預期。
那麼,究竟該如何解決這些問題呢?
語音交互在金融、保險、電商、教育、IOT產業中都佔據相當重要的角色,而如果想要解決上述的開發問題,其實我們可以採用雲原生的AI服務,在語音交互、識別、文字語音轉換(Text to Speech or Speech to Text)的這塊領域下,阿里雲發展出了所謂的「智能語音交互服務」。
筆者整理出一些最常見的應用場景:
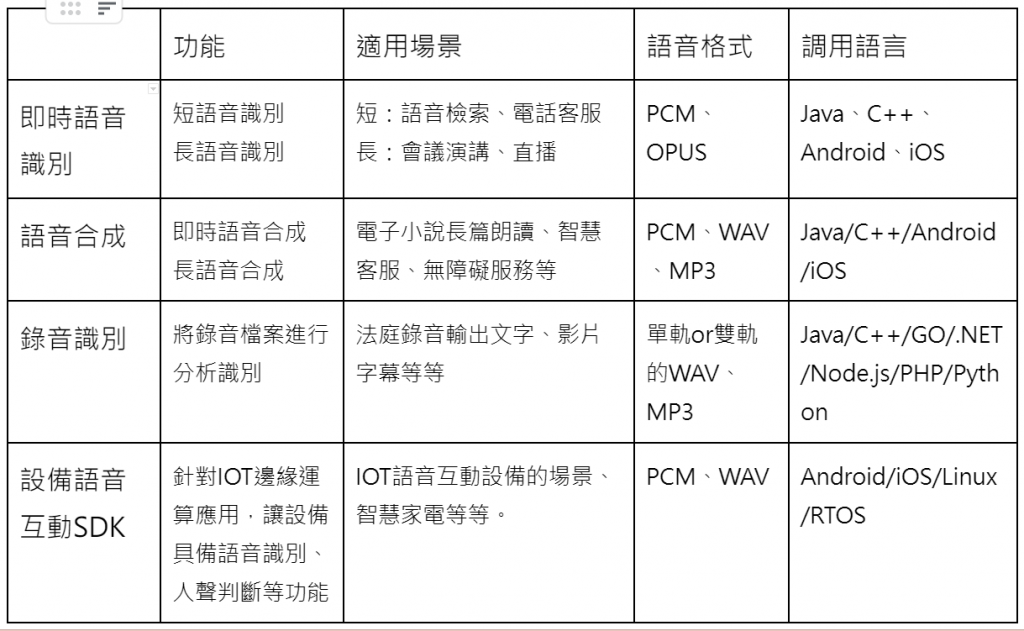
上述的表格粗略的簡介了阿里雲上面「智能語音交互」的服務,而阿里雲在語音識別、合成上又有哪些特點呢?
