又開始一個新的應用,在day11至day18我們已經完成NLP的課程,接下來是Sequences, Time Series and Prediction
標題的趨勢、週期性、自我相關、與雜訊是時間資料常見的特徵,例如近期美金有上漲的趨勢,期貨有週期性的變化,股市每天甚至每分每秒都有小波動等,而這些在影像或是聲音的處理也是耳熟能像的,那在這些傳統的理論和處理工具外,機器學習有哪些可以導入和特點呢,讓我們來看這個範例,如下圖,這個時間資料具有緩慢上升的趨勢、週期性的變化與雜訊,而我們已0到999為訓練資料,1000以後為驗證資料: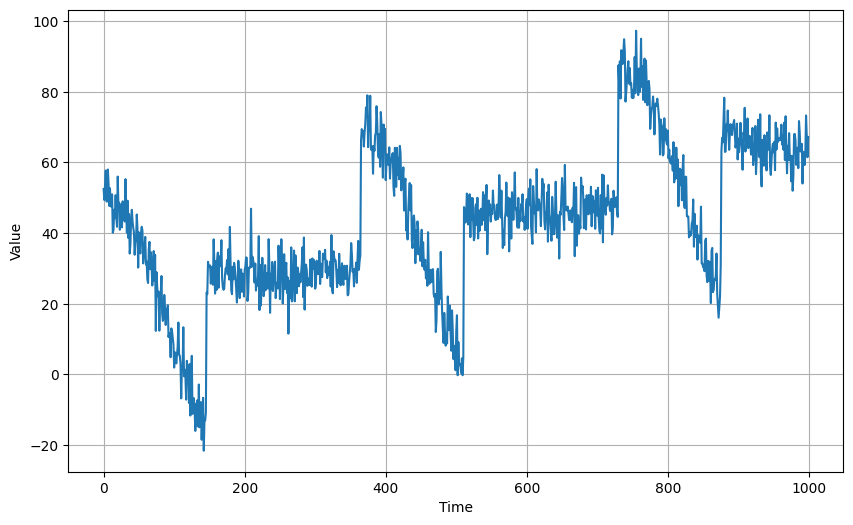
首先我們用基本的平均,取20點一組: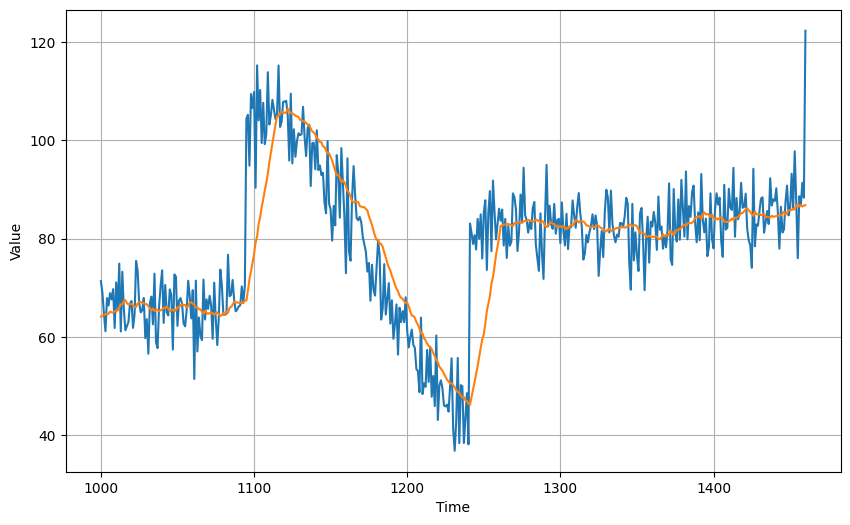
我們可以計算所謂誤差的評判標準,MSE和MAE,MSE就是誤差量取平方後再平均,而MAE是誤差量取絕對值後再平均:
MSE: 53.815857
MAE: 5.424043
那如何機器學習呢?我們同樣需要標籤和資料,這故事就像昨天”我是一隻小小小小鳥”的範例一樣,以每個時間的值為標籤,而這個時間前的一定區間為資料,而這TensorFlow提供了function可以直接處理:
def windowed_dataset(series, window_size, batch_size, shuffle_buffer):
"""Generates dataset windows
Args:
series (array of float) - contains the values of the time series
window_size (int) - the number of time steps to include in the feature
batch_size (int) - the batch size
shuffle_buffer(int) - buffer size to use for the shuffle method
Returns:
dataset (TF Dataset) - TF Dataset containing time windows
"""
# Generate a TF Dataset from the series values
dataset = tf.data.Dataset.from_tensor_slices(series)
# Window the data but only take those with the specified size
dataset = dataset.window(window_size + 1, shift=1, drop_remainder=True)
# Flatten the windows by putting its elements in a single batch
dataset = dataset.flat_map(lambda window: window.batch(window_size + 1))
# Create tuples with features and labels
dataset = dataset.map(lambda window: (window[:-1], window[-1]))
