礙於篇幅緣故,過多細節的部分,會挑重點講述,如有疑問歡迎留言討論
今天,我們繼續後端 API 最後的部分,與資料庫 supabase 相關的服務。
如何透過 python package 連接 supabase 的細節,
可以參考 supabase-python 與 supabase API reference。
有一點需要注意的是,supabase 的 documentation 寫的不如 meilisearch 詳細,
且 supabase python 還在 public alpha version,
所以有些 python client 的細節我也是參考 javascript 部分的 documentation,
或是直接去看 supabase-python code 的。?
首先,相同的,我們在 APIServer __init__ 中,需要宣告 supabase client,
並且,我們接下來會以 GET /statistics/v1/prog_lang_count 舉例。
from supabase import create_client
class APIServer():
def __init__(self, name, host="0.0.0.0", port=5000, debug=False):
# init flask app
self.host = host
self.port = port
self.debug = debug
self.app = Flask(name)
self.logger = create_logger(self.app)
# init supabase
url = os.getenv("SUPABASE_URL")
api_key = os.getenv("SUPABASE_API_KEY")
if not url:
self.logger.error("Missing env SUPABASE_URL while connecting to Supabase.")
abort(500)
elif not api_key:
self.logger.error("Missing env SUPABASE_API_KEY while connecting to Supabase.")
abort(500)
else:
self.supa_url = url
self.supa_api_key = api_key
self.supabase_client = create_client(self.supa_url, self.supa_api_key)
# init API
self.add_endpoint(
endpoint="/statistics/v1/prog_lang_count",
endpoint_name="prog_lang_count",
handler=self.programming_languages_count,
handler_params={},
req_methods=["GET"]
)
前端用 GET /statistics/v1/prog_lang_count,
是為了統計歷年文章所涵蓋的程式語言,藉此提供趨勢參考。
我們在 Day 10 中有提到,
supabase client 藉由 rpc 執行 supabase server 的 stored procedure。
所謂的 stored procedure 類似於事先存於 server 端的 SQL function。
因此,我們可以先來看看 backend script 中,
與 GET /statistics/v1/prog_lang_count 相關的 stored procedure: prog_lang_count.sql。
CREATE OR REPLACE FUNCTION prog_lang_count(year text, top_n int default null)
RETURNS TABLE (prog_lang text, "count" int)
AS
$$
WITH prog_lang_flat AS (
SELECT UNNEST(programming_languages) AS prog_lang
FROM articles
WHERE publish_at like CONCAT(year, '%')
)
SELECT prog_lang, COUNT(*) AS "count"
FROM prog_lang_flat
GROUP BY prog_lang
ORDER BY COUNT(*) DESC, prog_lang
LIMIT top_n;
$$
language sql;
可以看到此 prog_lang_count function 中,
有 year 與 top_n 兩個參數。
分別用來統計哪年的文章及回傳前幾名的程式語言。
我們知道,supabase 的文章,存在 article 這 table 中。
