除了昨天新的LSTM,GRU和原本的GlobalAveragePooling1D,還有Flatten和之前學的Convolution都拿來比較用用看,我們改用IMDB沒有subword的資料,自己建字典的版本,單字庫設定10000個,而句子長度設120,這次從簡單的開始。
Flatten:
# Parameters
embedding_dim = 16
dense_dim = 6
# Model Definition with a Flatten layer
model_flatten = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(dense_dim, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# Set the training parameters
model_flatten.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
結果一開始就有很高的accuracy和很低的loss: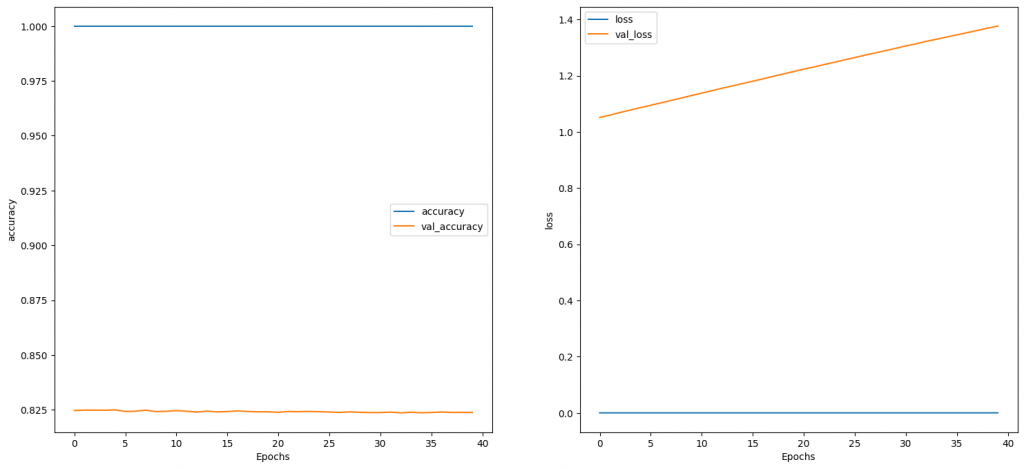
GlobalAveragePooling1D:
# Parameters
embedding_dim = 16
dense_dim = 6
# Model Definition with a Flatten layer
model_pool = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(dense_dim, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# Set the training parameters
model_pool.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
結果如下: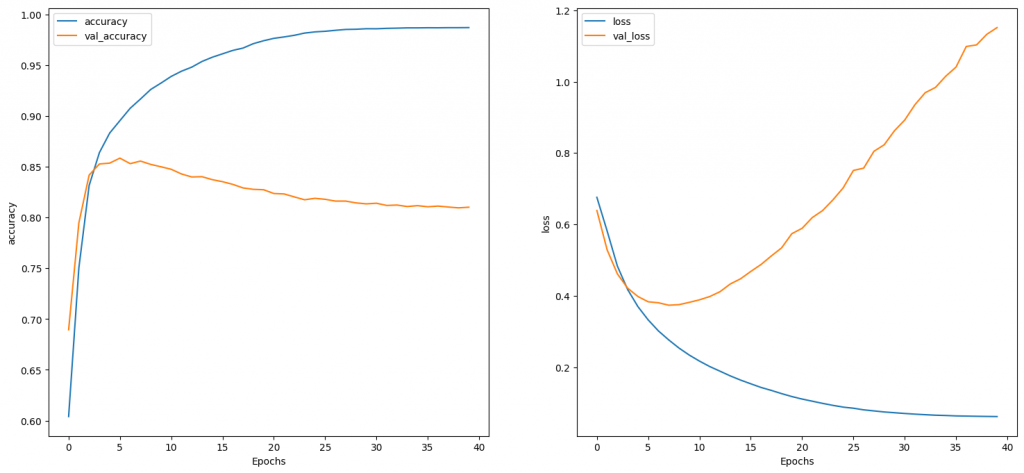
一層LSTM:
# Parameters
embedding_dim = 16
lstm_dim = 32
dense_dim = 6
