
DLI Getting Started with AI on Jetson Nano 第三部分 Image Regression 影像回歸。大家應該有聽過 數值的迴歸分析,但影像回歸就比就少見了!影像回歸算是相當有趣 ,即便他可能實用性不算太好(喂) 。可以用來定位圖像上特徵的座標,後面在 Jetbot 專案上也有使用到,並且能讓我們再熟悉一下 CNN 神經網路。Let’s GO!
臉部特徵回歸 (source: Unsplash)
在前一篇影像分類中模型最終的輸出結果是 N 個類別的可能性,其可能性加總為1。而本次影像回歸的範例試圖找出人臉中鼻子、左眼、右眼的位置,因此各須要 X 與 Y 座標去標記,也因此神經網路的輸出要有六個數值,分別是三個特徵值的 X-Y 座標,加總並不會等於1。
而在模型設定基本上和影像分類大同小異,也是使用遷移學習並且調整後面全連接層的輸出,可以自由選用要選用哪個模型來使用。只不過誠如前段敘述,輸出的數值會由 n 個類別,改為 n 個特徵值乘2。
device = torch.device('cuda')
output_dim = 2 * len(dataset.categories) # x, y coordinate for each category
# ALEXNET
# model = torchvision.models.alexnet(pretrained=True)
# model.classifier[-1] = torch.nn.Linear(4096, output_dim)
# SQUEEZENET
# model = torchvision.models.squeezenet1_1(pretrained=True)
# model.classifier[1] = torch.nn.Conv2d(512, output_dim, kernel_size=1)
# model.num_classes = len(dataset.categories)
# RESNET 18
model = torchvision.models.resnet18(pretrained=True)
model.fc = torch.nn.Linear(512, output_dim)
# RESNET 34
# model = torchvision.models.resnet34(pretrained=True)
# model.fc = torch.nn.Linear(512, output_dim)
model = model.to(device)
此外在損失函數的計算也會有所不同,由於每個訓練資料都會標記特徵的 X-Y 座標,CNN 模型算出的 X-Y 座標和實際 X-Y 座標的差異,就是我們的誤差了。(如圖所示)

損失函數計算 (source: NVIDIA Developer youtube channel)
依序執行程式碼直到 “顯示互動式工具!” 段落,就會顯示互動式的 widget 可以進行操作。加入訓練資料的方式須選擇好資料集 dataset 與類別 category,然後在即時預覽的影像畫面中點選特徵位置,完成就會看到一個圓圈就是被選定的 X-Y 座標。 依序標記鼻子、左眼、右眼的位置,各標記 40~50 張。
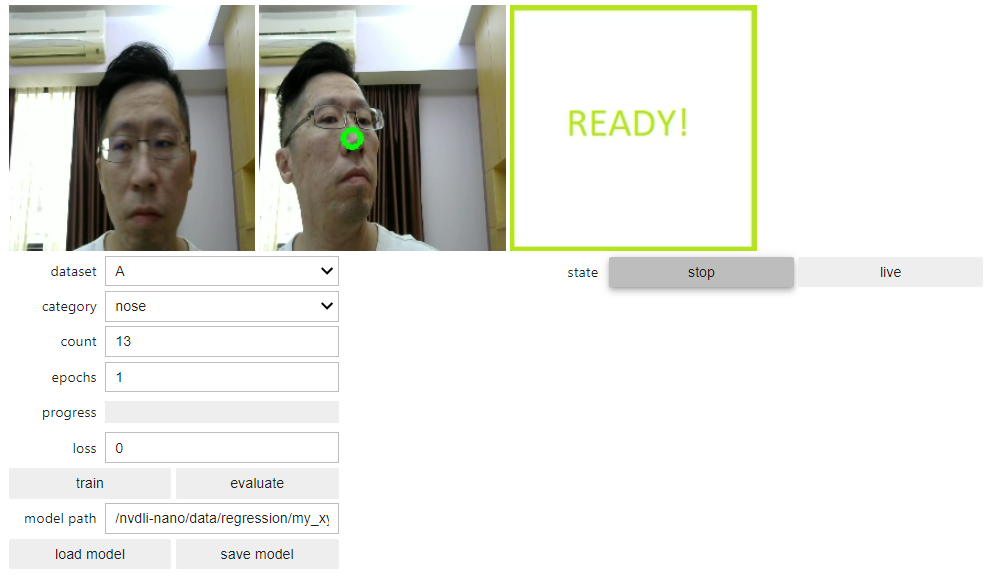
另外值得一提的是,不知道各位有沒有注意到,我們所表記的特徵座標這個 meta 資料,是如何儲存的呢?在這範例中使用了一個小 trick ,在儲存影像資料時,所儲存的檔案名稱的格式為 xxx_yyy_UUID.jpg。也就是直接把這 meta 放在檔名的前輟,之後再訓練模型時,只要再把這個前輟 X-Y 座標分離出來即可。這樣的方式可以省去額外的 meta file,並且在 meta 資料量小的情境相當好用,可以偷偷學起來!
