
在前面的種類介紹中我們知道了HPA 的精隨就在於如何在適時的自動擴縮避免資源空轉或負載過高,常常見到的情境差不多就像是搶票系統、訂餐系統…等,可以想像這些服務都屬於在某個特定時段都會迎接一段大量服務需求的尖峰,像是午餐時間可以大膽斷定熊貓外送服務用的人一定多到爆炸 XD,雖然大部分的尖峰時刻是可以預期的,但我們就一定需要我們的 DevOps 每天都在特定時間提高服務負載能力嗎?那如果今天的負載是突如其來不可預期的呢?難道這時候就只能準備主機板出來跪了(?,還好我們有 Kubernetes 的 autoscaler 自動化管理服務擴縮,使我們在面對服務尖峰時能夠在短短十來秒中馬上做出反應,接下來利用 HPA 實際練習來加深我們的概念吧。
在進行之前,我們需要擁有一個已配置 Metrics Server 的 Kubernetes 集群用來收集各種資源指標當作 autoscaling 的依據。
kubectl top node
-------
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
docker-desktop 258m 6% 5717Mi 72%
如果還沒有安裝的朋友可以參考前面 Metrics Server 篇來安裝。
在上一篇中我們對了 HPA 概念已經有了不少的著墨,但實際上在網路上關於 HPA 的 API 設定檔對於其他資源來說可以說相對少很多,所以這裡整理了大致上會使用到的一些實用參數。
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
- type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: 1k
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
name: main-route
target:
type: Value
value: 10k
- type: External
external:
metric:
name: queue_messages_ready
selector:
matchLabels:
queue: "worker_tasks"
target:
type: AverageValue
averageValue: 30
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 15
- type: Pods
value: 4
periodSeconds: 15
selectPolicy: Max
一些重要的設定參數:
apiVersion :autoscaling/v2beta2 後開始可以使用 metrics server 中的 memory 當作擴縮指標。
spec.minReplicas/maxReplicas :定義最小或最大的 replica,不能設定 0。
spec.metrics :定義需要監控的資源,及其搭配的使用量調整。
type:
resource:resource 是指Kubernetes已知的資源指標,此結構描述當前擴縮目標中的每個 Pod 的 CPU 或內存。pods :pods 是指當前擴縮目標的每個 Pod 的指標,再與目標值進行比較前,這些比較將被平均。
pods.metric.selector :selector 可以直接看作是 labelSelector ,可以用來指定需要獲取的具體指標範圍。未設置時,僅以 metricName 參數用於收集資源指標。object :object 是指單個 Kubenetes 對象的指標,例如範例中的 Ingress 。
metrics.object.describedObject :describeObject 中指定足夠的信息來讓你辨別所引用的資源。object.metric.selector :此 selector 跟上述的用法相同,用以約束更明確的收集資源指標範圍。external :external 是指以非 Kubenetes 對象當作指標,外部度量指標使得你可以使用你的監控系統的任何指標來自動擴縮你的集群。你需要在 metric 塊中提供 name 和selector 。{resource/pods/object/external}.(resource).target:
type :定義特定指標的目標值、平均值或平均利用率, type 表示指標類別是Utilization、Value或AverageValue。averageUtilization:averageUtilization 是跨所有相關Pod 得出的資源指標均值的目標值, 表示為Pod 資源請求值的百分比。目前僅對“Resource” 指標源類別有效。averageValue:averageValue 是跨所有Pod 得出的指標均值的目標值(以數量形式給出)。value:value 是指標的目標值(以數量形式給出)。behavior :以上為官方預設值,建議不太需要去改動
stabilizationWindowSeconds:當指標顯示目標應該縮容時,自動擴縮算法查看之前計算的期望狀態,並使用指定時間間隔內的最大值。就是說會在過去5分鐘內選擇期望值最高的一個值,是為了防止副本數抖動的過於頻繁。{scaleUp/scaleDown}.policy:代表每隔一段 periodSeconds 的時間,副本數變化最多不會超過 Percent 或 Pods 定義的數量。接下來我們就用官方範例來探討一下細節。
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
replicas: 1
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: registry.k8s.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 500m
memory: 512Mi
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
# hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
來建立起資源吧:
kubectl apply -f ./deployment.yaml
kubectl apply -f ./hpa.yaml
接下來我們將運行壓力測試指令查看 pod 的 HPA 狀況:
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
--------
If you don't see a command prompt, try pressing enter.
OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!
