今天說一下不同套件為什麼可以讀同一種格式的資料。
首先,當然是有感恩世界上有團體或個人的貢獻,幫助大家使用套件上能夠更方便。
再者,所謂的貢獻主要是函式庫的撰寫,讓這個函式庫能夠被應用。
以昨天的hdf5為例,我使用的套件為h5py,那其核心是什麼在讀取hdf5格式呢?其實是函式庫hdf(這邊是HDF函式庫的官網),可以下載讓使用者於電腦或伺服器編譯使用。
而我們在使用這些函數庫時,有兩個選擇,一種是選擇編譯好的,另一種是自行編譯。以conda 管理python相關應用的套件角度,基本上都是使用編譯好的。那我們就來看h5py套件的一些內容吧!
到anaconda官網套件下載區,並且搜尋到h5py,https://anaconda.org/conda-forge/h5py/files。
那每個套件都會有其files,截圖如下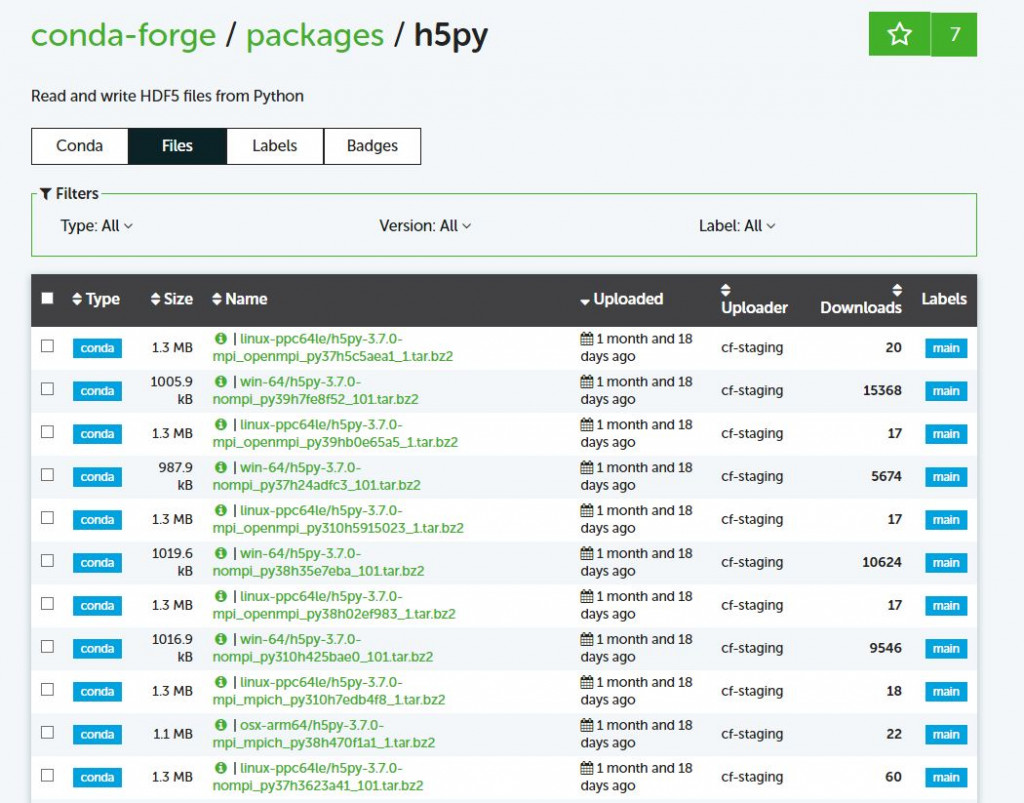
我們可以到到截圖中,有一個Name的標題,下面有很多編號,那其實就是編譯好的套件執行檔及其函式庫,譬如
| linux-ppc64le/h5py-3.7.0-mpi_openmpi_py37h5c5aea1_1.tar.bz2
| linux-ppc64le/h5py-3.7.0-mpi_openmpi_py39hb0e65a5_1.tar.bz2
在 | 的前面有一個i,會提供這一份編譯好的套件執行檔使用了哪些函式庫。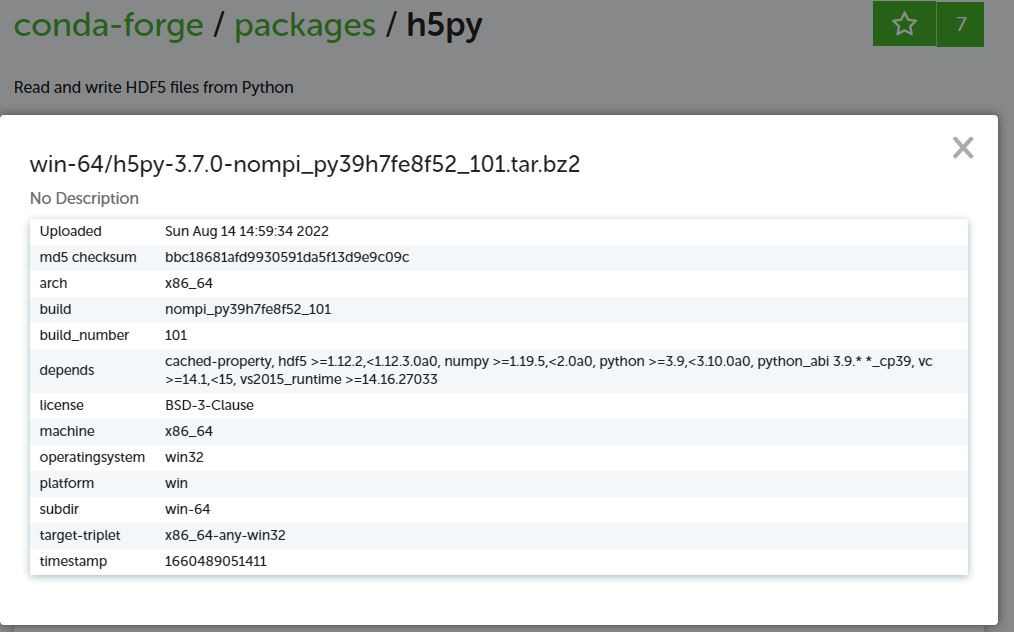
可以看到depends裡面有一項hdf5 >=1.12.2,代表這一份套件要成功解hdf5檔案的話,hdf5函式庫版本必須大於1.12.2,如果使用者是直接用conda 連線管理,是可以不用擔心這些函式庫的問題,但如果要用離線方式安裝,就必須要注意這一些細節。
那現在,我們來看gdal套件,直接選一個編譯好的套件看depends,如下圖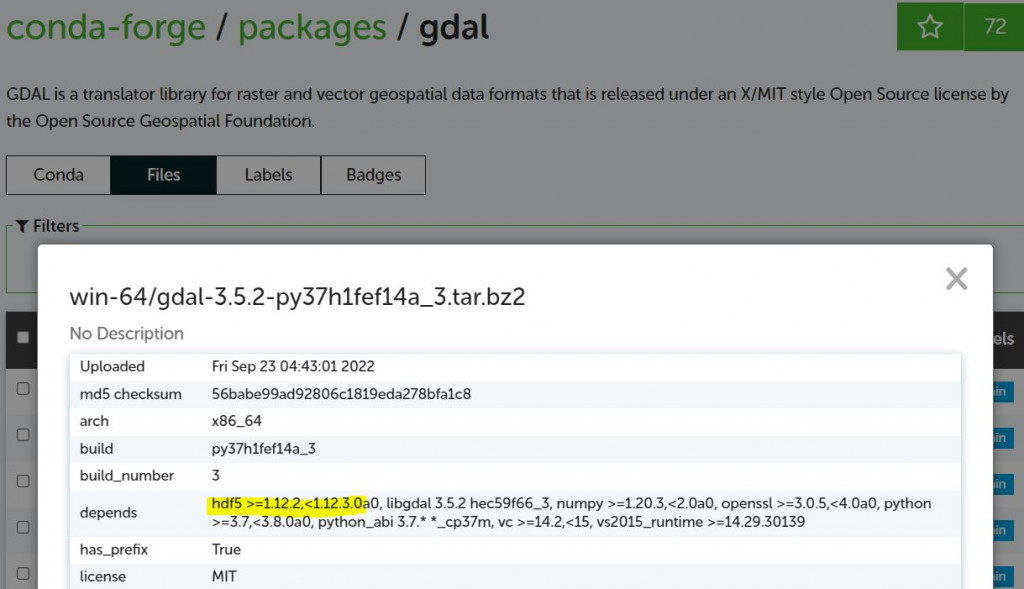
