如果有跟著上一篇文章操作的話,相信大家已經訓練好自己的模型 best.pt 了。這次就是要教大家如何使用自己的模型做推論,並經由TensorRT,針對自己的模型與硬體做加速。事不宜遲,讓我們馬上開始!
TensorRT (source: NVIDIA)
YOLOv5 官方文件其實提供了幾個方法,讓使用者可以使用自己的模型(Custom Model),那在這邊我們就用熟悉的方式「detect.py」來執行。
依照前一天文章執行完 Colab 程式碼後,訓練完成的模型應該會儲存在「Downloads」資料夾內。
請將這個「best.pt」模型,複製到「yolov5」資料夾內。待會兒我們將會用程式,呼叫這個模型。
接著打開終端機,並輸入下方指令進到 yolov5 資料夾內。
cd yolov5
與之前在測試 YOLOv5 模型時一樣,我們會呼叫 detect.py 程式,請輸入下方指令呼叫我們自己的模型做推論。比對之前的指令可以發現,只是替換掉 --weights 後面的模型名稱而已,是不是超簡單。
python3 detect.py --weights best.pt --source 0 --nosave
等待程式執行後,就能看到顯示結果與推論資訊。趕緊將自己想要辨識的物體放到攝影機前,看看模型是否能正確辨識。
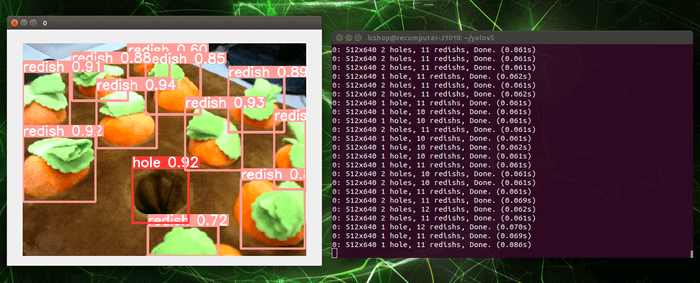
查看終端機內的資訊,可以看到每推論一幀影像,會需要花費約 61ms 的時間。那有沒有機會加速推論時間呢?有的,我們可以借助 TensorRT。
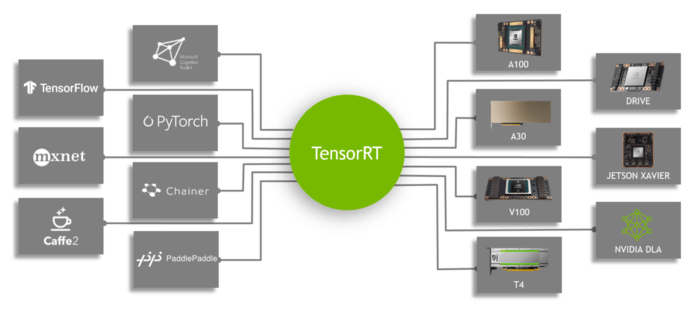
TensorRT 是 NVIDIA 針對自己的產品所做的一個工具,主要目的在於協助使用者的模型,能更快更有效的取用自家 GPU 資源,並透過一些優化程序,加速模型的推論。由下圖可以看到,它支援現今常見且流行的神經網路框架。
優化的項目如下圖所示,共有六項。透過轉換模型降低精度,以及優化模型結構,並針對使用的硬體做優化。這裡有個特別的重點,就是針對硬體優化這件事,也就是說大家若是在 Jetson Nano 上,執行了 TensorRT 優化模型,那麼產生出來的模型檔案 模型名稱.engine ,就不能複製到其他不同的硬體做使用。

TensorRT 特色 (source: NVIDIA)
知道 TensorRT 的好處後,當然要直接將我們的模型轉換一波呀!轉換的方法也相當簡單,YOLOv5
官方程式碼有提供轉換程式 export.py ,這個程式提供使用者能將自己的 YOLOv5 模型轉換成不同的格式,其中就包括 TensorRT 的 .engine 檔案。
