透過爬取國內上市櫃股票一覽表,以及股價歷史數據,來建立量化投資所需的小工具,除了能針對自己心目中的標的進行分析,也能透過適當的投資策略,在茫茫股海中打撈投資標的,同時,也希望透過這樣的搜尋機制,方便後續開發行動應用或是聊天機器人
pandas.DataFrame.append 自版本1.4.0起已棄用,需改成pd.concat()的寫法
本章節的Google Colab筆記本連結:https://colab.research.google.com/drive/1ILxNFxvSCF7XzseH8Za-7e47G3XCYRmN?usp=sharing
所謂的爬蟲,指的是透過程式自動化的去抓取網站資料的過程,因此需要準備目標網站的網址
-上市證卷:http://isin.twse.com.tw/isin/C_public.jsp?strMode=2
-上櫃證卷:http://isin.twse.com.tw/isin/C_public.jsp?strMode=4
有了目標網站,就要來介紹協助我們完成爬蟲的重要套件與函式!
requests.get("url") 對url發出請求,並獲得回傳的HTML程式碼pd.read_html() 來獲取網頁上的表格#國內上市證卷辨識號碼一覽表
TWSE_listed = pd.read_html(
requests.get("http://isin.twse.com.tw/isin/C_public.jsp?strMode=2").text)[0]
#國內上櫃證卷辨識號碼一覽表
TPEX_listed = pd.read_html(
requests.get("http://isin.twse.com.tw/isin/C_public.jsp?strMode=4").text)[0]
透過pandas將網頁上的表格轉換成如下圖的DataFrame格式,由於一個網頁中可能存在多個表格,而我們僅需要第一張表格,因此設定為[0]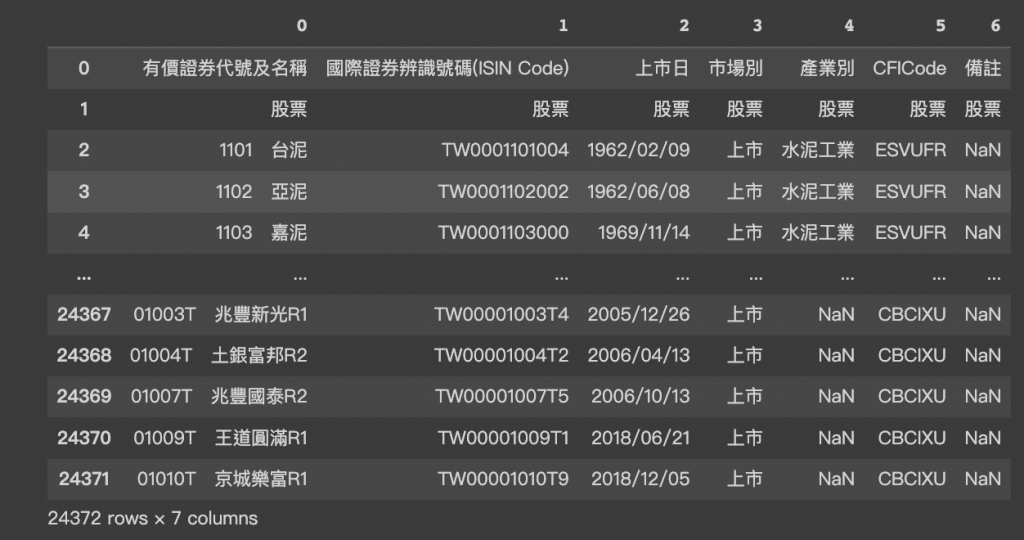
接著整理爬蟲獲得的表格,重新設定列名稱,並將原先表格內無意義的欄位刪除,最後再透過reset.index()重置左側的欄位索引值
PS:在這邊合併了上市與上櫃兩張表格,當然也可以分開去做使用
#設定column名稱
TWSE_listed.columns = list(TWSE_listed.iloc[0].values)
TPEX_listed.columns = list(TPEX_listed.iloc[0].values)
#刪除第一行並合併
TWSE_listed = TWSE_listed.iloc[2:]
TPEX_listed = TPEX_listed.iloc[2:]
all_stock = pd.concat([TWSE_listed, TPEX_listed])
all_stock.reset_index(drop=True, inplace=True)
將有價證券代號及名稱的欄位,透過文字切割分成股票代號與股票名稱
#整理欄位
stock_num = all_stock["有價證券代號及名稱"].str.split(" ", expand = True)[0]
stock_name = all_stock["有價證券代號及名稱"].str.split(" ", expand = True)[1]
all_stock.insert(0,"股票代號",stock_num,True)
all_stock.insert(1,"股票名稱",stock_name,True)
all_stock = all_stock.drop(["有價證券代號及名稱"], axis=1)