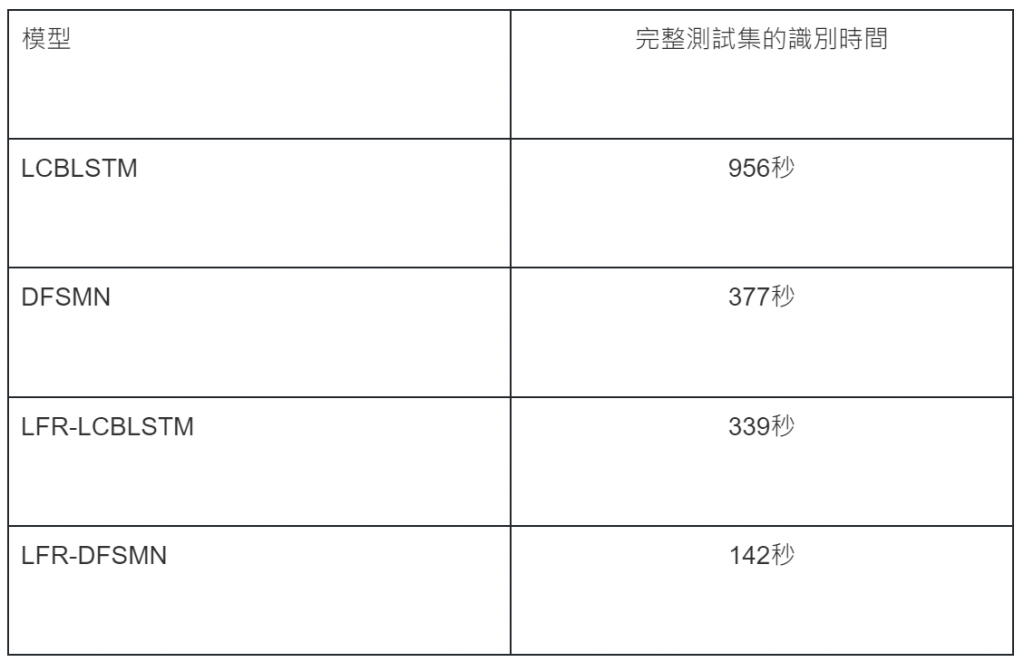
在語音識別上,阿里巴巴iDST智能語音交互團隊,根據自身AI上的經驗,除了建構自有的AI語音訓練模型,並採用字级LC-BLSTM/DFSMN-CTC的模型外,也使用了LFR-DFSMN(Lower Frame Rate-Deep Feedforward Sequential Memory Networks)的新技術,讓識別速度相較傳統的模型提高三倍以上,同時複雜度也下降三倍以上。效果如下圖所示:
那麼接下來,話不多說,就讓筆者為各位展示阿里雲的智能語音交互如何操作吧!