# Model Definition with LSTM
model_lstm = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(lstm_dim)),
tf.keras.layers.Dense(dense_dim, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# Set the training parameters
model_lstm.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
一個epoch在colab上約4秒,結果如下: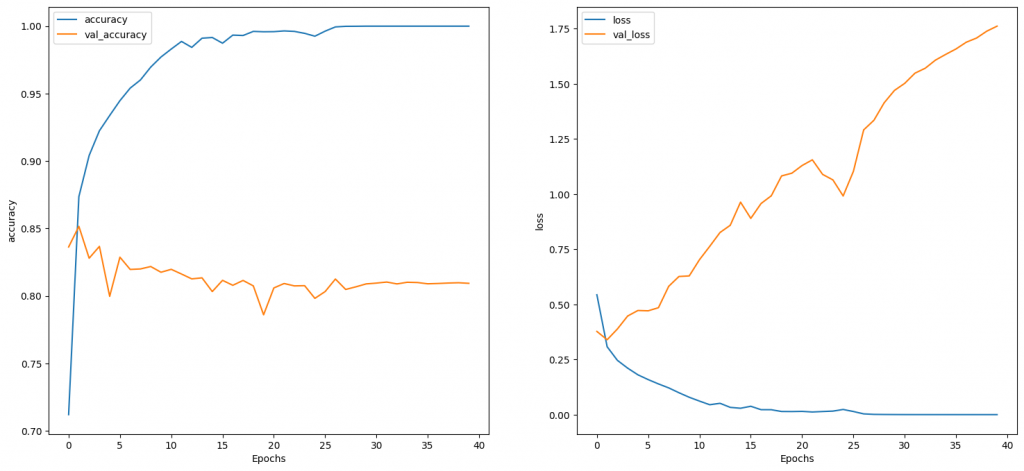
兩層LSTM:
# Parameters
embedding_dim = 16
lstm_dim1 = 64
lstm_dim2 = 32
dense_dim = 6
# Model Definition with LSTM
model_lstm2 = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(lstm_dim1, return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(lstm_dim2)),
tf.keras.layers.Dense(dense_dim, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
一個epoch在colab上約7秒,結果如下: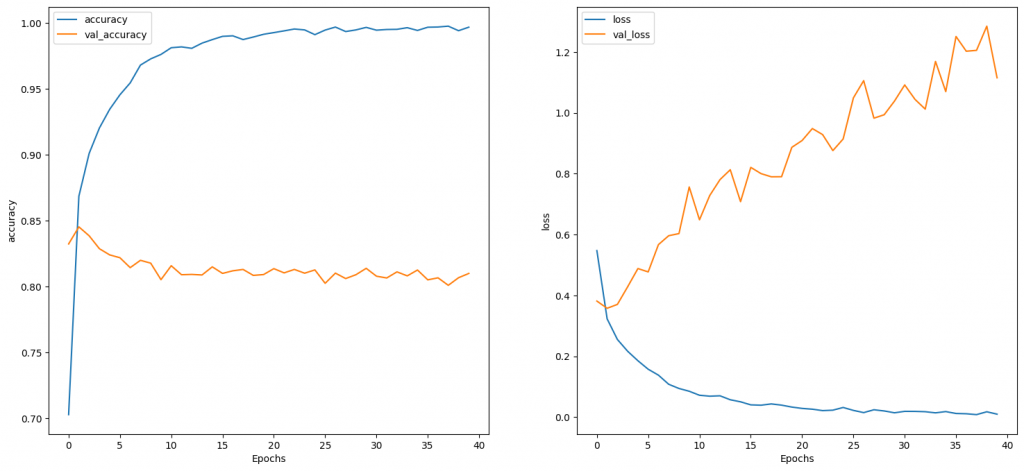
GRU:
# Parameters
embedding_dim = 16
gru_dim = 32
dense_dim = 6
# Model Definition with GRU
model_gru = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.Bidirectional(tf.keras.layers.GRU(gru_dim)),
tf.keras.layers.Dense(dense_dim, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