而統計文章程式語言會用到 article 中的 programming language field。
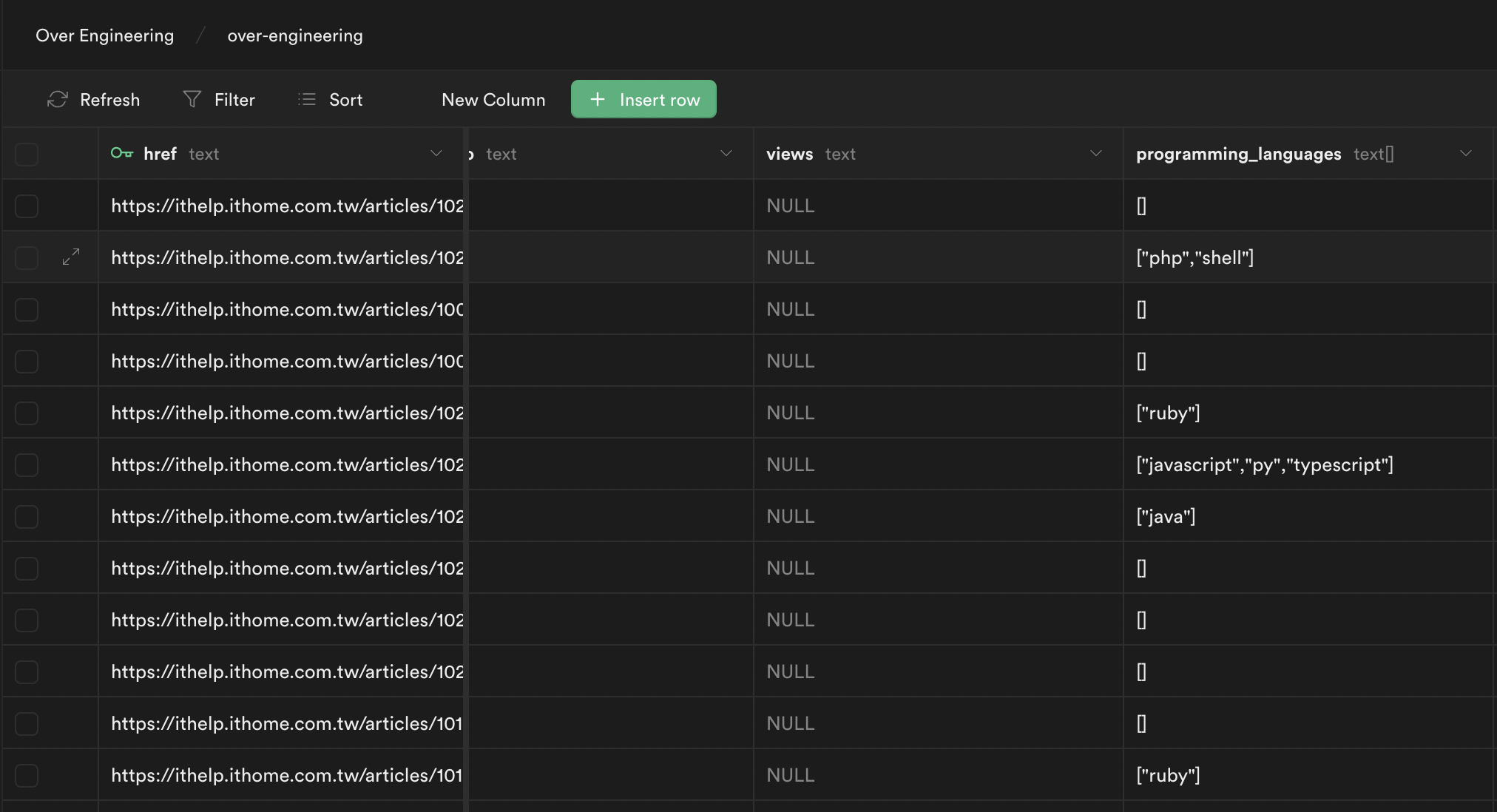
programming language field 為 []text,
所以在統計前,我們要先將所有 text array 拆成一行一個 array element,
並用文章發表年篩選。
WITH prog_lang_flat AS (
SELECT UNNEST(programming_languages) AS prog_lang
FROM articles
WHERE publish_at like CONCAT(year, '%')
)
接著,我們就只需要 group by 程式語言,並統計文章數量。
最後再以此排序,並取前 top_n 個。
SELECT prog_lang, COUNT(*) AS "count"
FROM prog_lang_flat
GROUP BY prog_lang
ORDER BY COUNT(*) DESC, prog_lang
LIMIT top_n;
我們先看看 API 的 request 和 response。
若用 curl 測試,
curl -XGET "http://0.0.0.0:5000/statistics/v1/prog_lang_count?year=2021&top_n=3"
得到的 response 格式為
[
{
"prog_lang":"javascript",
"count":2529
},
{
"prog_lang":"python",
"count":1518
},
{
"prog_lang":"html",
"count":802
}
]
在 handler function 中,我們先 parse request arguments。
其中,我們先 parse 並檢查 request arguments 中,
是否包含所有必要的 arguments: "year"。
def programming_languages_count(self, params: dict):
# parse and check request
req_args_key_set = set(request.args.keys())
req_must_key_set = {'year'}
if (req_must_key_set - req_args_key_set) != set():
self.logger.error(
"Missing params %s in /statistics/v1/prog_lang_count request.",
", ".join(req_must_key_set - req_args_key_set)
)
return Response(status=400, headers={})
try:
year = request.args.get('year', type=int)
top_n = request.args.get('top_n', type=int)
except Exception as exp:
self.logger.error("Failed to parse args for /statistics/v1/prog_lang_count request.")
self.logger.error(exp)
return Response(status=400, headers={})
接著便用 supabase client 透過 rpc 執行遠端 stored procedure。
由於 stored procedure 中的格式已經與 API 回傳格式相同,
這裡就不需要再 format output 了。
try:
res_data = self.supabase_client.rpc(
'prog_lang_count',
{'year': str(year), 'top_n': top_n}
).execute()
except Exception as exp:
self.logger.error("Failed to run /statistics/v1/prog_lang_count request on Supabase.")
self.logger.error(exp)
return Response(status=500, headers={})
return Response(
response=json.dumps(res_data.data),
status=200,
headers={"Content-Type": "application/json"}
)
後端的部分到這裡就結束了,
我們介紹了如何設計 API, 用 flask 實作, 並連接 meilisearch 及 supabase。
明天我們便會進入前端部分。
終於寫了一個段落了,
明天開始就可以用 kirby 的存稿了 ?


 iThome鐵人賽
iThome鐵人賽