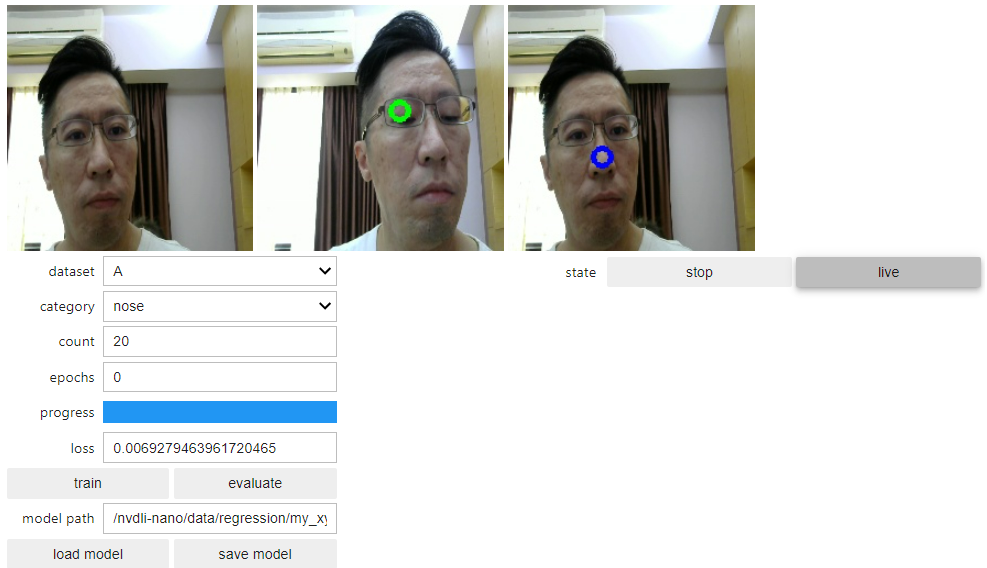
模型訓練次數 epochs 一樣可以先抓 5~10 次看看效果如何可以再行重複訓練,訓練完成的模型一樣可以儲存為 pytorch 的模型檔,並且可以使用 live 功能做即時的監看,看看模型算出來特徵座標是否滿意。若是效果不滿意,則須要回去調整資料集,也許是標記特徵的 X-Y 座標有誤差,或是資料量不夠,都有可能影響模型的輸出結果,這部分就留給各位去嘗試看看了!
DLI - Getting Started with AI on Jetson Nano 到這篇就告一段落了,這兩個範例都是使用 pytorch,即使各位沒有相關經驗,但用到的呼叫都不至於太複雜,稍微閱讀一下應該都還可以理解。同時也預告一下,在 NVIDIA Jetson 家族中,範例多會以 pytorch 為主。最後希望各位可以透過這些簡單的範例體驗一下 Edge AI,並且完成課程後面的試題順利拿到電子證書!

