在前天訓練資料建好之後,我們就可以展開來比較不同model所帶來的效果,以下舉2層DNN、2層simple RNN、以及1層CNN加2層LSTM的結果:
2層DNN非常簡單,每層維度用10:
# Build the model
model_DNN = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, input_shape=[window_size], activation="relu"),
tf.keras.layers.Dense(10, activation="relu"),
tf.keras.layers.Dense(1)
])
optimizer用SGD,learning rate設定1e-7,這是依據最複雜最後一個1層CNN加2層LSTM的模型,試跑後所找到穩定的值,由於要做比較,所以我們都同樣用這個值。此外我們loss改都用Huber,然後跑500次:
# Set the learning rate
learning_rate = 1e-7
# Set the optimizer
optimizer = tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=0.9)
# Set the training parameters
model_DNN_SGD.compile(loss=tf.keras.losses.Huber(),
optimizer=optimizer,
metrics=["mae"])
# Train the model
history_DNN_SGD = model_DNN_SGD.fit(train_set, epochs=500)
訓練的loss和MAE結果: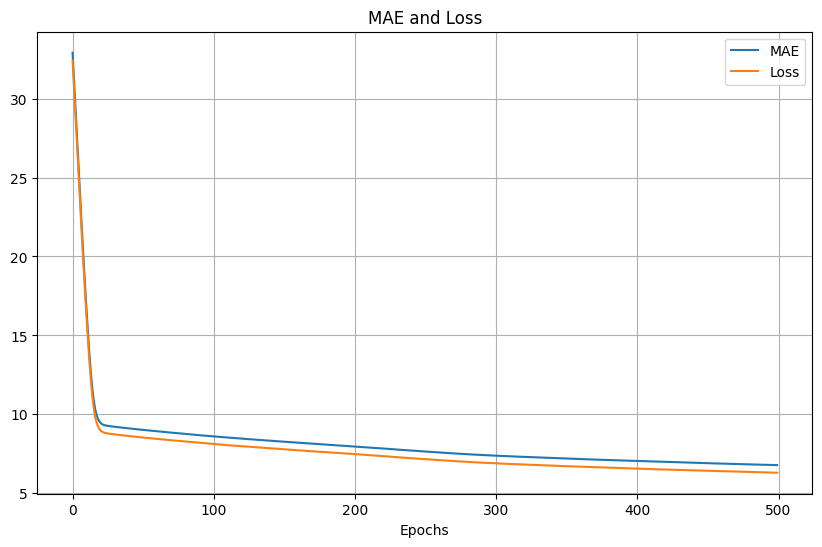
測試的MSE和MAE:
MSE: 82.141624
MAS: 6.5242624
測試的預測結果: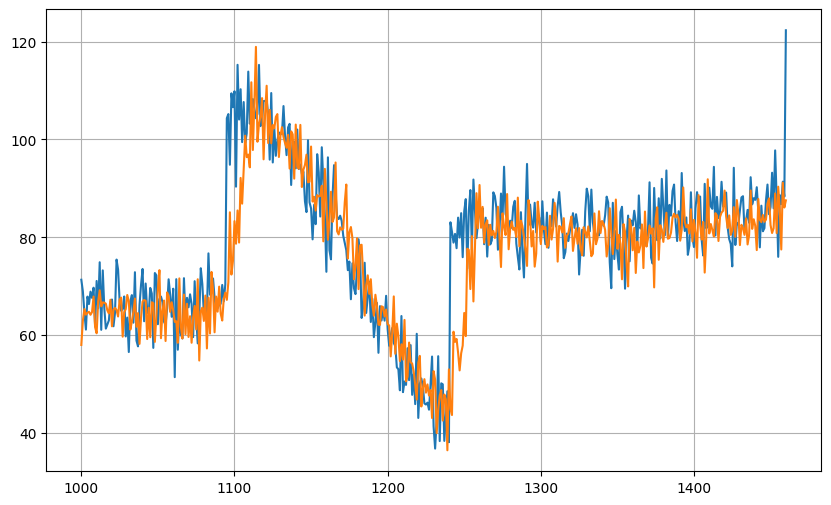
然後改用Adam,同樣learning rate為1e-7,500次,訓練的loss和MAE結果:
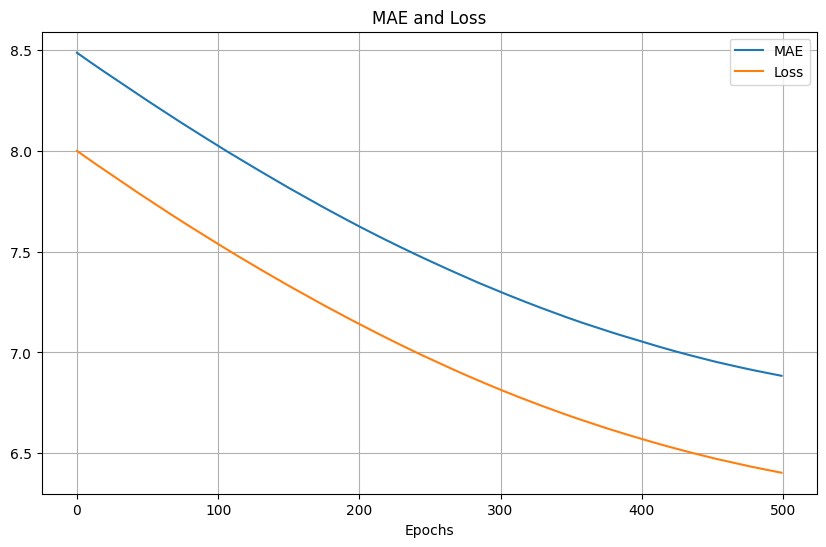