實作:
本次實作將會使用語音合成的功能,先合成一段自定義的語音,並用語音識別,來將此語音轉換為文字。
此外本次使用的範例程式碼為Python3,並且使用Visual Studio。
工欲善其事,必先利其器。先來開通智能語音交互服務,開通後會長的如下畫面,本次因為僅測試用,所以全部選擇試用即可。
開通完成後,選擇畫面上的「我的項目」,並且選擇「創建項目」
填寫好名稱後,直接創建。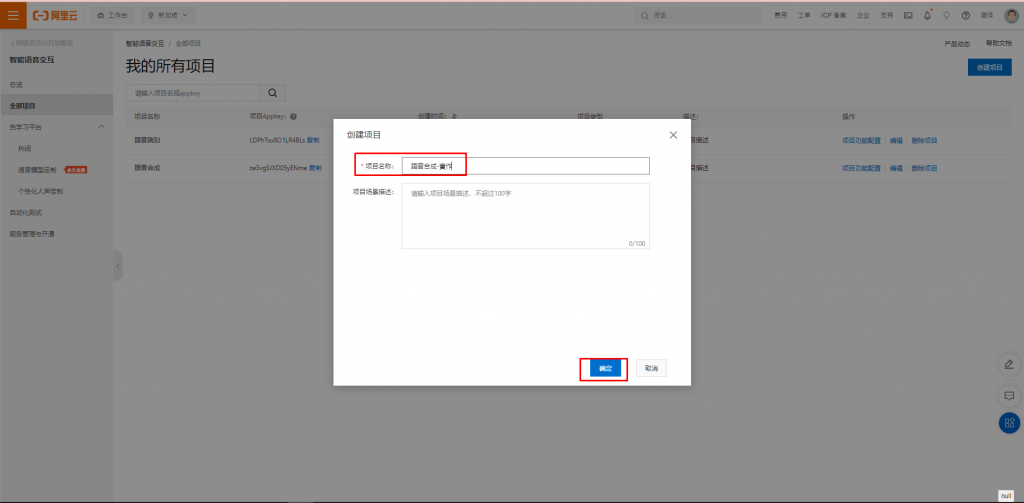