執行 HPA 監控:
kubectl get hpa --watch
------
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/80%, <unknown>/50% 1 10 1 3s
php-apache Deployment/php-apache 1%/80%, 0%/50% 1 10 1 33s
php-apache Deployment/php-apache 1%/80%, 0%/50% 1 10 1 48s
php-apache Deployment/php-apache 1%/80%, 98%/50% 1 10 3 63s
php-apache Deployment/php-apache 2%/80%, 29%/50% 1 10 3 94s
php-apache Deployment/php-apache 2%/80%, 33%/50% 1 10 3 2m4s
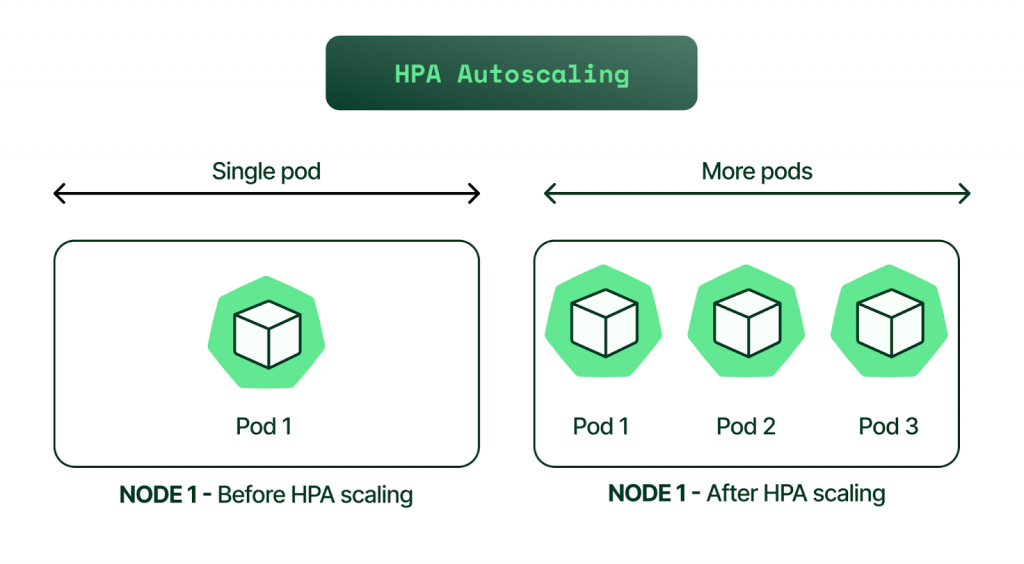
成功看到系統成功水平擴展並且分散服務負擔~
在我們簡單的練習 HPA 後,相信大夥也對 HPA 有了更深的一層體會,但還是必須強調資源監控以及調度實在是一們很深的學問, Kubernetes 的 HPA 確實可以提供給我們最基本的容器擴縮功能,可是在真正的大流量正式環境中需要更細緻的設定和更多的依賴外部資源指標,例如在某些熱點新聞的高流量下2分鐘內就需要擴容上千台機器, Kubernetes 默認的彈性擴容是解決不了這個問題的,這時候有些人就會想到 Grafana 與 Prometheus 這套監控組合神拳(遠目,只能說繼續學習下去遲早有天會可以輪到他們的。
千呼萬喚始出來!鐵人賽系列「從異世界歸來發現只剩自己不會 Kubernetes」同名改編作品出版了!
感謝所有交流指教的各路英雄,也感謝願意點閱文章的各位,如果能幫助到任何人都將會是我的榮幸。
本書內容改編自第 14 屆 iThome 鐵人賽 DevOps 組的優選系列文章《從異世界歸來發現只剩自己不會 Kubernetes》。此書是一本綜合性的指南,針對想要探索認識 Kubernetes 的技術人員而生。無論是初涉此領域的新手,還是已有深厚經驗的資深工程師,本書都能提供你所需的知識和技能。
「這本書不僅提供了豐富的範例程式碼和操作指南,讓身為工程師的我們能實際操作來加深認知;更重要的是,它教會我如何從後端工程師的角度去思考和應用 Kubernetes。從容器的生命週期、資源管理到部署管理,每一章都與我們的日常開發工作息息相關。」
──── 雷N │ 後端工程師 / iThome 鐵人賽戰友
天瓏連結: 從異世界歸來發現只剩自己不會 Kubernetes:初心者進入雲端世界的實戰攻略!
相關文章:
相關程式碼同時收錄在:
https://github.com/MikeHsu0618/2022-ithelp/tree/master/Day26
Reference
HorizontalPodAutoscaler Walkthrough
Kubernetes Horizontal Scaling/Vertical Scaling 概念