測試的MSE和MAE:
MSE: 90.19746
MAS: 6.6611605
測試的預測結果: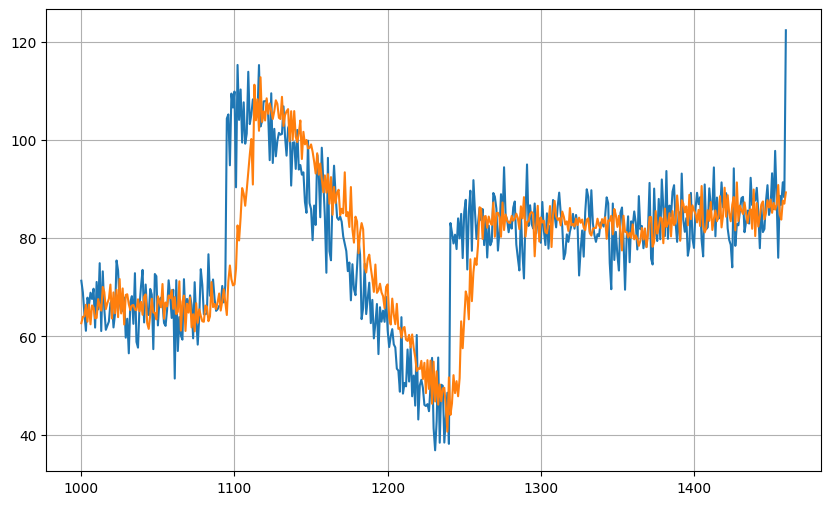
接著是2層simple RNN,把原本的dense換成 SimpleRNN,每層的維度設40,而第一層的Lambda是重塑輸入資料格式的維度用的,而最後一層是做scaler用,這是剛好一個示範也可以在層裡面用lambda:
# Build the Model
model_RNN = tf.keras.models.Sequential([
tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, axis=-1),
input_shape=[window_size]),
tf.keras.layers.SimpleRNN(40, return_sequences=True),
tf.keras.layers.SimpleRNN(40),
tf.keras.layers.Dense(1),
