不知不覺鐵人賽好像快看到終點了 ...... 今天讓我們繼續處理 Data Pipeline 。
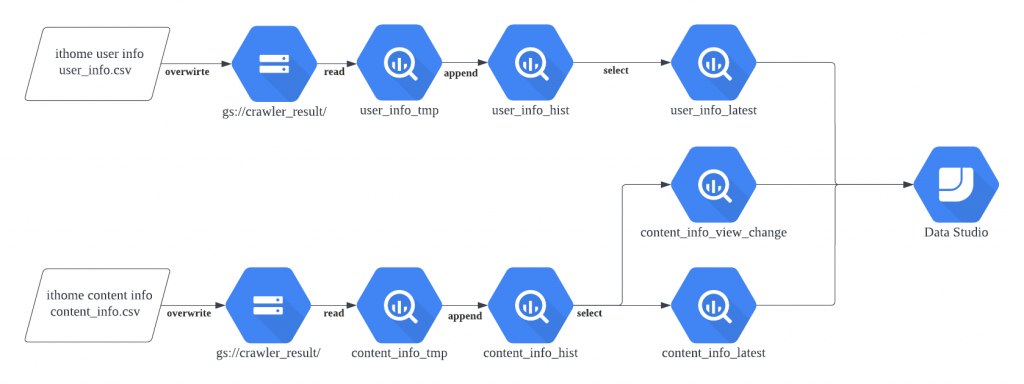
由於這次我們會將最終結果以 Google Data Studio (GDS) 呈現,因此為了讓這個 Side Project 更加豐富,所以我們決定讓 GDS 的 Data Source 為 BigQuery。
在資料喂進 bigquery 前,我們會先將資料上傳到 Google Cloud Storage (GCS),再將資料同步(External Table)到 bigquery 中。
首先,我們要將資料上傳 GCS 可以在 command line 執行以下指令,則可將資料由本地 DATA_PATH 上傳到 GCS 的 gs://BUCKET/PATH 中。
gcloud alpha storage cp {{ DATA_PATH }} gs://{{ BUCKET }}/{{ PATH }}
對應我們 Jenkinsfile 的 stage 會是
stage('Data pipeline') {
matrix {
axes {
axis {
name 'DATA'
values 'user_info', 'content_info'
}
}
stages {
......
stage("Push to GCS"){
steps{
sh """
gcloud alpha storage cp output/${DATA}/${DATA}.csv gs://crawler_result/ithome/ironman2022
"""
}
}
}
}
}
接著我們要讓 BigQuery 吃到 Google Cloud Storage 的資料。
在 GCP 的 BigQuery 頁面中,選擇新增資料 (+ ADD DATA),資料來源我們選擇 Google Cloud Storage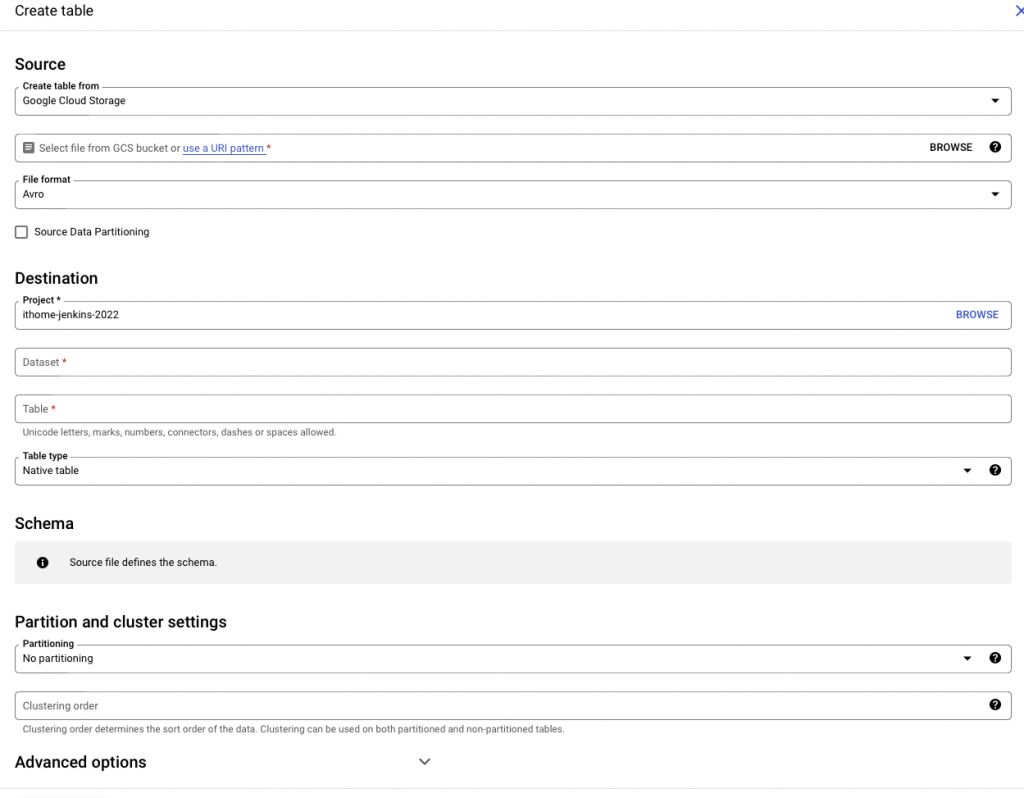
依序設定
抑或是可以用 command line 的方式進行 external table 的建立
>> bq mkdef --source_format=CSV gs://crawler_result/ithome/ironman2022/user_info.csv
{
"csvOptions": {
"allowJaggedRows": false,
"allowQuotedNewlines": false,
"encoding": "UTF-8",
"fieldDelimiter": ",",
"preserveAsciiControlCharacters": false,
"quote": "\"",
"skipLeadingRows": 0
},
"sourceFormat": "CSV",
"sourceUris": [
"gs://crawler_result/ithome/ironman2022/content_info.csv"
]
}
將上面的設定檔寫入 external_user_info_def 中
bq mkdef --source_format=CSV gs://crawler_result/ithome/ironman2022/user_info.csv > external_user_info_def
bq mk --table --external_table_definition=external_user_info_def \ ithome.user_info_tmp \
_id:INTEGER,crawl_datetime:TIMESTAMP,user_id:INTEGER,user_name:STRING,ithome_level:STRING,ithome_point:INTEGER,user_viewed:INTEGER,user_followed:INTEGER,ask_question:INTEGER,article:INTEGER,answer:INTEGER,invitation_answer:INTEGER,best_answer:INTEGER
在完成上述設定後,即可在主畫面看到方才建立的 user_info_tmp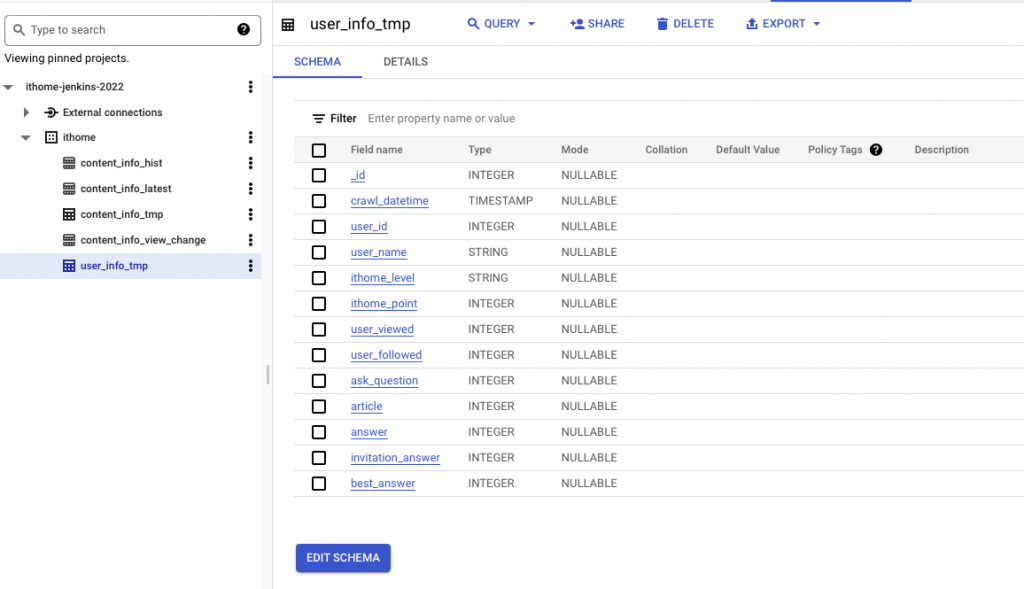
我們可以嘗試使用 BigQuery 提供的 SQL 互動式對話窗下
SELECT * FROM `ithome-jenkins-2022.ithome.user_info_tmp` WHERE user_name='BenLiu' LIMIT 1
來稍微驗證一下資料有被寫入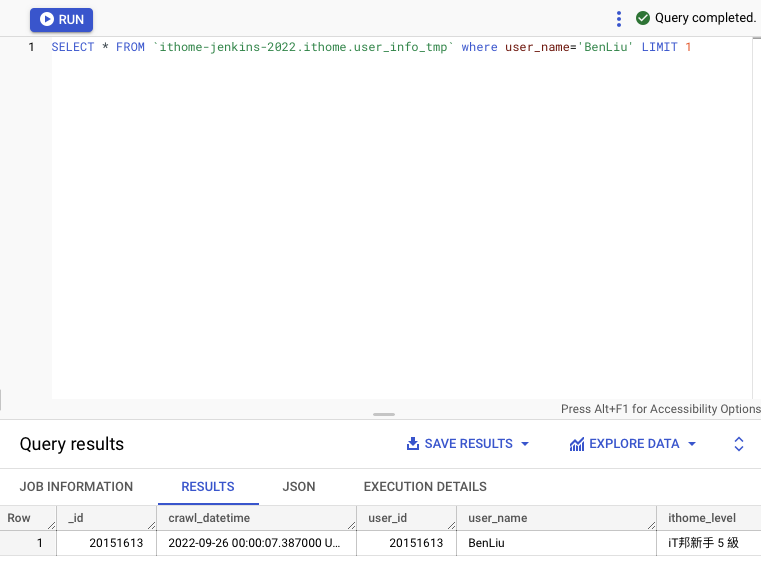
同樣的方式我們也建立 content_info_tmp,並也驗證一下資料是否有被寫入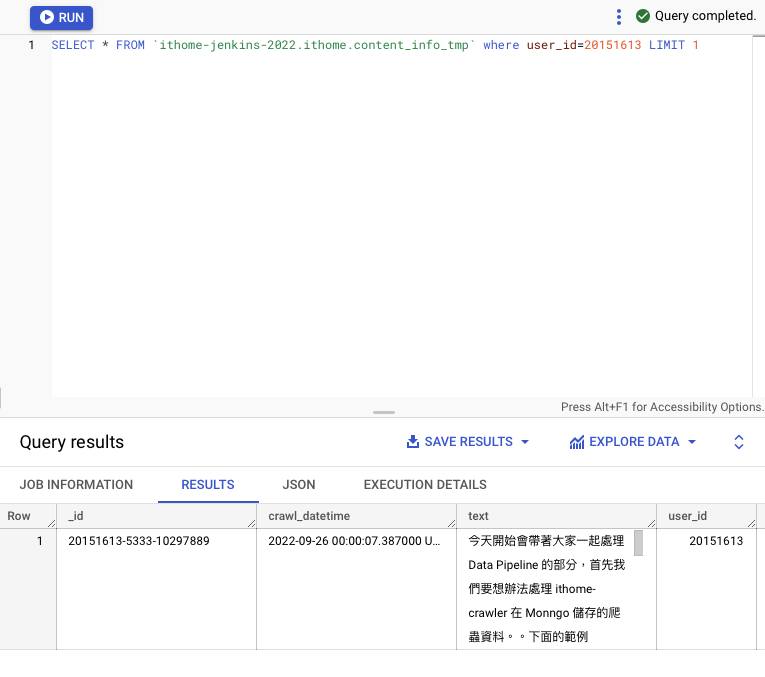
今日我們完成將資料從本地上傳到 GCS ,再由 GCS 以 external table 的方式,將資料同步到 content_info_tmp 與 user_info_tmp 兩張 BigQuery Table 中。明日我們將會繼續以 BigQuery 的 command line (bq)將資料一步步彙整到歷史資料表(history table) ,再從歷史資料表將資料客製化成 GDS 所需要的資料格式。
私心覺得在使用上 GCS/ BigQuery 的感覺非常像 HDFS/ Hive,因為以前沒有使用過 BigQuery,所以在設計 Data pipeline 的設計上,完全是把它當成 Hive 在做,所以有任何錯誤歡迎糾正我。
https://cloud.google.com/bigquery/docs/visualize-data-studio

