今天參考了CNN模型VGG16與AlexNet由於GPU的memory分配不足,所以filters的部分從64,128,256,512都改為一半,而全連階層4096太大了因此改為512。
#參考VGG16
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding='same', input_shape=(13, 13, 1), activation='relu'))
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2), padding='same'))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2), padding='same'))
model.add(Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2), padding='same'))
model.add(Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2), padding='same'))
model.add(Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2), padding='same'))
model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dense(1024, activation='relu'))
model.add(Dense(4, activation='relu'))
接著5個label數量各為20萬、40萬、20萬、1萬6與480,因此將480的label拿掉(補充說明480為棄牌動作)。
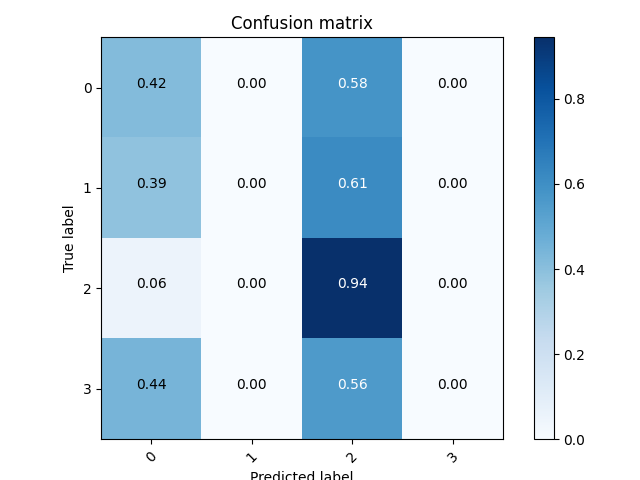
從以上結果來看,VGG16不適用於牌局訓練。
這是有放Pooling版本,為了驗證Pooling對於牌局的影響,因為手牌位置代表手牌牌值的大小而Pooling的主要功能是保留主要的特徵,可能會破壞牌局的完整性。
#參考AlexNet
model.add(Conv2D(filters=96, kernel_size=(11, 11), strides=4, padding='same', input_shape=(13, 13, 1), activation='relu'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=2, padding='same'))
model.add(Conv2D(filters=256, kernel_size=(5, 5), strides=1, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=2, padding='same'))
model.add(Conv2D(filters=384, kernel_size=(3, 3), strides=1, padding='same', activation='relu'))
model.add(Conv2D(filters=384, kernel_size=(3, 3), strides=1, padding='same', activation='relu'))
model.add(Conv2D(filters=256, kernel_size=(3, 3), strides=1, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=2, padding='same'))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1024, activation='relu'))
model.add(Dense(4, activation='softmax'))
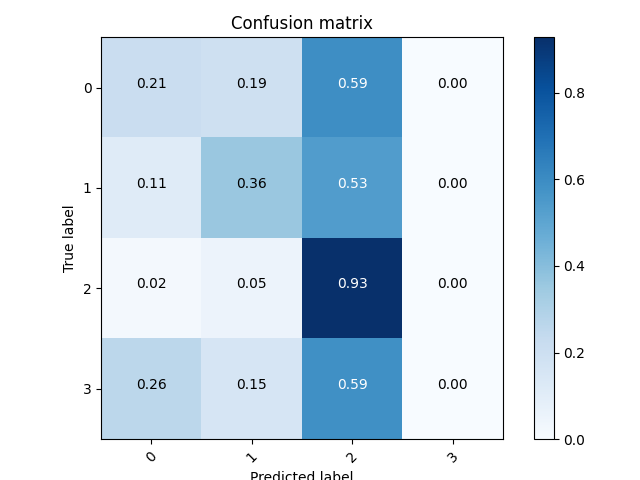
沒有Pooling & 有Dropout版本,好像差不多呢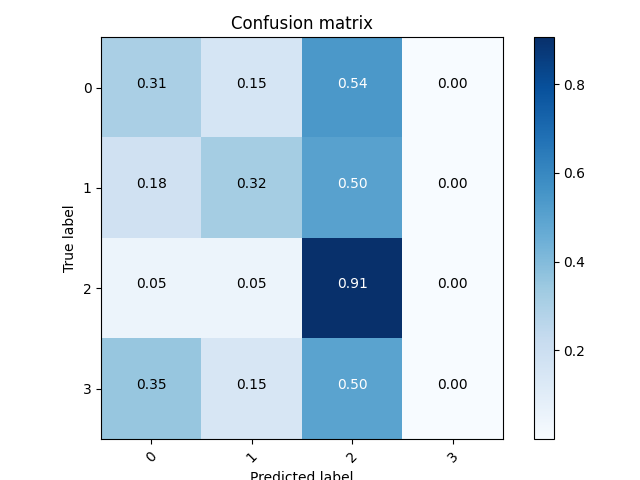
沒有Pooling & 沒有Dropout版本,目前看來此版本是比較好的,暫定用這個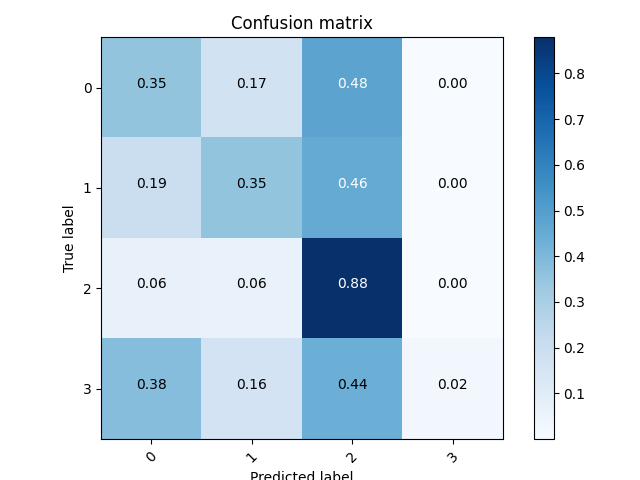


 iThome鐵人賽
iThome鐵人賽