tf.keras.layers.Lambda(lambda x: x * 400.0)
])
500次SGD,learning rate為1e-7,訓練的loss和MAE結果: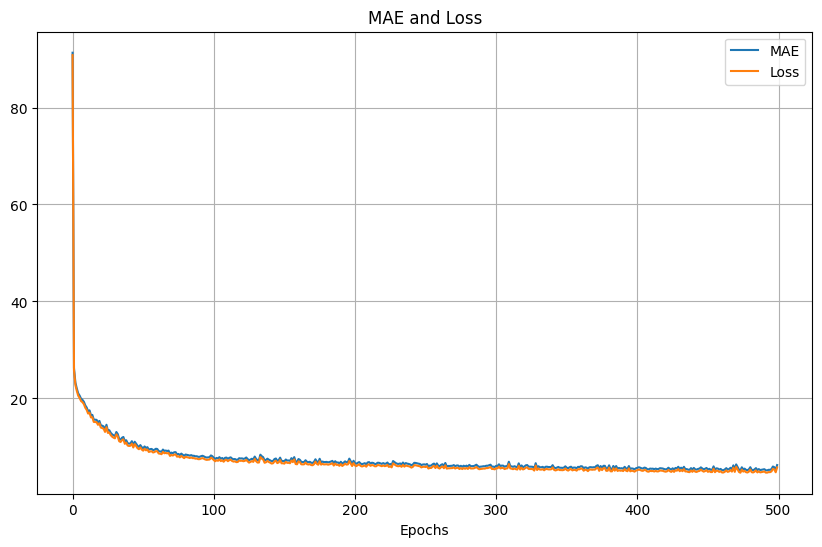
放大200次epoch後的結果,可以看到會有抖動: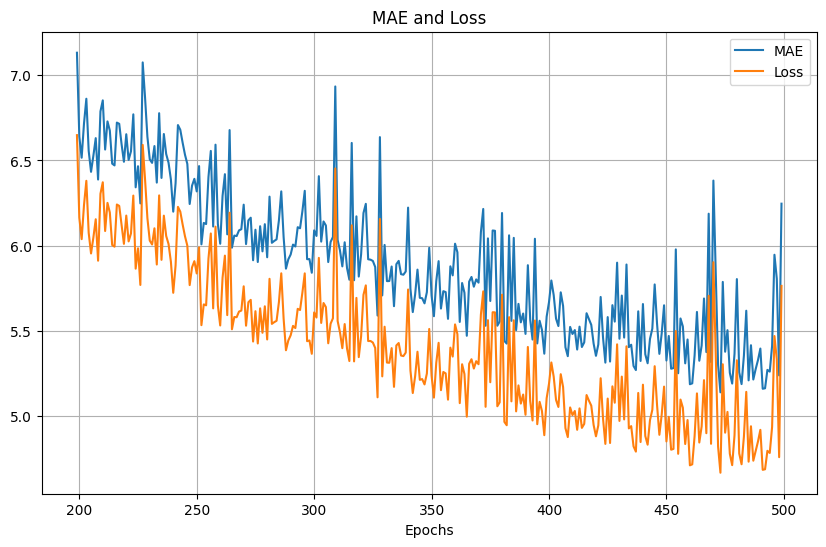
測試的MSE和MAE:
MSE: 47.233025
MAS: 4.9751453
測試的預測結果:
500次Adam,同樣的learning rate,訓練的loss和MAE結果: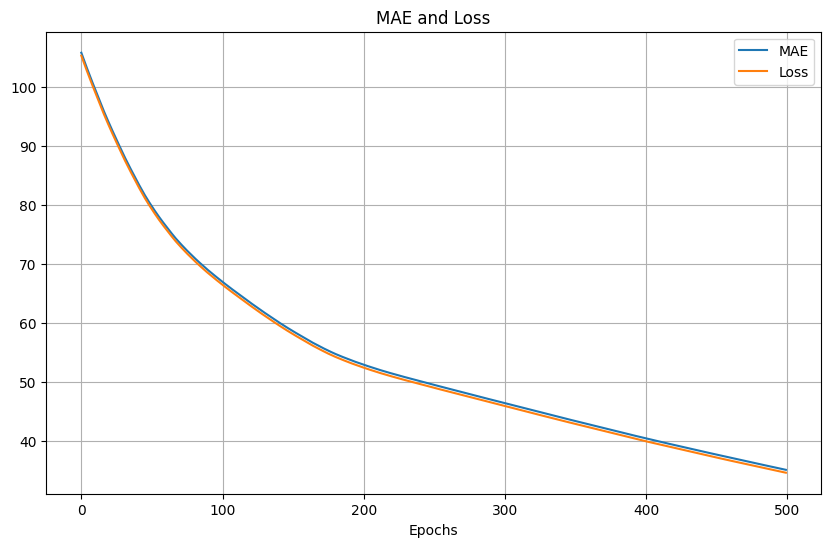
放大200次epoch後的結果,可以看到是平滑的: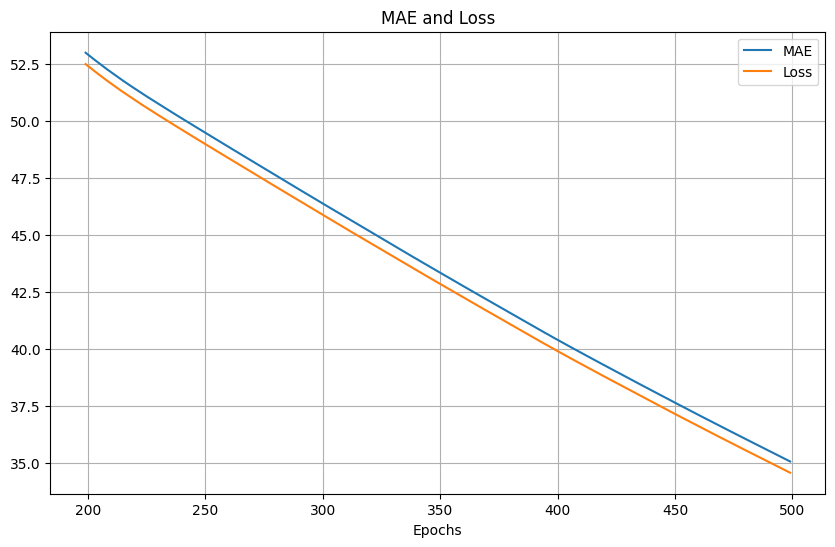
測試的MSE和MAE:
MSE: 234.12042
MAS: 13.546093
測試的預測結果: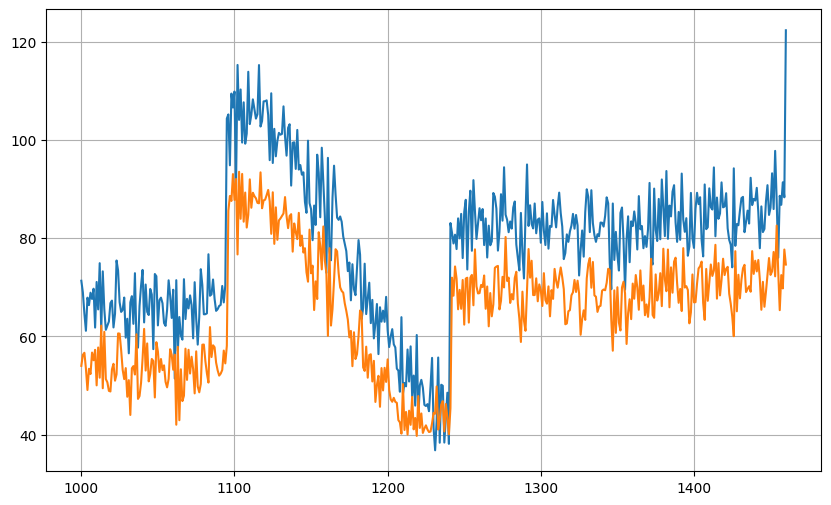
單用2層的LSTM的結果和再加1層CNN並沒有顯著的差異,所以我們直接來最終版:
# Build the model
model_conv_LSTM = tf.keras.models.Sequential([
tf.keras.layers.Conv1D(filters=64, kernel_size=3,
strides=1, padding="causal",
activation="relu",
input_shape=[window_size, 1]),
tf.keras.layers.LSTM(64, return_sequences=True),
tf.keras.layers.LSTM(64),
tf.keras.layers.Dense(1),
tf.keras.layers.Lambda(lambda x: x * 400)
])
同樣是500次SGD,learning rate為1e-7,訓練的loss和MAE結果: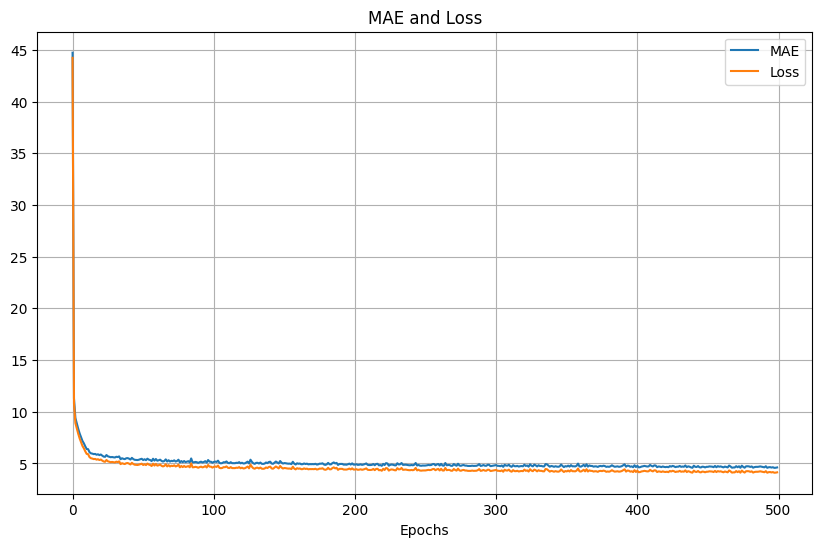
放大200次epoch後的結果,同樣可以看到會有抖動: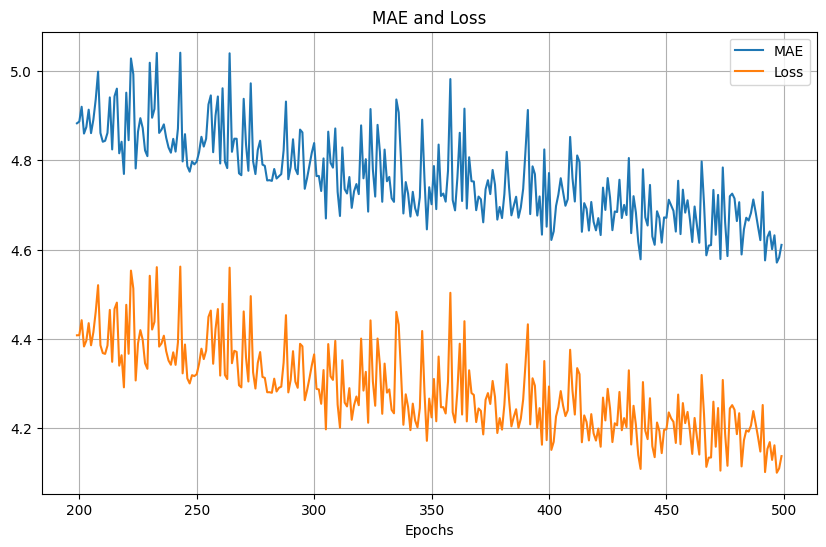
測試的MSE和MAE:
MSE: 58.39372
MAS: 5.611397
測試的預測結果,使用LSTM在預測高凸的區域會低於的情況: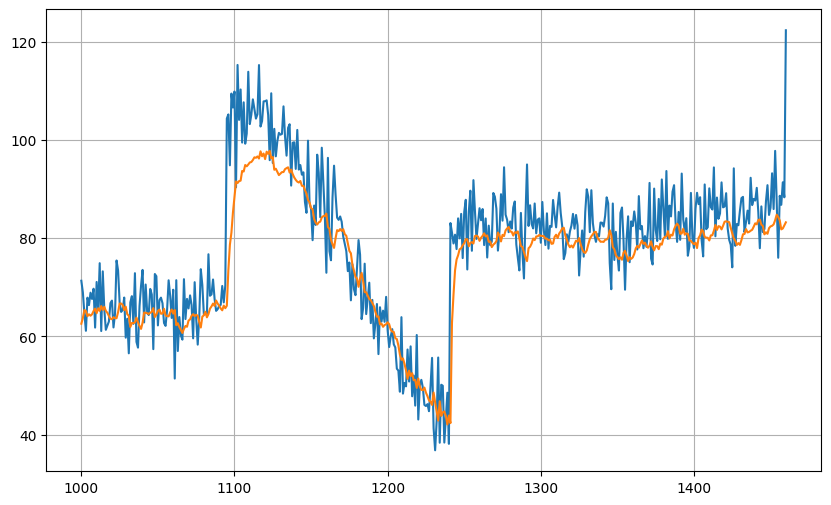
500次Adam,learning rate同樣為1e-7,可以看到訓練的loss和MAE結果比較平滑,但相對比SGD慢: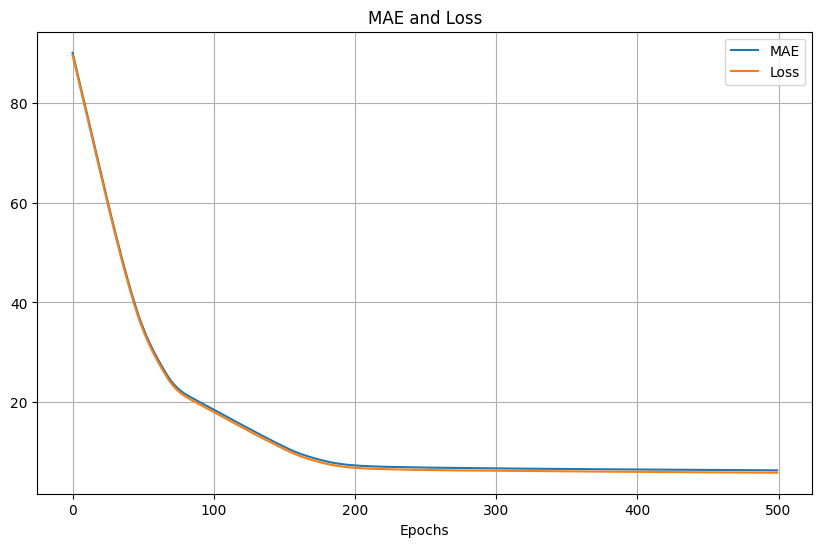
放大200次epoch後的結果,同樣可以看到是平滑的: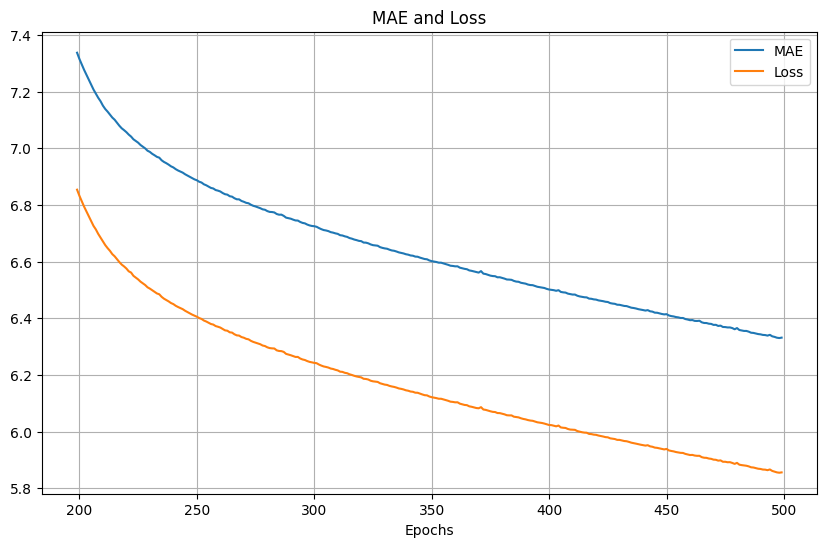
測試的MSE和MAE:
MSE: 121.120.95319
MAS: 8.065572
測試的預測結果: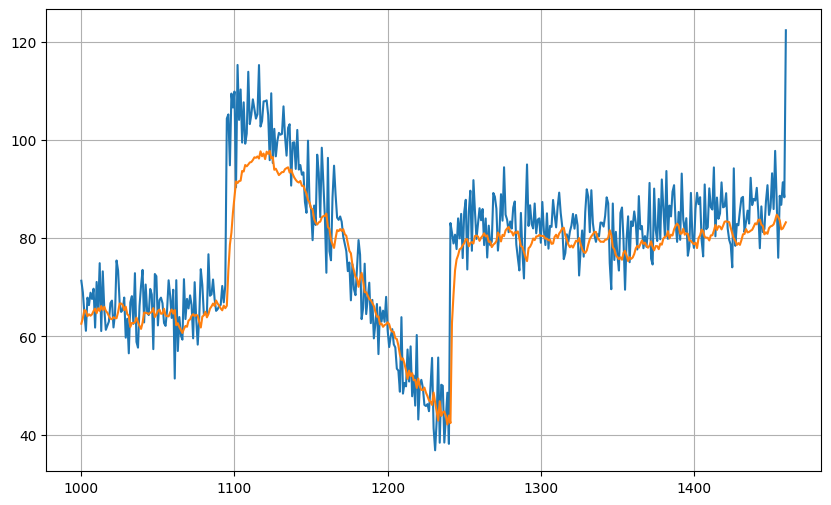
結論比較明確的是Adam在loss表現較SGD平滑但緩慢。以及各種模型的範本,而模型由於並未搭配其他參數去反覆比對測試,所以error量的大小僅供參考。


 iThome鐵人賽
iThome鐵人賽