創建後點選功能配置。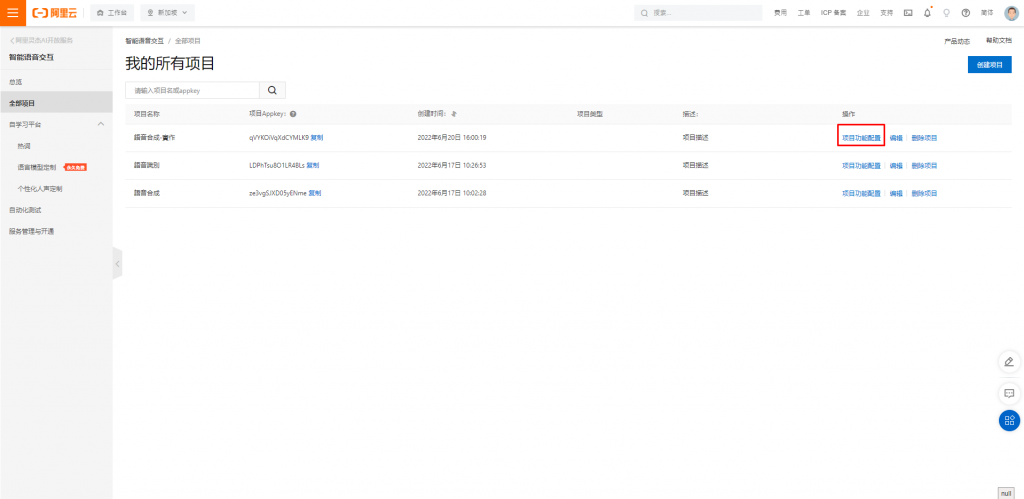
選擇語音合成,並且點選去配置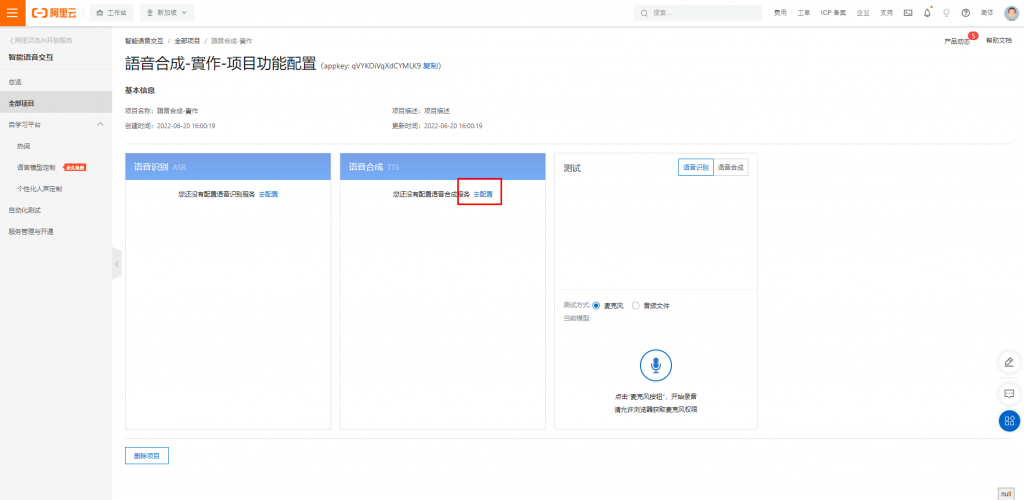
在這邊,可以配置音調、配置音色、以及聲量等等,創建完成即可用Python3來呼叫語音合成的服務。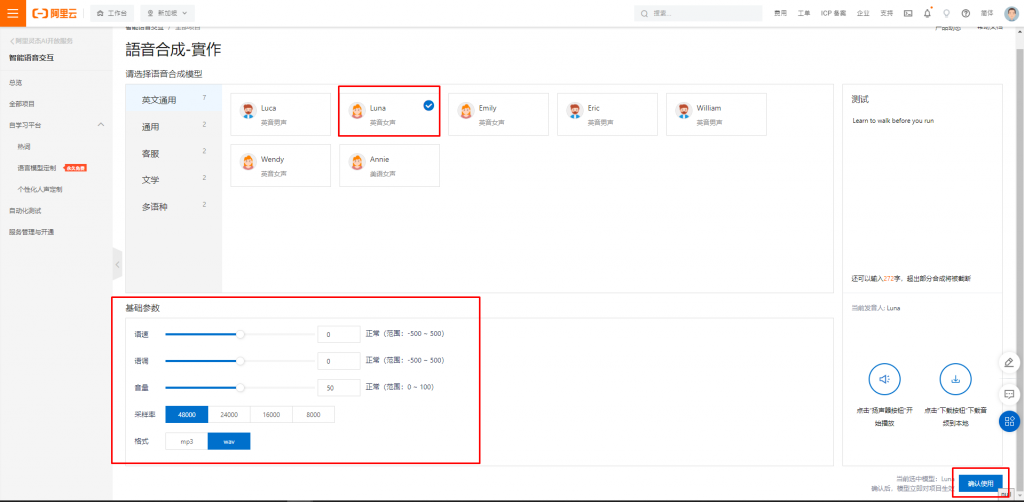
創建完成後,就需要使用程式碼來調用服務,需要使用到項目AppKey、Access Token(僅作測試用),如下圖位置。
Access Token: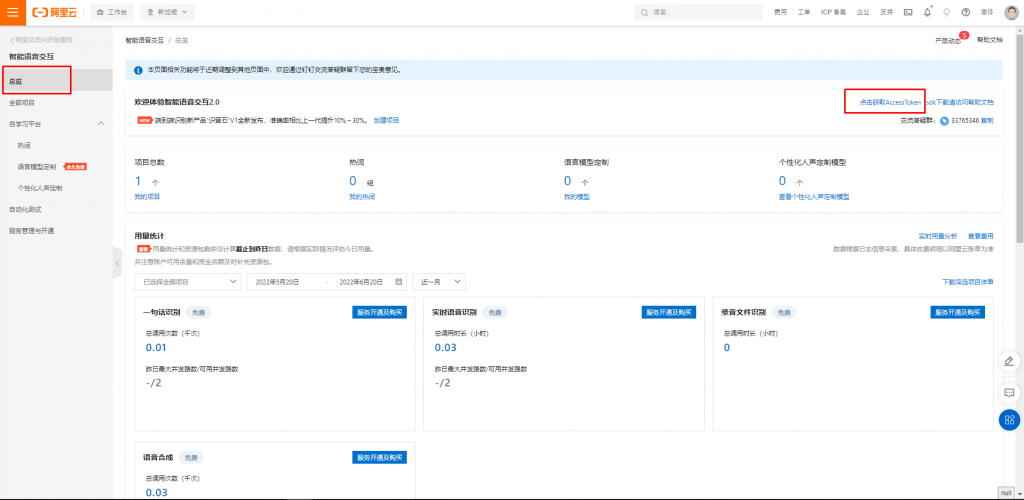
