前兩天([Day-14] 開始使用 Label Studio、[Day-15] 將意見提取標註導入到 Label Studio),碰上了不少 Label Studio 使用上的問題,以至於做出的新聞標註頁面及文章質量都沒有達到我的個人要求,今天將會介紹新聞標註頁面的改進方式,但前兩天的文章內容可能就要等這次的鐵人賽結束後我才能去做更動。
這兩天之所以會碰到 Label Studio 使用上的問題,是因為我希望將同一篇新聞的多個段落呈現在同一個標註頁面中,以便閱讀一些跨段落的關聯性。但由於很不幸運的,我嘗試使用 Label Studio 中一個名為 Repeater 的 Template 新用法,雖然在 Repeater 的文檔中有明確註明可以用這個 Repeater 來顯示以 list[str] 結構(多個新聞段落的 list)所表示的文字內容,但是在最新版本的 Label Studio v1.6.0 這個 Repeater 方法並不能跟文檔中描述一樣正常運作,在這篇 issue Repeater indexing fail in labelling interface #3013 當中顯示也有人遇到了同樣的問題。更扯的是官方的範例也有問題,官方的範例在 Label Studio Playground 也無法正常顯示。看來得要等到 Label Studio 的版本更新才有可能正常使用 Repeater 了。這次真的學到以後要對開源專案的文檔更加懷疑的教訓了。
由於我還是覺得「將同一篇新聞的多個段落呈現在同一個標註頁面中,以便閱讀一些跨段落的關聯性」這件事相當重要,所以我今天又不放棄的在 Label Studio v1.6.0 的文檔中找尋解決方案,最後終於讓我找到 Paragraphs 和 ParagraphLabels 這兩個能解決當前問題的用法。讚!開心~
由於 Label Studio 的文檔中的重要資訊分類給我一種跳來跳去、沒在同一頁面以至於查找不易的感覺,我整理了下面的連結列表,讓需要的人方便查看:
首先先來秀一下今天改進後的成果與昨天的看起來有什麼,再慢慢介紹做了哪些更動。
上面這張圖片是昨天的標註介面設計,可以看見每個標註頁面中只會顯示新聞中的其中一個段落的文字內容(<p>...</p>),這樣的標註介面會有以下缺點:
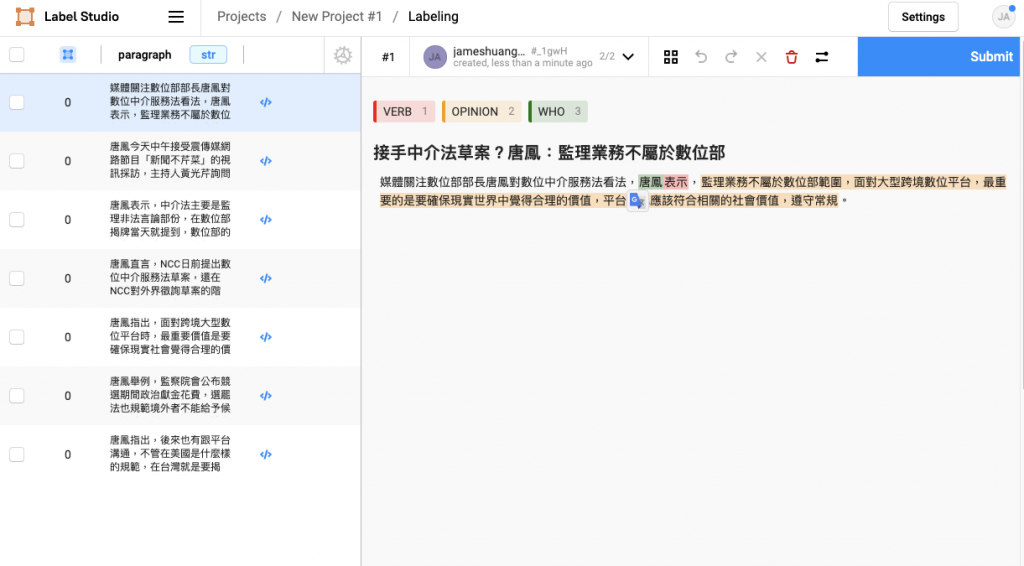
<p>...</p>),在要標註多篇新聞時就需要不停切換標註頁面,很沒有效率。為了解決上述缺點,我做了改進後的標註介面,如下圖所示: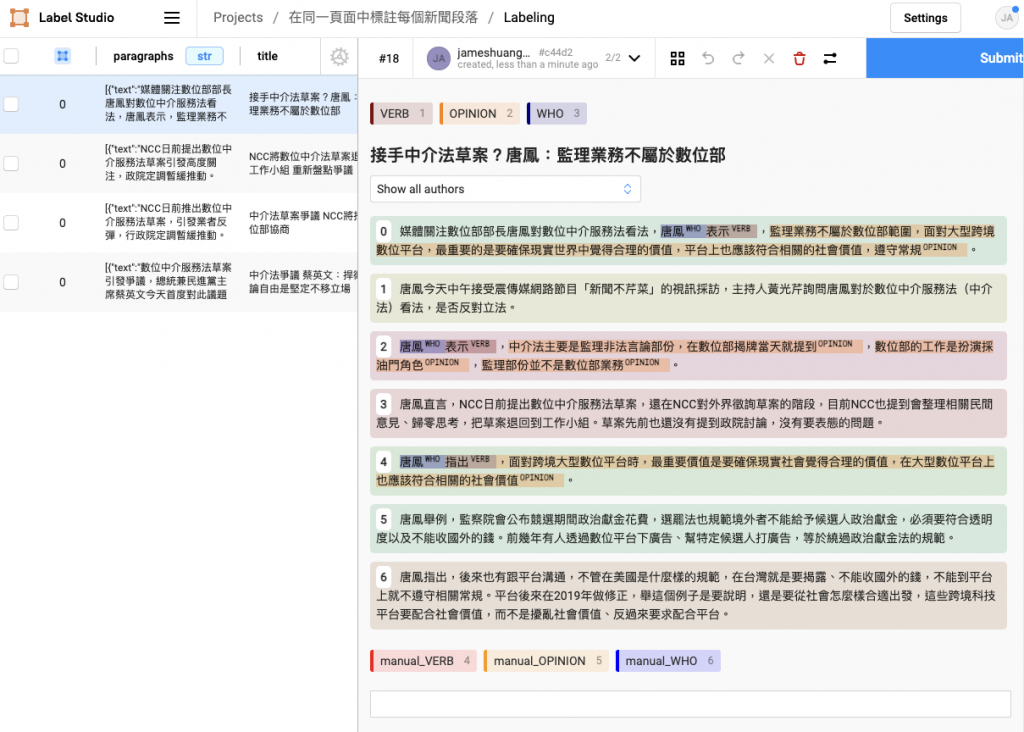
改進後的標註介面具備以下優點:
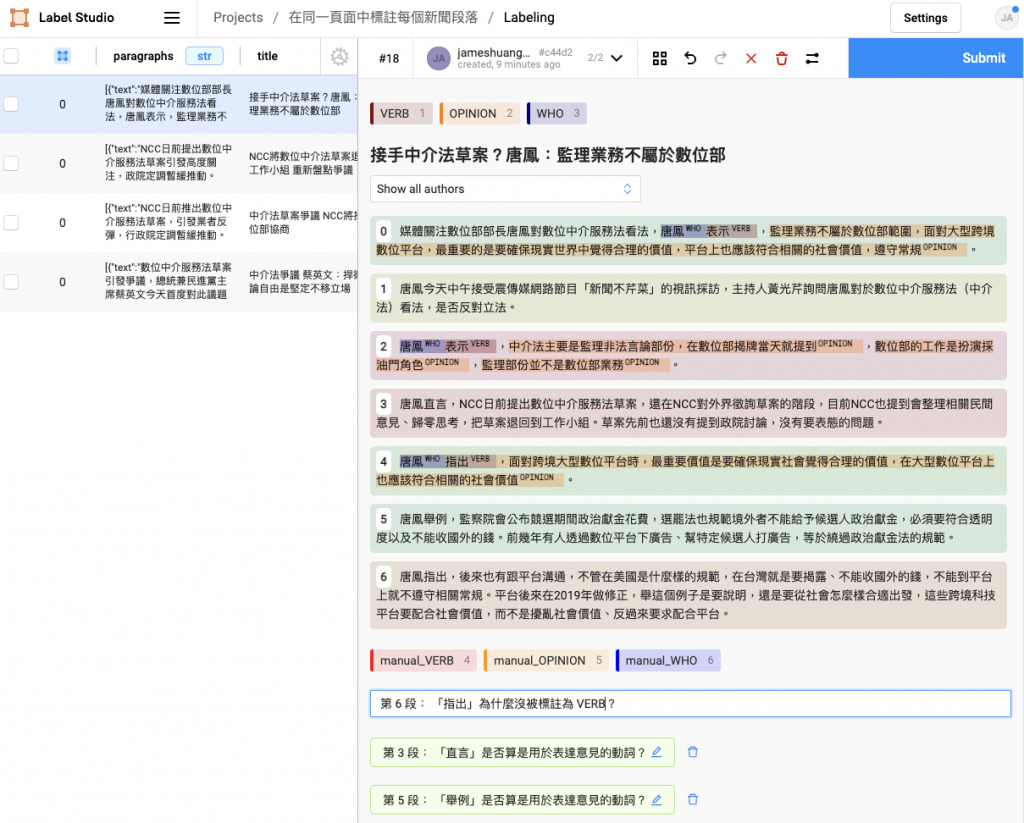
這樣的註記尤其重要,能讓我一次將所有新聞檢查完,再回頭分析有什麼預先標註做不好的 case。
我將昨天介紹的程式碼改成下列程式碼,大致上只改動迴圈以及標註結果紀錄的格式,適用昨天的解說因此不再多加贅述。
注意:先將每篇新聞內容以
List[str]的形式儲存,所以多篇新聞會帶有List[List[str]]的格式,在下面的程式碼中被命名為data