最後整理完的國內上市上櫃證卷一覽表如下圖,共計31883筆證卷資料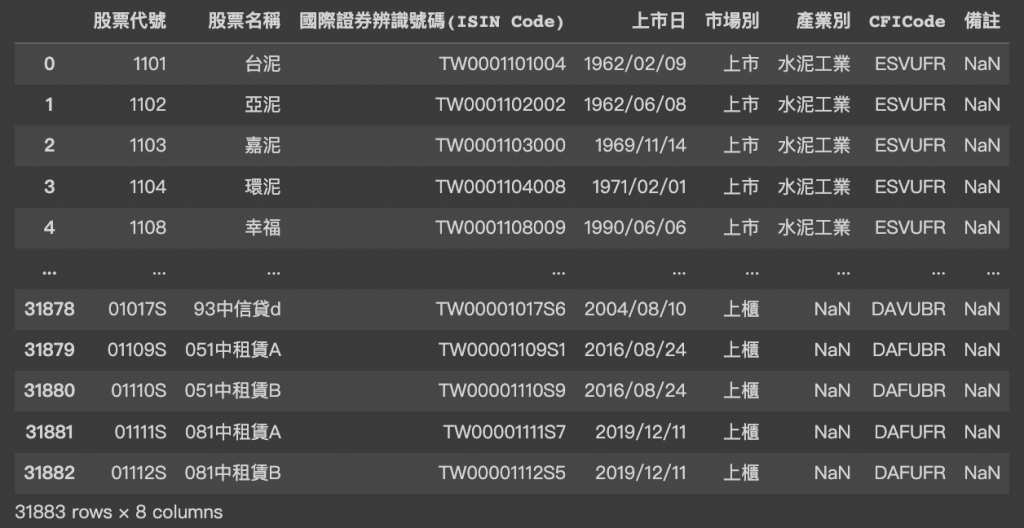
接著要進行股票的歷史數據搜集,首先針對常用的幾個套件進行比較,如下表所述,由於主題的目標為國內的證卷交易市場,因此將採用FinMind套件進行
| 套件名稱 | 優點 | 缺點 |
|---|---|---|
| yfinance | 方便使用,國外股市的資料十分完整 | 僅收錄2008年後的國內股市數據,且沒有上櫃證卷的數據 |
| ffn | 除了資料外,也提供許多實用的函示 | 資料來源同樣以yfinance為主,因此國內數據較為不足 |
| FinMind | 提供以台股為主,且超過50種的金融開源數據 | 無法獲得即時資料 |
由於使用的是Google Colab,因此採用Colab提供的表單來設定變數值,詳細的內容可參閱官方筆記本,在這邊分別設計了“依產業別搜尋”、“依股票名稱搜尋”、“依股票代號搜尋”三種,並將使用者輸入的參數值,與上文所搜集到的國內上市上櫃證卷一覽表進行比較,把存在於一覽表中的搜尋目標,存入final_target的變數當中,以便後續進行歷史數據的抓取
#@title { display-mode: "form" , run: "auto" }
#@markdown ###依 **產業別** 進行搜尋
target_industry = "\u5316\u5B78\u5DE5\u696D" #@param ["水泥工業","食品工業","塑膠工業","紡織纖維","電機機械","電器電纜","化學工業","生技醫療業","玻璃陶瓷","造紙工業","鋼鐵工業","橡膠工業","汽車工業","半導體業","電腦及週邊設備業","光電業","通信網路業","電子零組件業","電子通路業","資訊服務業","其他電子業","建材營造","航運業","觀光事業","金融保險","貿易百貨","油電燃氣業"]
target_industry_str = str(target_industry)
final_target = all_stock[all_stock['產業別']==target_industry_str ]
final_target = final_target.reset_index(drop=True)
final_target
股票名稱與股票代號支援多筆同時搜尋,使用split(" ")以空格為分割點進行文字切割,將切割後產生的複數個搜尋標的存進input_target,並透過for迴圈一個一個標的進行比較,假如其中某個標的不存在一覽表中,則列印出查無此股票名稱或代號,請確認後再輸入
#@title { display-mode: "form"}
#@markdown ###依 **股票名稱** 進行搜尋 (多筆輸入以空格分隔)
target_name = "\u53F0\u7A4D\u96FB" #@param {type:"string" }
input_target = target_name.split(" ")
final_target = pd.DataFrame()
for i in range(len(input_target)):
x = all_stock[(all_stock["股票名稱"]==input_target[i])]
if x.empty:
print("查無此股票名稱或代號,請確認後再輸入 "+input_target[i])
else :
final_target = pd.concat([final_target, x], ignore_index=True)
final_target = final_target.reset_index(drop=True)
final_target