項目AppKey: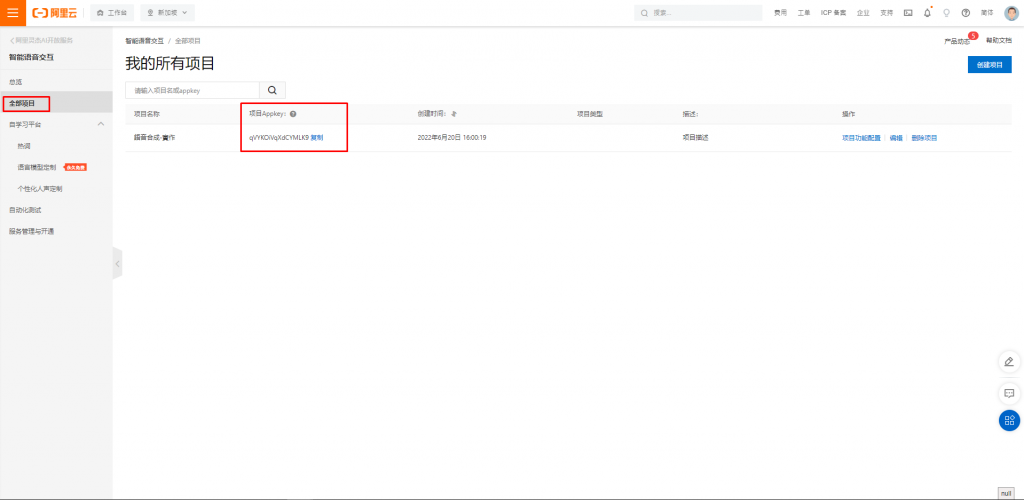
可以在我的Github裡面找到本次語音合成的程式碼,並且將appkey、token修改成自己的,並且將想要翻譯的字放在text變數裡,本次使用「Learn to walk before you run」這句話,當作語音合成用。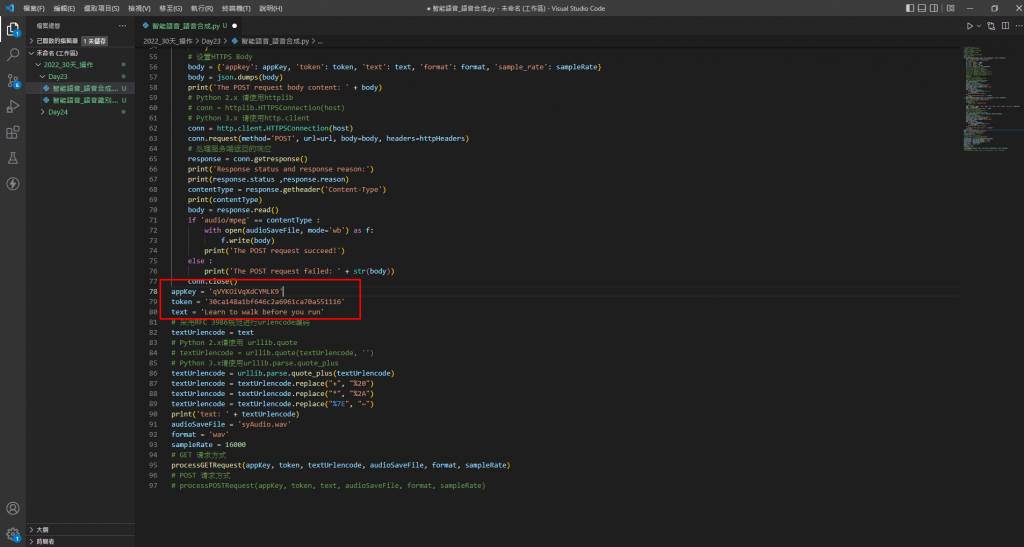