import stanza
import spacy_stanza
from ckip_transformers.nlp import CkipPosTagger, CkipNerChunker
import spacy
from spacy import displacy
from spacy.tokens import Span
from spacy.matcher import DependencyMatcher
from itertools import chain
import json
import uuid
stanza.download("zh-hant")
nlp = spacy_stanza.load_pipeline("xx", lang='zh-hant')
def add_ner(doc):
ner_driver = CkipNerChunker(model="bert-base")
ner = ner_driver([str(doc)], show_progress=False)
ner_spans = []
for entity in ner[0]:
span = doc.char_span(entity.idx[0], entity.idx[1], label=entity.ner)
if span is None:
span = doc.char_span(entity.idx[0], entity.idx[1] + 1, label=entity.ner)
ner_spans.append(span)
orig_ents = list(doc.ents)
doc.ents = orig_ents + ner_spans
def add_ckip_tag(doc):
pos_driver = CkipPosTagger(model="bert-base")
words = [[str(token) for token in doc]]
pos = pos_driver(words, show_progress=False)
for token, ckip_pos in zip(doc, pos[0]):
token.tag_ = ckip_pos
version = "v0"
pattern = [
{
"RIGHT_ID": "VE",
"RIGHT_ATTRS": {"TAG": "VE"}
},
{
"LEFT_ID": "VE",
"REL_OP": ">",
"RIGHT_ID": "who_root",
"RIGHT_ATTRS": {"DEP": "nsubj"}
},
{
"LEFT_ID": "VE",
"REL_OP": ">",
"RIGHT_ID": "idea_root",
"RIGHT_ATTRS": {"DEP": {"IN": ["ccomp", "parataxis"]}}
}
]
matcher = DependencyMatcher(nlp.vocab, validate=True)
matcher.add(f"{version}", [pattern])
pre_annotations = []