一個epoch在Colab上約4秒,結果如下: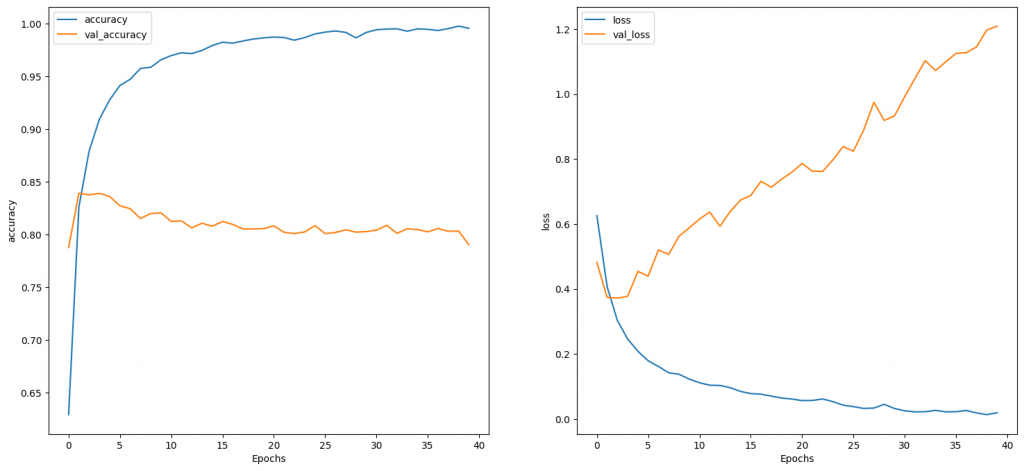
Conv1D接GlobalAveragePooling1D:
# Parameters
embedding_dim = 16
filters = 128
kernel_size = 5
dense_dim = 6
# Model Definition with Conv1D
model_conv = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.Conv1D(filters, kernel_size, activation='relu'),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(dense_dim, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
結果如下: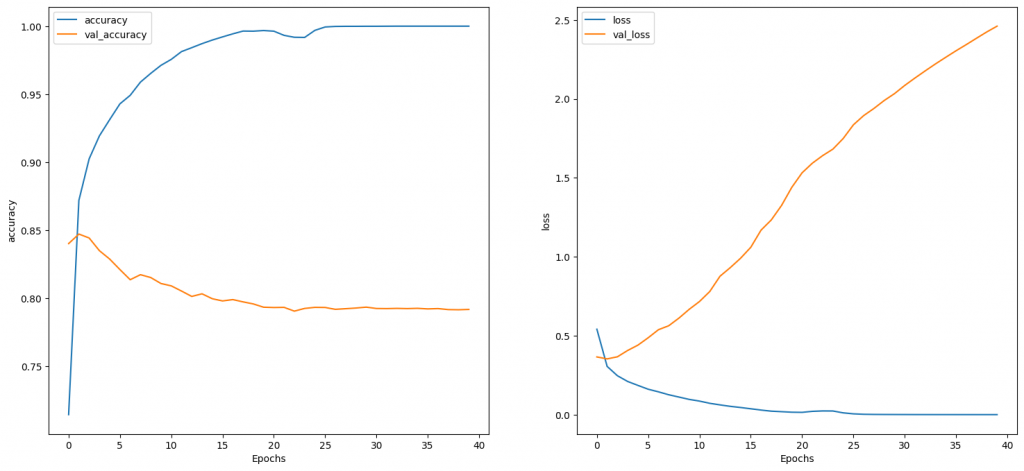
Conv1D接Flatten:
# Parameters
embedding_dim = 16
filters = 128
kernel_size = 5
dense_dim = 6
# Model Definition with Conv1D
model_conv_flat = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.Conv1D(filters, kernel_size, activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(dense_dim, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
結果如下,曲線特別平滑: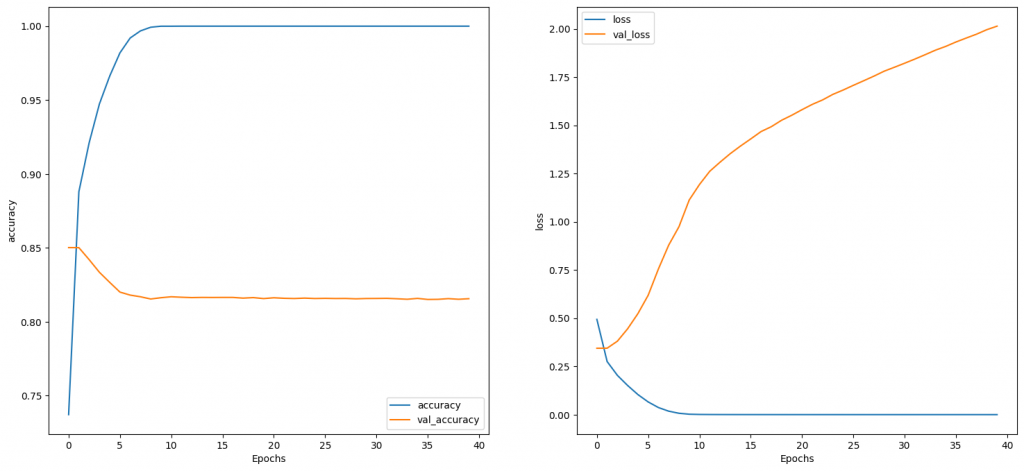
其中只有用flatten一開始就有很高的accuracy和很低的loss比較特別,另外模擬時間除了LSTM和GRU比較長外,其他沒標註的單個epoch都在1至2秒。


 iThome鐵人賽
iThome鐵人賽