黃色螢光筆處,是hdf5 >= 1.12.2,< 1.12.3.0a0,這代表這一份gdal套件在編譯過程中是有加入hdf5函式庫。
也就是可以用gdal開啟hdf5格式檔案,大家可以試試看囉。
這邊使用gdal與h5py解同一份hdf5資料
import h5py
from osgeo import gdal
#用gdal讀取hdf5資料
gdalfn = gdal.Open("day19/O-A0043-002.h5",gdal.GA_ReadOnly)
gdalmeta = gdalfn.GetMetadata("SUBDATASETS")
print(gdalmeta)
gdal_temp_meta = gdal.Open(metasubdataset['SUBDATASET_3_NAME'])
subsname = gdalmeta['SUBDATASET_3_NAME'].split("//")[-1]
aofst = float(gdal_temp_meta.GetRasterBand(1).GetMetadata()[subsname + "_add_offset"])
scf = float(gdal_temp_meta.GetRasterBand(1).GetMetadata()[subsname + "_scale_factor"])
gdal_faketemp = gdal_temp_meta.GetRasterBand(1).ReadAsArray()
gdal_realtemp = gdal_faketemp * scf + aofst
#用h5py讀取hdf5資料
h5pyfn = h5py.File("day19/O-A0043-002.h5","r")
aofst = float(h5pyfn.get("temp_3_75um_nom").attrs["add_offset"])
scf = float(h5pyfn.get("temp_3_75um_nom").attrs["scale_factor"])
h5_faketemp = h5pyfn.get("temp_3_75um_nom")[:]
