這篇貼文,乃是針對「第二個範例程式」中的「4. 輔助函式」及「5.1. 單一 batch 訓練函式」的部份,加以詳細的說明。
Flax 建議的損失函式寫法是:

模型參數的調整,也就是所謂的「參數最佳化 optimizing」。Optax 為 JAX 提供了許多實作好的最佳化演算法,包括 adam、sgd 等等,詳細列表可參考 Optax 官方文件網頁 [39.1]。
# 定義兩種最佳化的方法
# 1. 「隨機梯度下降法(Stochastic gradient descent, SGD)」.
# 2. 「 adam 法」
learning_rate = 0.01
learning_momentum = 0.9
optim_sgd = optax.sgd(learning_rate, learning_momentum)
optim_adam = optax.adam(learning_rate)
Flax 提供了「訓練狀態」這一個物件,來追踪訓練過程,使程式更為精簡 [39.2]。我們首先要創立一個訓練狀態的案例,並提供 (1) 模型的 apply 函式 、(2) 模型的參數、 (3) 模型的參數調整方式。
state1 = train_state.TrainState.create(apply_fn=model.apply, params=params, tx=tx)
而在每一個批次訓練時,算出 grad() 並利用「訓練狀態」來調整模型的參數。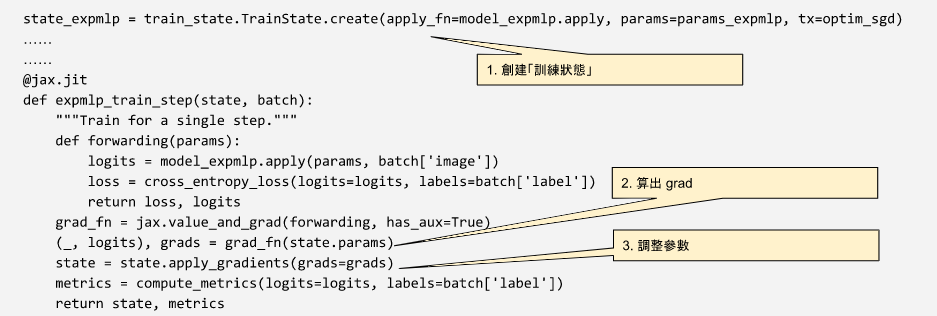
這些準備工作完成之後,就可以執行訓練了。
[39.1] 可參考 Optax API 之 Common Optimizers 的說明。
[39.2] 在 Flax 官方文件中,也提到了可以用 Optax 提供的方式來輔助訓練過程中的參數調整,讀者可參考其提供的 範例程式 Optimizing with Optax。比較 Flax 的「訓練狀態」, Optax 的方法稍微複雜了一點。

