一些之後架設「基於自然語言處理的新聞意見提取應用」所需的前置作業(新聞資料庫和 API、新聞自動爬蟲)都建構的差不多了,今天要來談一談第一個實驗的構想。
「基於自然語言處理的新聞意見提取應用」主要有兩個重要的課題,一是「如何從政治新聞當中提取出人物意見」,二是「怎麼應用這些提取出的意見」。我將從「如何從政治新聞當中提取出人物意見」的方法設計著手,也就是今天要講的內容。
雖然目前建立好的新聞資料庫至今已經累積到一定的量,但是如果只是要初步測試下一段中所介紹的方法效果如何,就沒辦法一次使用太多新聞資料,否則在判讀結果時容易因工作量太大而有些混亂。
但是如果從目前的新聞資料庫中隨機選擇適量的新聞資料來進行實驗,除非人工一一閱讀分類,不然很難知道這些被選擇的新聞當中有哪些屬於同一主題。由於我希望這次實驗的結果能後續用於「測試意見應用的構想」,所以我打算從中央社的「新聞專題」頁面中,選擇幾個比較近期,且屬於政治類別的新聞專題分類,並使用當中的多篇新聞文章來進行實驗。可能從中選擇的新聞專題如下:
下圖為數位中介法 的頁面截圖,可以從中取得屬於此議題的相關新聞文章:
上面這些新聞專題分類中的多篇新聞文章除了可以用來測試人物意見提取的效果外,還可以用於近一步分析「屬於同一新聞專題下的新聞文章彼此間存在什麼判斷依據?」的議題。
接下來將介紹「人物意見提取」的方法構想。
自然語言的技術中的 Constituency Parsing 利用語法規律和斷詞後的文本做比對,找出可能的短語結構,包含了斷詞、Part-of-Speech 詞性標記等子任務,將嘗試以CKIP CoreNLP Toolkit 來完成上述任務。
剖析例句:
剖析結果
S(agent:NP(Head:Nb:蔡某某)|location:PP(Head:P21:在|DUMMY:GP(DUMMY:NP(Head:Nca:中常會)|Head:Ng:上))|Head:VE2:表示)
S(time:Ndaba:今年|agent:NP(Head:Nhaa:她)|topic:PP(Head:P31:針對|DUMMY:NP(property:Nca:台灣|property:NP(property:N‧的(head:Nddc:當前|Head:DE:的)|Head:Ncdb:內外)|Head:Nac:挑戰))|Head:VC31:提出|aspect:Di:了|theme:NP(property:DM:四個|Head:Nv3:堅持))
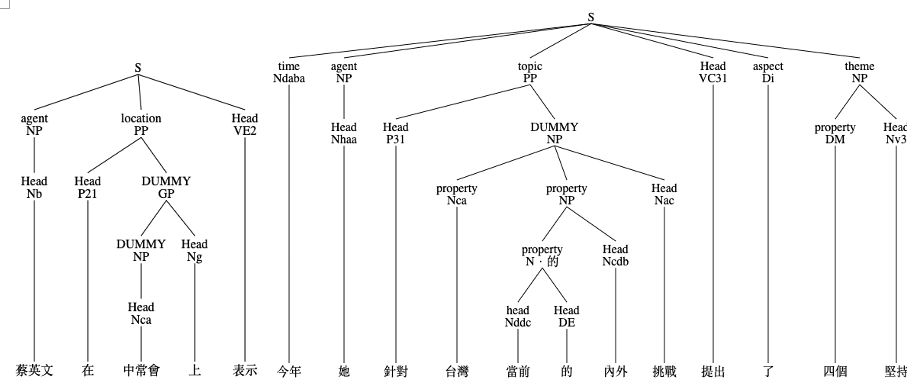
此步驟透過分析 Constituency Parsing 的結果,找出意見持有者表示意見的動詞。上圖範例中標示為「Head:VE2」的動詞「表示」就用於表示意見持有者表示個人意見。VE2(AGENT GOAL)這個動詞標註只須兩個論元,即滿足語意表現。語意上,多半表與語言行為 (speech act)有關,如:談論、思考、決定、宣布、表示、猜。本研究將分析VE2 標記與人工所標註中用於表示意見的動詞兩者間的差異,制定方法找出意見持有者表示意見的動詞。
此步驟結合 Constituency Parsing 與上一步的動詞結果,找出動詞對應的意見持有者。以上圖的剖析結果為例,以「agent:NP(Head:Nb:蔡某某)」標示的人物「蔡某某」就是對應到動詞「表示」的意見持有者。Agent 這個語意角色(Role)在定義上表事件中的肇始者,動作動詞的行動者。本研究將透過分析意見持有者與上一步的動詞結果兩者在Constituency Parsing 結構中的位置關係,制定方法找出意見動詞所對應到的意見持有者。
此步驟要透過用於表示意見的動詞與意見持有者兩者,搭配 Constituency Parsing 的剖析結果,制定方法決定意見句的範圍。以上圖的剖析結果為例,一完整意見句「蔡某某在中常會上表示,今年她針對台灣當前的內外挑戰提出了四個堅持。」被 CKIP CoreNLP Toolkit 斷句成「蔡某某在中常會上表示」以及「今年她針對台灣當前的內外挑戰提出了四個堅持」兩句,將制定方法找出完整的意見句範圍。
在網路政治新聞撰寫的過程中,為避免過於頻繁的出現同一人物的姓名,常在新聞中使用不同的代名詞穿插表示同一人物。例如現今的行政院長「蘇貞昌」在新聞中會以「蘇院長」、「蘇揆」、「行政院長」、「蘇」等代名詞替換。為了避免將不同代名詞的表示法視為不同人,需要以 Coreference Resolution 的技術,還原代名詞所指人物。將使用 CKIP CoreNLP Toolkit 中的 Coreference Resolution 工具得到初步的還原結果,再制定方法修正出現的代換錯誤。
在文章發布前發現蔡總統的姓名似乎屬於禁用字元,只好改用蔡某某來替代,還好沒趕最後時間發文。
今天的內容就先到這嘍,明天開始就要將以上「人物意見提取的方法構想」實作出來,感覺真的很硬。