h5_realtemp = h5_faketemp*scf + aofst
print((gdal_faketemp-h5_faketemp).sum())
print((gdal_realtemp-h5_realtemp).sum())
上述程式的gdalmetda,其實是要抓取hdf5的分層資料描述資訊,有了資料描述資訊,才能夠繼續讀取並處理資料。兩個套件得出的結果進行計算後,(gdal_faketemp-h5_faketemp).sum()會得到0,但(gdal_realtemp-h5_realtemp).sum()得到的是2.008134742936818e-07,非常小的誤差累積值,主要原因是出在add_offset跟scale_factor上,經過計算之後有浮點數的差別。
那還哪些套件可以讀取hdf5呢?就由大家自己去google囉。
由這gdal及h5py套件可以得到一些資訊,就是對使用者的友善程度。對我來說,h5py會比gdal更友善一點,因為我實在不知道gdal要設計open兩次,當然有可能是因為gdal的功能實在太強大(可以讀tiff, png, hdf4, hdf5 等),必須使用這樣的方式處理hdf5的資料。所以套件的使用還是要使用者覺得舒適才是重點。
來視覺化
import matplotlib.pyplot as plt
import cartopy.crs as crs
import cartopy.io.shapereader as shpreader
from cartopy.feature import ShapelyFeature
import matplotlib.colors as mcolors
#先用gdal取lat與lon的資料
subs = gdal.Open(gdalmeta['SUBDATASET_1_NAME'])
lat = subs.GetRasterBand(1).ReadAsArray()
subs = gdal.Open(gdalmeta['SUBDATASET_2_NAME'])
