
在前面的幾天裡,我們認識了很多關於資源配置以及監控的觀念,但如果我們掌握了這些資源指標卻只能手動調整就感覺失去了靈魂一樣,於是就有了自動化資源配置的 AutoScaling 出現, AutoScaling 簡單來說就是圍繞在你設定的資源配置並監控資源使用率去對系統做出水平、垂直、多維擴展或縮減來應對系統負載的波動,但需要再次強調的是,這一切都是建立在已經設定好資源配置以及 Metrics Server 為前提才能實現~。
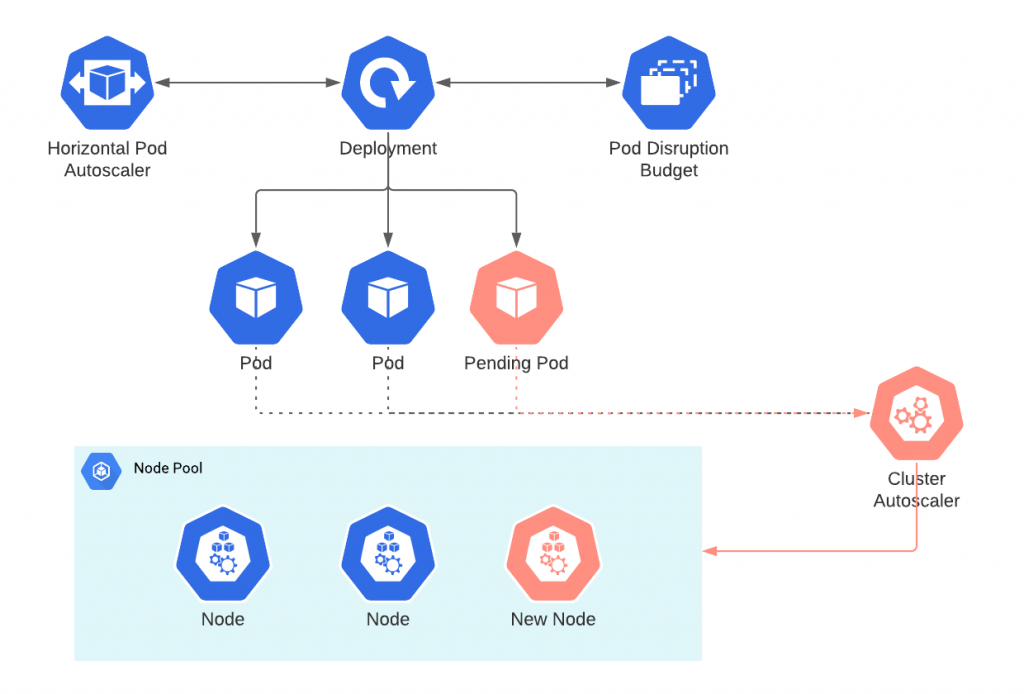
Cluster Autoscaler 最主要的工作就是調節 node-pool 的數量,是屬於 cluster level 的 autoscaler,簡單來說他能幫我們在負載高時開新的 node,負載低時關閉 node。
Pod 的狀態為 unschedulable 的十秒左右時將會迅速的判斷是否需要縱向擴展,需要注意的是縱向擴展的動作可以在十秒內左右完成,而開啟機器的時間可能需要數分鐘到十來分鐘才能處於可用狀態。Pod 或 Node 調度條件限制。"cluster-autoscaler.kubernetes.io/scale-down-disabled": "true"
就像是上面有提到的 Cluster Auotscaler 是屬於集群等級的調節者,所以我們在本地只有一個 node 的 docker-desktop 是沒辦法實際體驗到他的厲害之處,如果我們使用的是平台等級的 Kubernetes ,像是 Gcp GKE Aws EKS 等等,此類雲端平台整合更全面的資源並做出更高層級的自動調度。
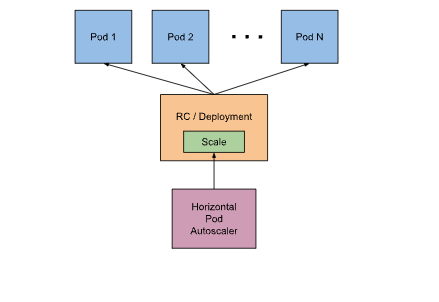
調節 Pod 數量的 autoscaler,屬於 pod level ,負責在負載波動時自動擴展或縮減 Pod 到設定的最大數量以及最小數量。
Scale-up: 檢查 metrics server,發現過了設定使用率就增加 deployment 的 replicas。
Scale-down: 檢查 metrics,發現過了設定使用率就減少 deployment 的 replicas。
如果 deployment 原本就有設定 replica 數目將會被 HPA 的 replica 設定覆蓋,等於是 HPA 將會無視 deployment 設定對 Pod 數量擴展縮減。
進行擴展或縮減後都會等待三到五分鐘到系統穩定後,再開始檢查 metrics server。
使用率計算:如果 currentMetricValue是 200m ,而 desiredMetricValue
是 100m,則代表目前要增加 200/100 = 2 倍的 replica 的數量。
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
可以設定 custom/external metrics 來觸發 autoscaling。
v2beta2 以上的 HPA 才有內存可以檢查,v1 只能檢查 CPU utilization。
目前 HPA 的 Api 更新的非常快,網路上的範例可以找到 v1、v2、v2beta2…等版本的範例教學,但只有從 v2beta2 開始才支援 metric 內存,所以還是建議多翻閱最新的 API 文件。
自動推薦並設定最適合 pod resource requests/limits 的設定,簡單來說就是不再需要透過人工監控並且手動設定 CPU 和內存配置,可以替沒有系統調優相關經驗的 DevOps 小白鬆了一口氣。
Updater 再檢查到該 Pod 需要更新時,必須要將原本的 Pod 刪除並重新建立一個更新過 reqeusts/limits 的 Pod。history data。VPA 跟 Metrics Server 一樣都是