但在轉換成 .engine 檔案的過程中,會需要先將 Pytorch 的 .pt 轉換成 .onnx ,再由 .onnx 轉換成我們要的 .engine 檔案。ONNX(Open Neural Network Exchange)是一套開放神經網路交換格式,在安裝 YOLOv5 的時候並沒有安裝相關軟體,所以在轉換前,我們需要先手動安裝 ONNX 相關套件。
首先要安裝相依套件,請打開終端機並輸入下列指令。
sudo apt install protobuf-compiler libprotoc-dev
過程中會需要使用者同意,請輸入「y」並按下 Enter 同意安裝。
接著請輸入下列指令安裝 Cython。
pip3 install Cython --user
最後安裝 onnx,這邊需要指定版本,請輸入下列指令安裝。
pip3 install onnx==1.9.0 --user --verbose
安裝完成後如下所示:
轉換模型之前我們需要新增「標籤」對應檔案,附檔名是「yaml」,這個檔案清楚寫明我們這個模型辨識的類別數量,與每個辨識到的類別名稱是什麼。
請在 yolov5 資料夾底下,輸入下列指令開啟文字編輯器,新增 labels.yaml 檔案:
gedit labels.yaml
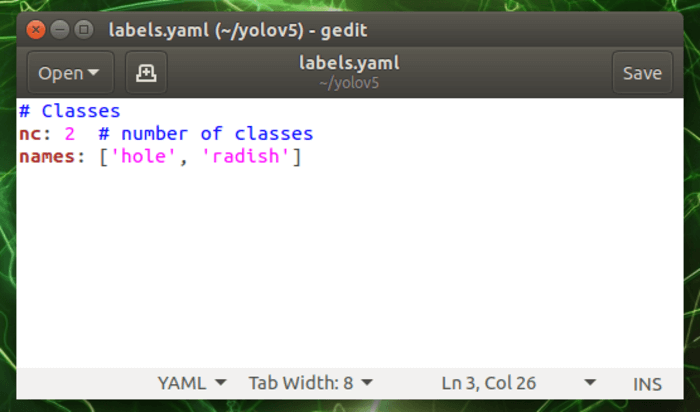
請參照下列文件格式,依照自己的模型修改內容。
# Classes
nc: 2 # number of classes
names: ['hole', 'radish']
若需要的辨識數量是 3 種,請修改 nc: 後方的數字,例如:nc: 3 。然後在 names: 後方的陣列中新增自己的標籤名稱,比方說您的模型可以辨識到三種水果,請在陣列當中放入個水果名稱的字串,並用逗號隔開,例如: names: [‘strawberry’, ‘orange’, ‘banana’] 。以此類推,修改完成後請存檔,並關閉視窗。
OK~一切準備就緒,模型有了、標籤檔案有了以及 onnx 也安裝了,接下來讓我們輸入以下指令,開始轉換我們的模型。
python3 export.py --weights best.pt --data labels.yaml --include engine --half --device 0
指令當中的 --data 後方就是填入我們的標籤檔案, --include 後方則是填入要轉換的模型類型,因為要轉換的是 TensorRT,所以是 engine 。--half 則是我們要將原先的辨識精度 FP32 下調成
FP16,以下修精度換得速度的方式加快推論時間。最後的「–device」後方則是填入使用的 GPU 編號,它會依照使用的 GPU 做硬體優化,Jetson Nano 只有一個 GPU,編號是 0。
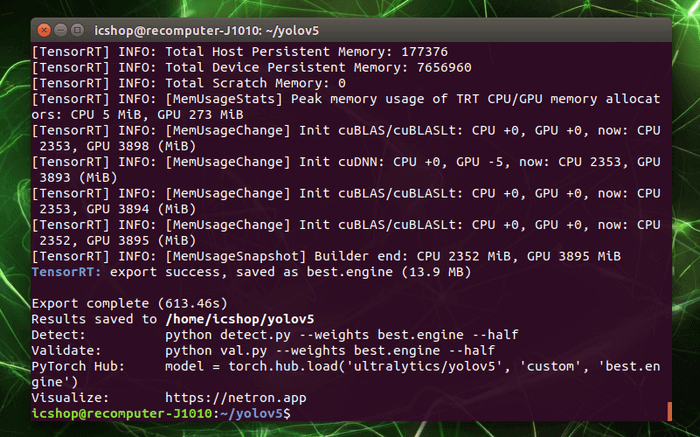