lon = subs.GetRasterBand(1).ReadAsArray()
fig = plt.figure(figsize=(16,8))
himaproj = crs.Geostationary(central_longitude=140.7,satellite_height=35785860)
axs2 = plt.axes(projection=himaproj)
tw_shp = ShapelyFeature(shpreader.Reader("tw_shp\COUNTY_MOI_1090820.shp").geometries(), crs.PlateCarree(),facecolor="none",edgecolor='k')
axs2.gridlines(draw_labels=True)
latdrop = lat[68:,68:] #取68開始是因為0~67的經緯度有無效值,其實應該用mask或np.nan取代就可以
londrop = lon[68:,68:] #取68開始是因為0~67的經緯度有無效值,其實應該用mask或np.nan取代就可以
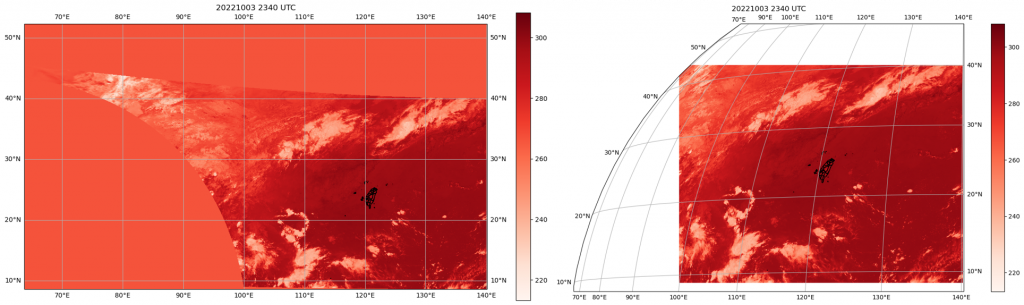
ims = axs2.pcolormesh(londrop,latdrop,gdal_realtemp[68:,68:], cmap="Reds", transform=crs.PlateCarree())
axs2.add_feature(tw_shp)
plt.colorbar(ims)
filename = subs.GetMetadata()["FILENAME"].split("_")
obstime = filename[2] + " " +filename[3] + " UTC"
plt.title(obstime)
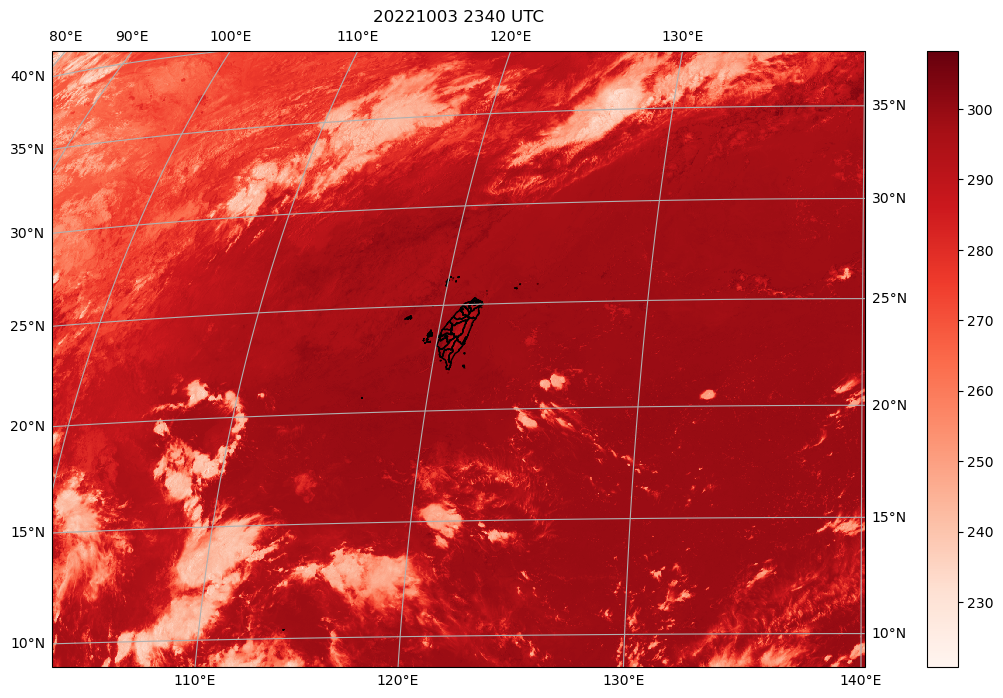
然後再提供用一般投影跟向日葵8號投影資訊(與上圖同,但把切的範圍變大)出來的圖(pcolormesh)