custom resources,代表他們不一定會預設安裝在Kubernetes當中。但很多核心功能都仰賴這些custom resources來實現,這一切都讓Kubernetes更加模組化。
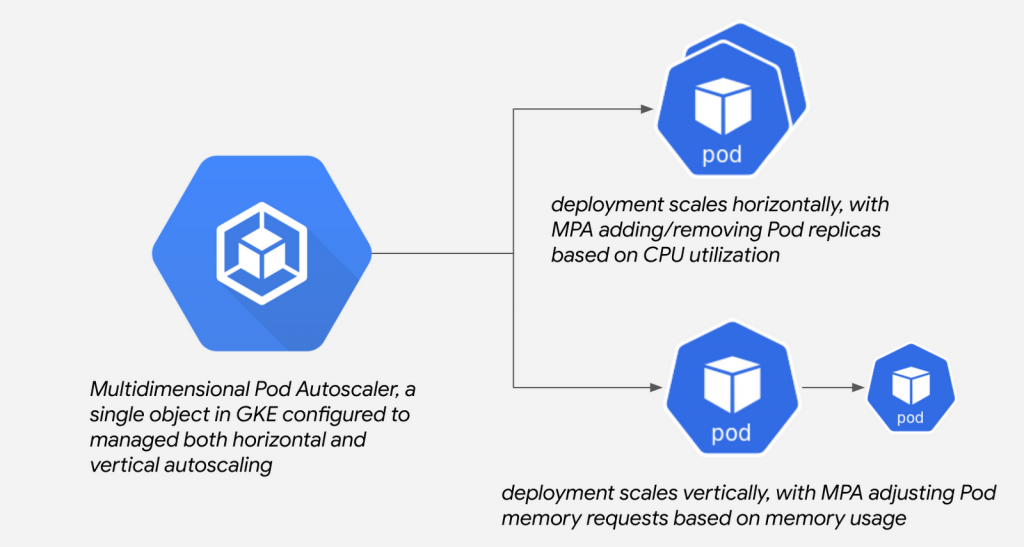
MPA (多維 Pod 自動擴縮) 可以讓我們同時選擇多種方法來擴縮集群,目前只有 GCP GKE 有提供這種多維度的擴縮操作,在偉栽 Google 爸爸的之外也體會到了,因為 Kubernetes 開源社群中的 autoscaler 專案還沒實現多維擴縮 ,所以各大雲端平台都不支持並且都在等開源社群生出新功能再包進自己的雲端平台裡,非常的邪惡~
GCP GKE 限定,無法在本地或其他平台中實現。GCP GKE 屬於 beta 版本,有興趣可以在非正式環境中玩玩看。『根據 CPU 進行 HPA,以及根據內存進行 VPA』 ,所以要注意一下這邊不同於 VPA 的設定在於 `在 deployment 的 resources 中的 cpu requests/limits 是必須要事先設定的欄位,因為目前的 VPA 只能依據內存進行 VPA。有興趣的可以參考參考官方文件來玩玩看。
大略介紹完了 AutoScaling 的種類,可以發現不管到哪裡資源的監控以及配置都是必修課題,畢竟沒有一個老闆願意多花一分冤枉錢,同時我們也可以觀察到 Kubernetes 在這一部分很多地方都需要仰賴 custom resources 來實現,並且這些功能都不能說到完善的階段,迭代是非常非常的快,只能送他老話一句:『別再更新了,老子學不動啦!』
千呼萬喚始出來!鐵人賽系列「從異世界歸來發現只剩自己不會 Kubernetes」同名改編作品出版了!
感謝所有交流指教的各路英雄,也感謝願意點閱文章的各位,如果能幫助到任何人都將會是我的榮幸。
本書內容改編自第 14 屆 iThome 鐵人賽 DevOps 組的優選系列文章《從異世界歸來發現只剩自己不會 Kubernetes》。此書是一本綜合性的指南,針對想要探索認識 Kubernetes 的技術人員而生。無論是初涉此領域的新手,還是已有深厚經驗的資深工程師,本書都能提供你所需的知識和技能。
「這本書不僅提供了豐富的範例程式碼和操作指南,讓身為工程師的我們能實際操作來加深認知;更重要的是,它教會我如何從後端工程師的角度去思考和應用 Kubernetes。從容器的生命週期、資源管理到部署管理,每一章都與我們的日常開發工作息息相關。」
──── 雷N │ 後端工程師 / iThome 鐵人賽戰友
天瓏連結: 從異世界歸來發現只剩自己不會 Kubernetes:初心者進入雲端世界的實戰攻略!
相關程式碼同時收錄在:
https://github.com/MikeHsu0618/2022-ithelp/tree/master/Day25
Reference
Configuring multidimensional Pod autoscaling
Scale container resource requests and limits
Kubernetes Autoscaling: 3 Methods and How to Make Them Great
Kubernetes Horizontal Scaling/Vertical Scaling 概念
Kuberenetes Autoscaling 相關知識小整理
Scale-up: 檢查 metrics,發現過了設定使用率就「減少」 deployment 的 pod 的 resources.requests,再透過重啟 Pod 實際更新。
謝謝分享~
此處是否為筆誤,應該是「增加」?
沒錯~感謝幫忙指正!