#@title { display-mode: "form" }
#@markdown ###依 **股票代號** 進行搜尋 (多筆輸入以空格分隔)
target_num = "2317 2330 2891" #@param {type:"string"}
input_target = target_num.split(" ")
final_target = pd.DataFrame()
for i in range(len(input_target)):
x = all_stock[(all_stock["股票代號"]==input_target[i])]
if x.empty:
print("查無此股票名稱或代號,請確認後再輸入 "+input_target[i])
else :
final_target = pd.concat([final_target, x], ignore_index=True)
final_target = final_target.reset_index(drop=True)
final_target
具體的樣式如下圖,可直接選擇需要的搜尋方式輸入查詢標的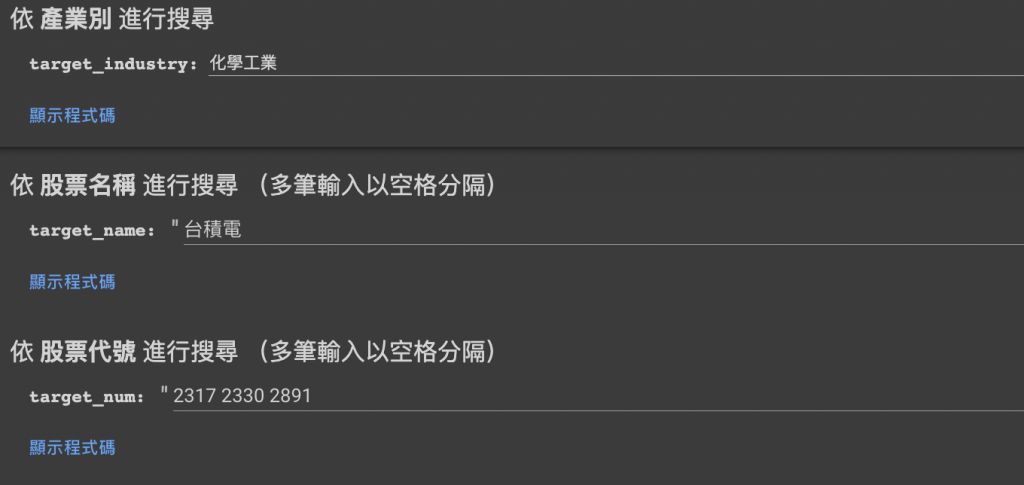
設定好股市目標後,還要設定歷史資料的取用時段區間,同樣採用Colab Form的變數設置方式,宣告start_date與end_date
#@title 選擇資料起始時間
start_date = '2010-01-01' #@param {type:"date"}
#@markdown ---
end_date = '2023-01-01' #@param {type:"date"}
接著要正式進入FinMind的使用環節,首先要安裝FinMind套件,並導入模組DataLoader
使用函式dl.taiwan_stock_daily(),設定stock_id股市代碼、start_date起始時間、end_date結束時間,這邊需要特別注意的是,必須使用String型態,因此這邊加上str()來轉換型態
!pip install FinMind
from FinMind.data import DataLoader
def stock_data(stock_target):
dl = DataLoader()
data = dl.taiwan_stock_daily(stock_id=str(stock_target),
start_date=str(start_date) ,
end_date=str(end_date))
return data
最後需要建立一個for迴圈,一個個的取出final_target裏的股票代號作為搜尋目標,塞入stock_data()當中,設定time.sleep(5)來延遲每次重複執行的時間,而try與except則是用來避免因出現錯誤,而中斷資料的取用,僅顯示出現錯誤的股票代號來提醒使用者,最後以stock_index['2330']台積電為例,來看看資料的取用成果
stock_index = {}
for stock_num in final_target["股票代號"]:
time.sleep(5)
try:
stock_index[stock_num] = stock_data(stock_num)
except :
print(stock_num+"error")
stock_index['2330']
可以看到有非常完整的欄位,包含了開盤價、收盤價、最高價、最低價、成交量等等,而後續的篇章將會以這些資料進行各式各樣的股市趨勢分析與視覺化應用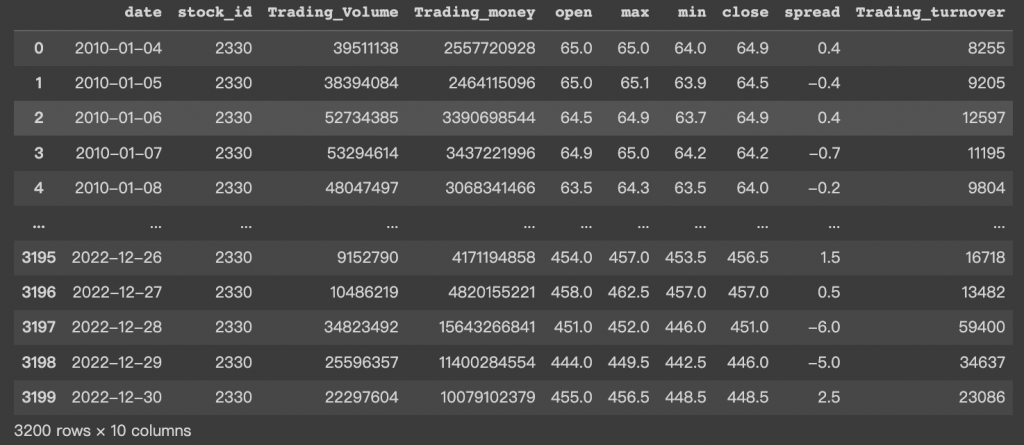
 BiuBiuBiu
BiuBiuBiu

 iThome鐵人賽
iThome鐵人賽