最近2023 Global AI Bootcamp 才剛剛圓滿落幕,而我也有幸籌辦了台北場的活動。每年 Global AI Bootcamp 都會提前釋出當年的 Keynote 影片,讓主辦人能夠提前掌握主題,今年雖然也一樣,但是影片實在太長了,時間又非常緊迫,我只好借助了 OpenAI 的力量~
pip3 install openai
pip3 isntall pydub
接下來我們要利用 OpenAI 的 Whisper API 來將錄音檔生出逐字稿,目前支援這些音訊檔案:
mp3
mp4
mpeg
mpga
m4a
wav
webm
不過,whiper API 有檔案大小的上限,只能接受 25 MB 的檔案,所以如果檔案太大的話,就需要事先裁切檔案。
from pydub import AudioSegment
def crop_audio(input_file, output_file, start_time, end_time):
# 讀取音頻文件
audio = AudioSegment.from_file(input_file, format="mp3")
# 裁剪音頻文件
cropped_audio = audio[start_time:end_time]
# 將裁剪後的音頻文件保存為 mp3 格式
cropped_audio.export(output_file, format="mp3")
以我的情況,我一開始取得的錄音檔是 keynote.mp3,我先切一小段,從 0 秒一直到 11分48秒,然後再存成 cropped.mp3。
input_file = "keynote.mp3"
output_file = "cropped.mp3"
start_time = 0 # 裁剪的起始時間(以毫秒為單位)
end_time = (11*60+48) * 1000 # 裁剪的結束時間(以毫秒為單位)
crop_audio(input_file, output_file, start_time, end_time)
然後再將裁切好的錄音檔餵給 Whisper 產生逐字稿
import openai
#記得先取得 API Key: https://platform.openai.com/account/api-keys
openai.api_key = "<你的 API Key>"
audio_file= open("cropped.mp3", "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file)
text = transcript.to_dict()['text']
print(text)
These models, right, you've got text-to-speech, you've got, rather I should say, text-to-image with DALI, you've got coding, you've got language. Your chat GPT has completely changed the conversation about AI. I think those of us who have been on the inside of AI definitely have kind of thought about it as, like, of course, it's changing the world and we see it every day. But I think chat GPT made it real for millions of people by showing them what it can do and how powerful it is, and their imaginations are now freed. How can this be really useful towards someone who may have, say, limited mobility? One of my colleagues, Christina, her arms are paralyzed and she types with her toes. And watching her use this product is really cool because she said, oh, I now just have to type one sentence rather than typing lots of sentences to plan a trip, for example. ...
如果覺得還要裁切很麻煩,也可以交給 Azure Speech Studio 處理,若有需要,可以參考以下文章:
用 Azure Speech Studio x ChatGPT 幫你生逐字稿
或者,乾脆把 Whisper 模型裝在自己的電腦,在自己的電腦產稱逐字稿:
Whisper Github
接下來,逐字稿英文字太多,實在懶得看,要懶就懶到底~我們可以利用最新的 ChatGPT API 來產生摘要。
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": f"提供以下文字之繁體中文摘要:{text}"}
]
)
ans = response.to_dict()['choices'][0]['message']['content']
print(ans)
這些模型包括語音轉文字、DALI 的文字轉圖像、編碼和語言等。Chat GPT 徹底改變了人們對 AI 的看法。對於一些行動不便的使用者,例如手臂癱瘓的人,使用 Chat GPT 可以幫助他們更快、更方便地完成一些任務。然而,人們還需要對這項技術建立正確的心理模型,了解其一些資訊可能不是完全可靠的,需要再次確認。在談到 AI 進展的過去一年裡,Azure Open AI 服務和 Chat GPT 被視為是最重要、最令人印象深刻的。Chat GPT 的使用促使人們將其真正的威力體會到。 John Montgomery 是 Azure AI 的產品負責人。他認為了解負責任的 AI,大型語言模型的使用以及增強學習都是 IT 專業人員、開發人員和數據科學家等的必備知識。
這邊要注意一下,如果只要求寫摘要,沒有指定摘要的語言,可能得到英文或者是簡體中文的摘要。另外,也有可能部分專有名詞會有點小錯,例如:DALL-E 變成 DALI,但都還算在可以看懂的範圍。
錄音檔超過 25 MB 需要裁切,裁切時也應該考慮到 ChatGPT 的 token 數量上限,每次包含問與答的總 token 數必須小於 4096。我們很難控制 ChatGPT 回答時會用多少 token,但我們大概可以想像,我們要求的是摘要,應該可以讓答案的字數比我們發問的字數還少,發問時只用 2048 tokens 以下,應該就會足夠了。
再來,還可以參考一般人的演講語速,大概一分鐘可以講 125 個英文單字或150個中文字,再考慮token 數與文字的關係,1000 tokens 大約為 750 個英文單字,或 400 個中文字。所以,如果是英文錄音檔,每分鐘大概會需要 170 tokens(取整數),若是中文,每分鐘大概需要 375 tokens。
綜合以上,如果需要配合 Whisper 和 ChatGPT 的限制,可以這樣裁切錄音檔:如果是英文錄音,每 12 分鍾切一個檔案;中文錄音則是 5 分鍾以內。
| 語言 | 每分鐘演講語速 | 每分鐘 token 數量 | 建議裁切長度 |
|---|---|---|---|
| 英文 | 125 個英文單字 | 170 tokens | 12 分鐘 |
| 中文 | 150 個中文字 | 375 tokens | 5 分鐘 |
用個迴圈,重複上述動作,就能把錄音檔變成演講摘要,快速掌握演講重點囉!
無意間發現一句只有 8 個 Bafflo 所組成的句子:
Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo.
這句話文法完全正確,只是文法結構太複雜了,很難理解,大概的意思是:水牛城中某些被其他美洲野牛所恐嚇的美洲野牛,又去恐嚇了另一些美洲野牛。
這句話的相關說明可以參考維基百科。
這句話交給 google 翻譯大概會變成這樣: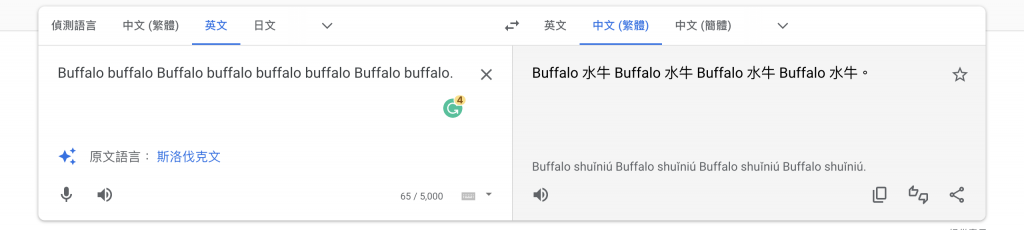
但如果交給 ChatGPT API,就會得到以下結果:
偉哉 ChatGPT,之後如果可以一口氣串接大量文字,應該就可以開自動翻譯社了。
 Ben
Ben
