今天改來玩另一個遊戲,文字接龍,但這接龍的規則不太一樣,是要根據前面的句子,繼續接下去,讓我們來看看怎麼做到。
首先我們來用比較詩意的句子,先把它load進來,並同樣創成字典庫:
# Load the dataset
data = open('./irish-lyrics-eof.txt').read()
# Lowercase and split the text
corpus = data.lower().split("\n")
# Initialize the Tokenizer class
tokenizer = Tokenizer()
# Generate the word index dictionary
tokenizer.fit_on_texts(corpus)
# Define the total words. You add 1 for the index `0` which is just the padding token.
total_words = len(tokenizer.word_index) + 1
接著我們再將每個句子轉成代碼後,拆成從最前面的兩個字,依序到完整句子的片段,以中文"我是一隻小小小小鳥"舉例,這樣拆是可以將每個字成標籤,這個字前面的句子就是對應的資料: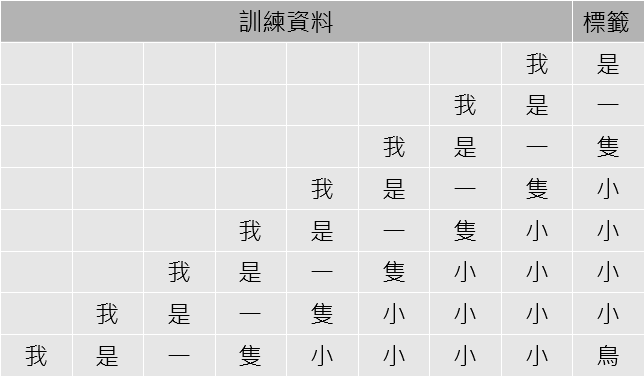
程式碼如下,然後再將標籤對應的代碼,轉換成單字量大小的陣列的index,也就是單字代號的那個索引嚇得值為1,其他為0:
# Initialize the sequences list
input_sequences = []
# Loop over every line
for line in corpus:
# Tokenize the current line
token_list = tokenizer.texts_to_sequences([line])[0]
# Loop over the line several times to generate the subphrases
for i in range(1, len(token_list)):
# Generate the subphrase
n_gram_sequence = token_list[:i+1]
# Append the subphrase to the sequences list
input_sequences.append(n_gram_sequence)
# Get the length of the longest line
max_sequence_len = max([len(x) for x in input_sequences])
# Pad all sequences
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))
# Create inputs and label by splitting the last token in the subphrases
xs, labels = input_sequences[:,:-1],input_sequences[:,-1]
# Convert the label into one-hot arrays
ys = tf.keras.utils.to_categorical(labels, num_classes=total_words)
接下來就是建立模型,由於同樣有上下文的關係,所以用LSTM版本的,另外如同在圖形辨識時多個分類的設定:
# Hyperparameters
embedding_dim = 100
lstm_units = 150
learning_rate = 0.01
# Build the model
model = Sequential([
Embedding(total_words, embedding_dim, input_length=max_sequence_len-1),
Bidirectional(LSTM(lstm_units)),
Dense(total_words, activation='softmax')
])
# Use categorical crossentropy because this is a multi-class problem
model.compile(
loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate),
metrics=['accuracy']
)
epochs = 100
# Train the model
history = model.fit(xs, ys, epochs=epochs)
訓練玩模型後,首先我們來看它造句子的能力,我們要掀起個頭,然後我們就用這個片段去預測下個字,然後再把這個字將到原本的片段上,反覆看我們要造多長,它就會一直接下去了:
# Define seed text
seed_text = "good morning"
# Define total words to predict
next_words = 20
# Loop until desired length is reached
for _ in range(next_words):
# Convert the seed text to a token sequence
token_list = tokenizer.texts_to_sequences([seed_text])[0]
# Pad the sequence
token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')
# Feed to the model and get the probabilities for each index
probabilities = model.predict(token_list)
# Get the index with the highest probability
predicted = np.argmax(probabilities, axis=-1)[0]
# Ignore if index is 0 because that is just the padding.
if predicted != 0:
# Look up the word associated with the index.
output_word = tokenizer.index_word[predicted]
# Combine with the seed text
seed_text += " " + output_word
# Print the result
print(seed_text)
以"good morning”為例,造出20個字的句子是:
good morning of the day before the last dim weeping and the song they sang love love love love me he love
還真出乎意料有點意思!


 iThome鐵人賽
iThome鐵人賽