執行,獲得200OK!成功獲取一個新的Audio檔案(.wav格式),檔案名稱為syAudio.wav,這個檔案便是Ali的合成語音。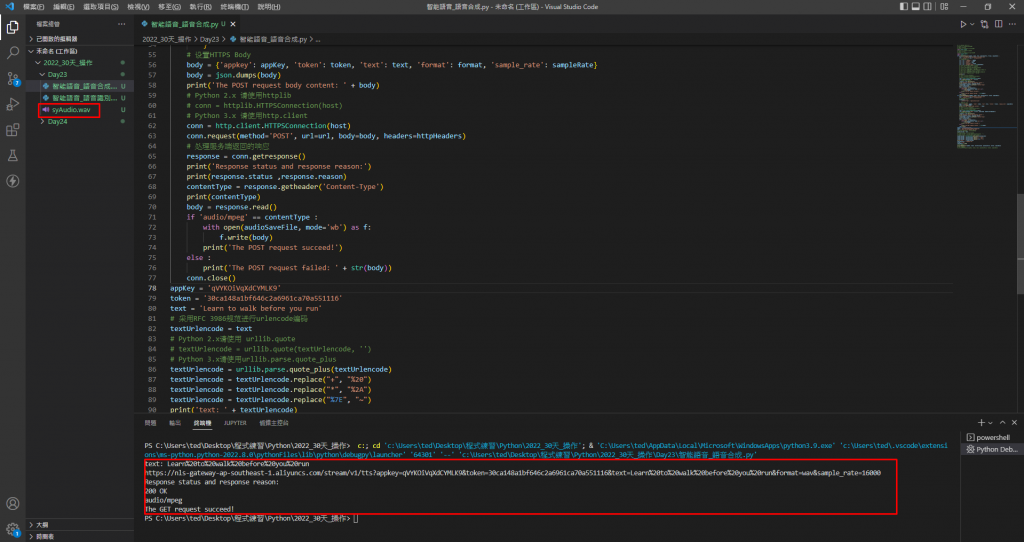
接下來重複步驟3與步驟4,但創建的是語音識別,並且系統會請我們配置模型,選擇基於場景選擇模型。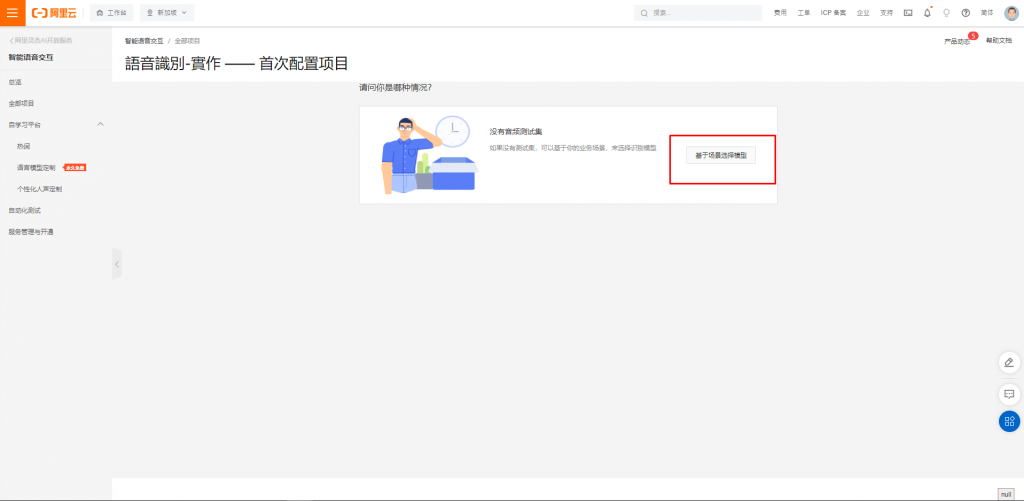
選擇英語識別模型後按下確認。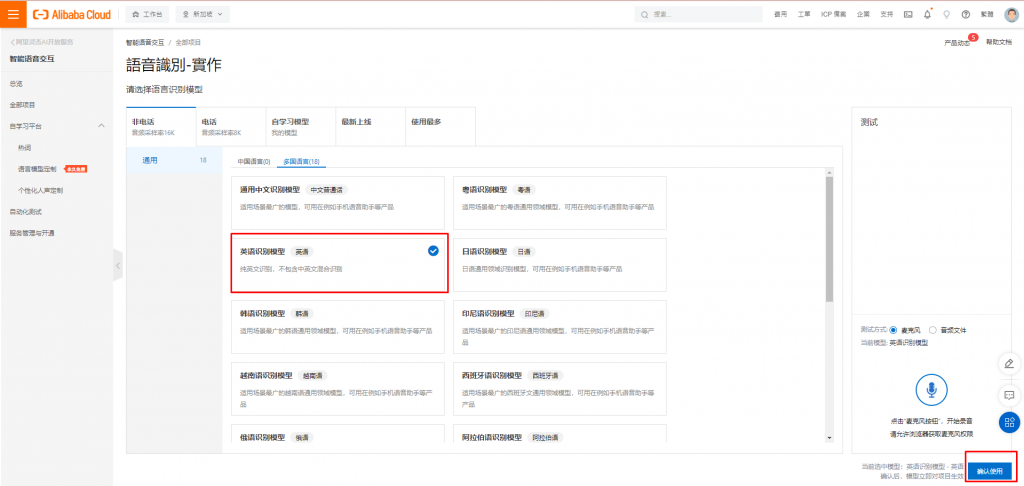
可以在我的Github裡面找到本次實作語音識別的程式碼,並且將appkey(記得與語音合成的AppKey不同)、token修改成自己的,並且將音檔位置放在audioFile的變數當中,如下圖。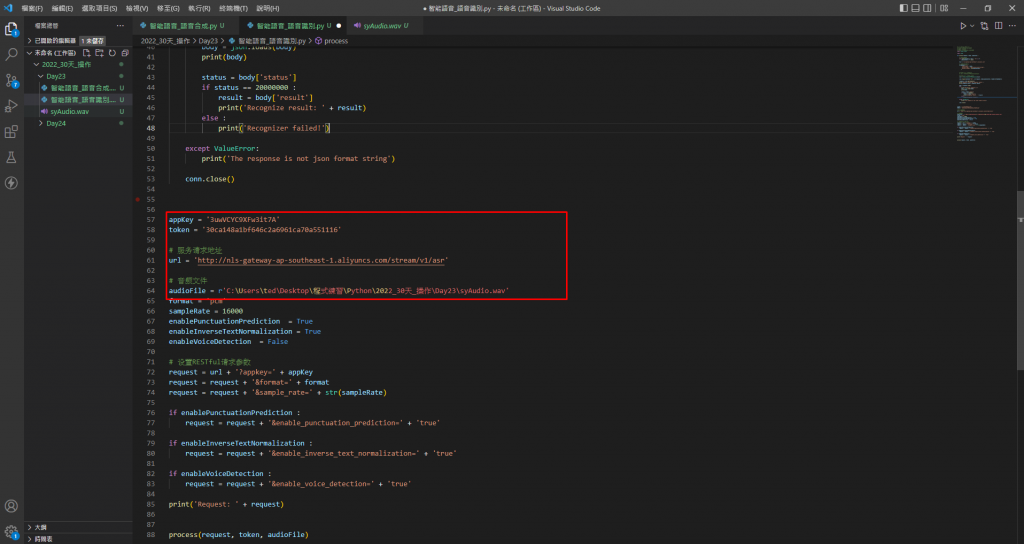
執行Python Code調用服務,預期的結果是「Learn to walk before you run」。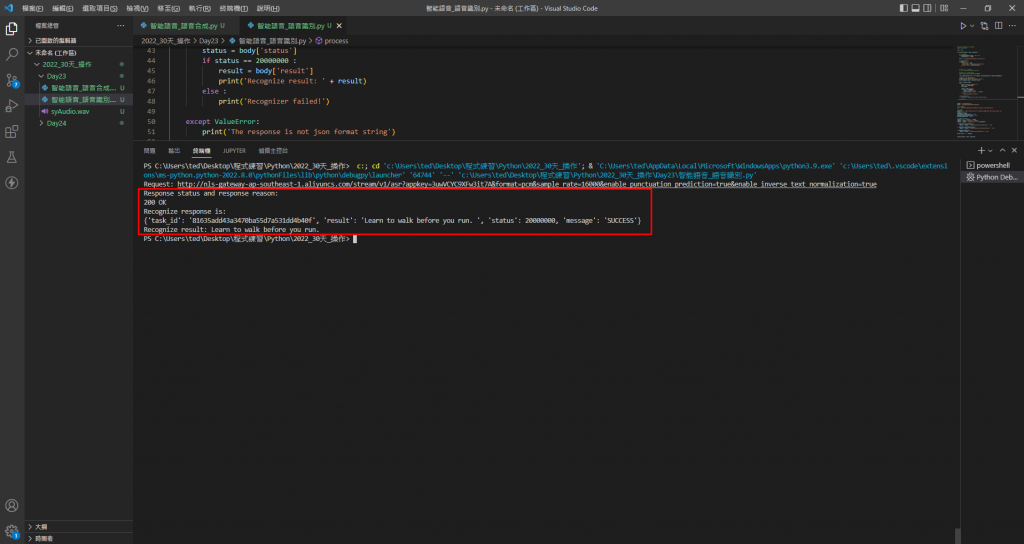
大成功!
本次實作透過Python3來執行,並且完成語音合成與語音識別的功能,結果也如同我們預期的一樣,有興趣的小夥伴不妨拿自己講話的音檔試試喔!
敬請期待接下來的文章吧!!!