final_docs = []
for article in data[:1]:
title = article['title']
content = article['content']
final_docs = []
for doc in nlp.pipe(content):
pre_annotation_data = {
"data": {
"title": title,
"paragraph": str(doc)
},
"predictions": [
{
"model_version": f"{version}",
"result": []
}
]
}
add_ner(doc)
add_ckip_tag(doc)
matches = matcher(doc)
matches_sorted = sorted(matches, key=lambda x: abs(x[1][0] - x[1][1]))
if len(matches_sorted) > 1:
matches_sorted = [match for match in matches_sorted if (match[1][0] == matches_sorted[0][1][0] and match[1][1] == matches_sorted[0][1][1])]
if len(matches_sorted) > 0:
first_match = matches_sorted[0]
VE_id = first_match[1][0]
who_root_id = first_match[1][1]
VE_span = Span(doc, VE_id, VE_id+1, label="VERB")
who_root_span = Span(doc, doc[who_root_id].left_edge.i, doc[who_root_id].right_edge.i+1, label="WHO")
idea_spans = []
for match in matches_sorted:
match_id, token_ids = match
idea_root_id = token_ids[2]
idea_spans.append(Span(doc, doc[idea_root_id].left_edge.i, doc[idea_root_id].right_edge.i+1, label="OPINION"))
doc.spans["sc"] = spacy.util.filter_spans([VE_span, who_root_span] + idea_spans)
for span in doc.spans["sc"]:
print(span.text, span.label_)
pre_annotation_data["predictions"][0]["result"].append(
{
"id": str(uuid.uuid1()),
"from_name": "opinion_label",
"to_name": "a_paragraph",
"type": "labels",