# Shuffle the windows
dataset = dataset.shuffle(shuffle_buffer)
# Create batches of windows
dataset = dataset.batch(batch_size).prefetch(1)
return dataset
然後我們以20點為一組,然後最簡單的1維的一層dense,由於評判標準是MSE和MAE,所以loss我們設MSE:
# Parameters
window_size = 20
batch_size = 32
shuffle_buffer_size = 1000
# Generate the dataset windows
dataset = windowed_dataset(x_train, window_size, batch_size, shuffle_buffer_size)
# Build the single layer neural network
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(1, input_shape=[window_size])
])
# Set the training parameters
model.compile(loss="mse", optimizer='adam', metrics=['accuracy'])
# Train the model
model.fit(dataset,epochs=200)
訓練200次後loss為42.7771,然後我們就可以能訓練後的模型來預測:
# Initialize a list
forecast = []
# Use the model to predict data points per window size
for time in range(len(series) - window_size):
forecast.append(model.predict(series[time:time + window_size][np.newaxis]))
# Slice the points that are aligned with the validation set
forecast = forecast[split_time - window_size:]
# Convert to a numpy array and drop single dimensional axes
results = np.array(forecast).squeeze()
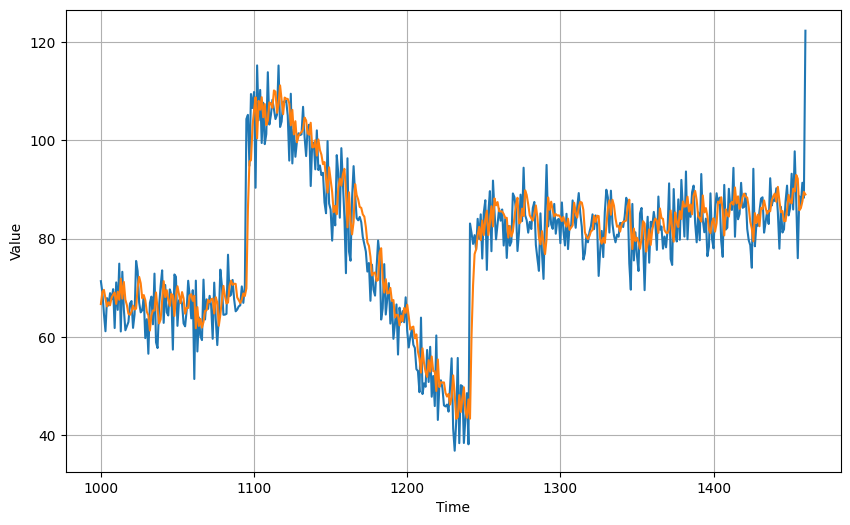
MSE: 75.38902
MAE: 6.348177
我們改用另外一個optimizer:
# Set the training parameters
model.compile(loss="mse", optimizer=tf.keras.optimizers.SGD(learning_rate=1e-6, momentum=0.9))
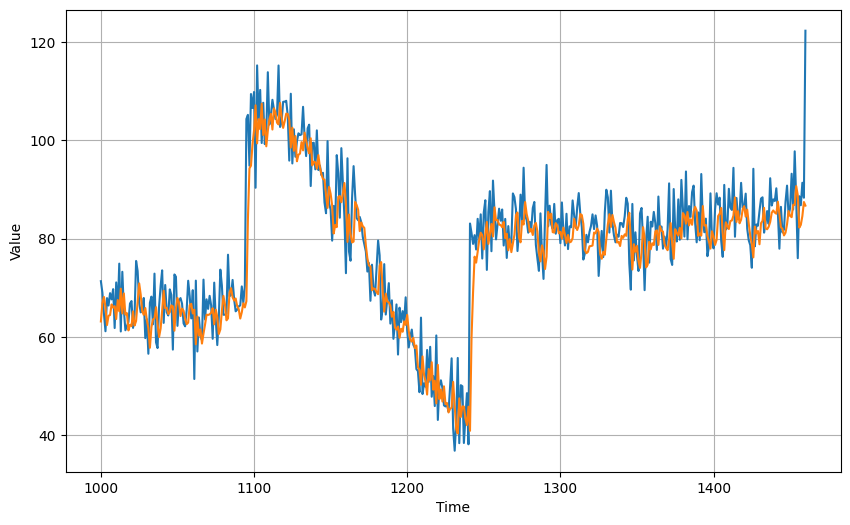
MSE: 47.908802
MAE: 5.064415
MSE和MAE的結果都較低,而且和平均的方式接近。


 iThome鐵人賽
iThome鐵人賽