轉換過程需要很長一段時間,轉換完畢後如下圖所示,內容顯示筆者這次轉換時間需要 613.46 秒,將近 10 分鐘多。以及提供相關資訊,例如轉換後的檔案放在哪,該怎麼使用模型……等。
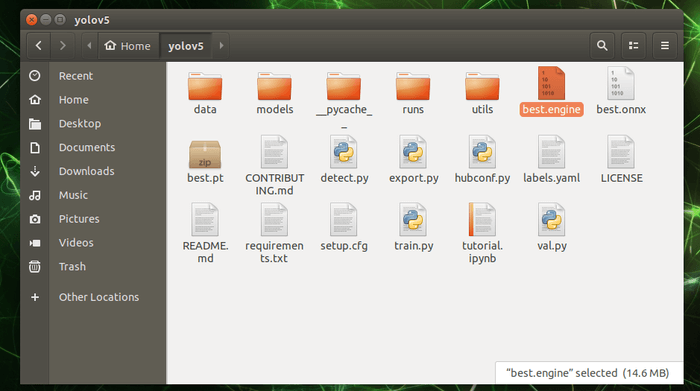
實際來到 yolov5 資料夾,可以找到轉換後的 engine 檔案 best.engine ,以及轉換過程產出的 onnx 檔案 best.onnx 。
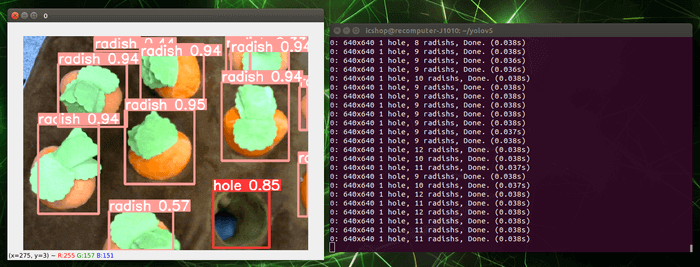
獲得優化後的 best.engine 檔案後,馬上來測試一下效果如何吧!請輸入以下指令:
python3 detect.py --weights best.engine --half --data labels.yaml --nosave --source 0
一樣將 --weights 後方更改為我們的 engine 檔案 best.engine ,並加入 --half 表示模型精度為 FP16,以及新增 --data 輸入標籤檔案 labels.yaml。實際執行後,可以看到推論速度大幅提升,處理每幀的時間下降到約 38ms,是不是相當驚人!
綜合以上,在 Jetson Nano 運行 YOLOv5 這段落就算完結了,從環境的安裝、資料的標記、訓練模型、到這篇 TensorRT 加速,相信大家已經對在 Jetson Nano 上面,使用 YOLOv5 做物件辨識有所了解。若您手邊還有 NVIDIA Jetson 系列效能更好的 Jetson Xavier NX 或是最新的 Jetson AGX Orin 等,都可以試著以相同的步驟運行 YOLOv5喔!
您好~想請教一些問題
我是使用Jetson TX2
輸入
python3 detect.py --weights best.pt --source 0 --nosave
後出現
Traceback (most recent call last):
File "detect.py" , line 45, in «module> from models.common import DetectMultiBackend File " /home/nvidia/yolov5/models/common. py
, line 26, in module>
from torch. cuda import amp
ImportError: cannot import name
'amp'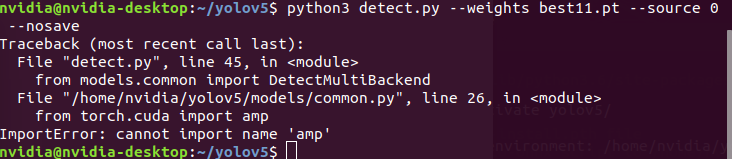
想知道這樣如何解決~
謝謝!
Hi oakley77,
在 TX2 應該是差不多的,可以先確認一下 JetPack 版本以及 torch 與 torchvision 版本喔!
這篇操作是 JetPack 4.6 以上, pytorch 與 torchvision 要使用 NVIDIA 官方提供的版本。