"value": {
"start": span.start_char,
"end": span.end_char,
"text": span.text,
"labels": [
span.label_
]
}
}
)
else:
doc.spans["sc"] = []
final_docs.append(doc)
pre_annotations.append(pre_annotation_data)
html = displacy.render(final_docs, style="span", jupyter=False, page=True)
file_name = f"idea_html/{version}/{title}.html"
with open(f"{file_name}", "w") as f:
f.write(html)
import json
with open(f"pre_annotations_{version}.json", "w") as f:
json.dump(pre_annotations, f, ensure_ascii=False)

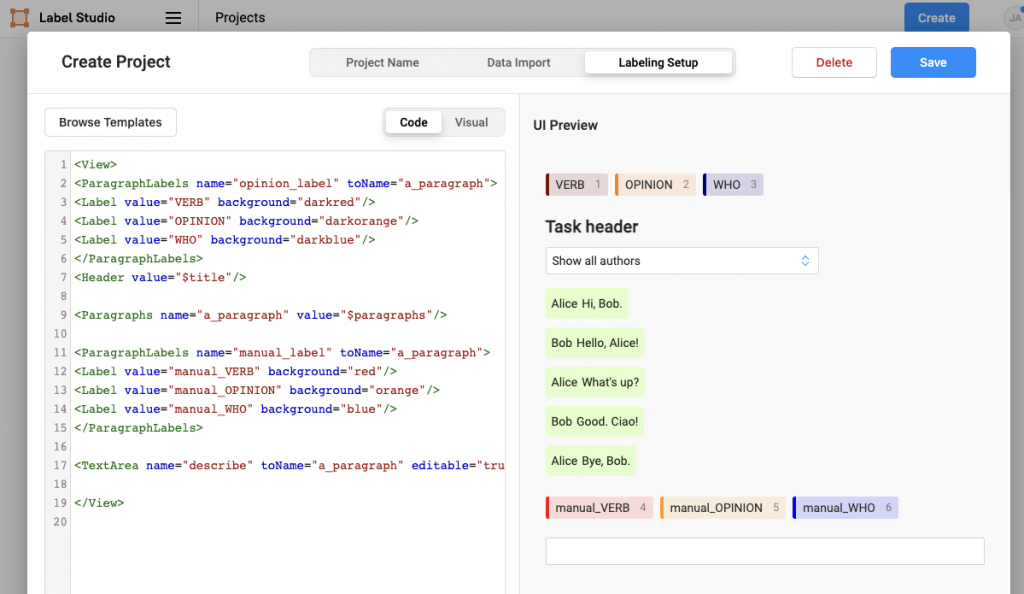
注意:這步驟選擇上一段程式碼所產生的 json 標註檔案。
選擇左下角藍色 Custom template 來自定義標註介面。
將 template 的 html 替換成下方的配置:
<View>
<ParagraphLabels name="opinion_label" toName="a_paragraph">
<Label value="VERB" background="darkred"/>
<Label value="OPINION" background="darkorange"/>
<Label value="WHO" background="darkblue"/>
</ParagraphLabels>
<Header value="$title"/>
<Paragraphs name="a_paragraph" value="$paragraphs"/>
<ParagraphLabels name="manual_label" toName="a_paragraph">
<Label value="manual_VERB" background="red"/>
<Label value="manual_OPINION" background="orange"/>
<Label value="manual_WHO" background="blue"/>
</ParagraphLabels>
<TextArea name="describe" toName="a_paragraph" editable="true"/>
</View>
最後按下右上角的藍色 Save 就完成標註 Project 的建立了!
現在看起來人工標註需要的介面已經處理的差不多了,接下來就要想辦法利用這個標註介面來改進找出意見持有者、意見動詞、意見句範圍的方法(程式碼)。
我大致構思了一下接下來要進行的工作,如下所列: