在目前為止,老頭介紹了 jax.numpy、jax.jit、jax.grad、jax.vmap、Pytree 和 JAX 控制流程,以這些為基礎,我們可以試著設計並訓練一個簡單的 MLP 神經網路模型 [30.1]。
[按 : 老頭在此就不說明 MLP 是什麼?相信會學習 JAX 的讀者,不會有人不知道它。]
以下的貼文是由 colab 筆記本挎貝過來的,讀者可以直接打開 colab 閱讀並執行它(在這裏)。
首先,把需要的程式庫 import 進來。
import jax
import jax.numpy as jnp
import jax.tree_util as jtree
import jax.random as jrand
import matplotlib.pyplot as plt
# layer_widths: 指定 MLP 的層數和每層的神經元個數
# 用法: [1st_layer_width, 2nd_layer_width, ..., nth_layter_width]
def init_mlp_params(layer_widths):
params = []
key = jrand.PRNGKey(0)
for n_in, n_out in zip(layer_widths[:-1], layer_widths[1:]):
key, subkey = jrand.split(key)
params.append(dict(weights=jrand.normal(subkey, (n_in, n_out)) * jnp.sqrt(2/n_in),
biases=jnp.ones(shape=(n_out,))))
return params
# 定義模型的層數及神經元個數
layers = [1,128,128,1]
params = init_mlp_params(layers)
# 檢查 params 的結構
jtree.tree_structure(params)
output:
PyTreeDef([{'biases': *, 'weights': *}, {'biases': *, 'weights': *}, {'biases': *, 'weights': *}])
# 檢查 params 葉節點的 shape
jtree.tree_map(lambda x: x.shape, params)
output:
[{'biases': (128,), 'weights': (1, 128)},
{'biases': (128,), 'weights': (128, 128)},
{'biases': (1,), 'weights': (128, 1)}]
# 檢查 params 葉節點的 type
jtree.tree_map(lambda x: (x.__class__, x.dtype), params)
output:
[{'biases': (jaxlib.xla_extension.DeviceArray, dtype('float32')),
'weights': (jaxlib.xla_extension.DeviceArray, dtype('float32'))},
{'biases': (jaxlib.xla_extension.DeviceArray, dtype('float32')),
'weights': (jaxlib.xla_extension.DeviceArray, dtype('float32'))},
{'biases': (jaxlib.xla_extension.DeviceArray, dtype('float32')),
'weights': (jaxlib.xla_extension.DeviceArray, dtype('float32'))}]
(1) 激活函式 activation function
(2) 損失函式 loss function
(3) 參數調整函式 update function, based on grad()
# 激活函式, 及模型前向計算
# ======================================================================
# 由第一層開始, 依序計算輸出, 並以 relu 為激活函式
def forward(params, x):
*hidden, last = params
for layer in hidden:
x = jax.nn.relu(x @ layer['weights'] + layer['biases'])
return x @ last['weights'] + last['biases']
# 損失函式
# ======================================================================
# x : 為訓練資料
# y : 為資料標籤 (label)
# ======================================================================
# loss 為均方誤差(Mean square error,MSE)
# ======================================================================
def loss_fn(params, x, y):
return jnp.mean((forward(params, x) - y) ** 2)
# 參數調整函式
# ======================================================================
# 在還沒有介紹 JAX 提供的方法之前, 先用最簡單的邏輯
@jax.jit
def update(params, x, y, learning_rate=0.0001):
grads = jax.grad(loss_fn)(params, x, y)
# Note that `grads` is a pytree with the same structure as `params`.
# `jax.grad` is one of the many JAX functions that has
# built-in support for pytrees.
# This is handy, because we can apply the SGD update using tree utils:
return jax.tree_map(
lambda p, g: p - learning_rate * g, params, grads
)
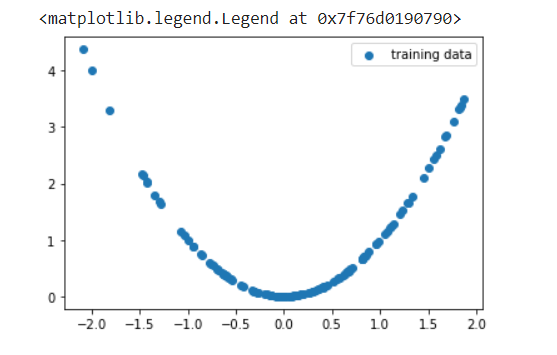
key = jrand.PRNGKey(100)
xs = jrand.normal(key, (128,1))
ys = xs ** 2
plt.scatter(xs, ys, label='training data')
plt.legend()
output:
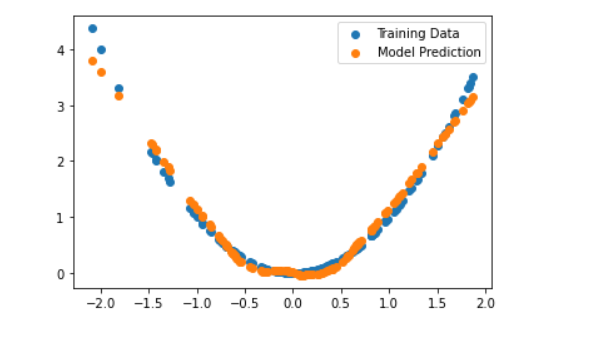
epoch = 1000
learning_rate = 0.0001
for _ in range(epoch):
params = update(params, xs, ys, learning_rate)
# 檢查結果
plt.scatter(xs, ys, label='Training Data')
plt.scatter(xs, forward(params, xs), label='Model Prediction')
plt.legend()
output:
註:
[30.1] 這個程式參考了 JAX 官方文件中的 Example: ML model parameters