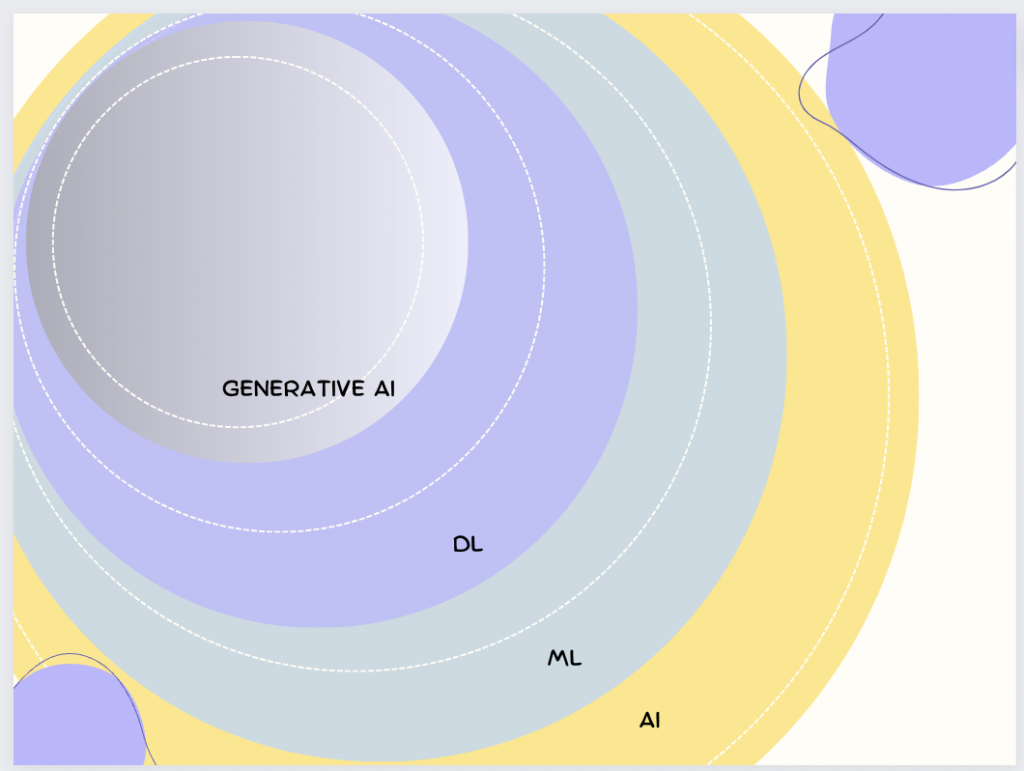
人工智慧下面涵蓋了機器學習,深度學習以及生成式AI, 後幾個都是他的子領域。
人工智慧(Artificial Intelligence,縮寫為 AI)是一個結合了計算機科學、認知科學、數學和其他多個學科的研究領域。其主要目的是研發出能夠模擬、擴展和增強人類智慧的技術和方法。這意味著,透過人工智慧,我們可以使機器執行一些在過去僅依賴人類智慧才能完成的任務,如語言理解、視覺識別、決策制定和複雜問題的解決。
人工智慧可以大致分為兩大類:
弱人工智慧(Weak AI):這種AI專注於執行某一特定的任務,它不具備真正的認知能力,只能在其被訓練的特定範疇內工作。例如,當我們使用語音助手如蘋果的 Siri 或亞馬遜的 Alexa 時,我們實際上是在與一個弱AI互動。
強人工智慧(Strong AI):這是一種理論上的AI形式,它擁有與人類相似的認知能力。這意味著它可以學習、推理、解決問題、感知環境,甚至具有情感。強AI的目標是使機器能夠在任何情境下,如同人類一樣地思考和行動。
人工智慧的應用已經滲透到我們生活的各個方面,從自駕車、醫療影像分析、股票交易策略、到語音和圖像識別技術,以及自然語言處理等。這些技術正在改變我們的生活方式和工作模式。
然而,隨著AI技術的迅速發展,它也帶來了一系列的挑戰和問題。例如,數據隱私問題、工作自動化可能導致的大規模失業、以及AI決策過程缺乏透明度和可解釋性。這些問題需要我們在技術、法律、道德和社會各個層面進行深入的思考和討論,以確保AI的健康發展和應用。
機器學習是人工智慧領域中的一個核心子領域,專注於研發能夠自主學習和改進的算法。這些算法的特點是,它們不需要明確的指令來執行特定的任務,而是通過分析和學習數據來自動獲得知識和技能。
在機器學習的框架下,我們使用特定的算法來解析和學習數據,從而建立預測模型。這些模型基於訓練數據集來學習,並且一旦訓練完成,它們可以用於預測或分類新的、未知的數據。
機器學習主要分為三種類型:
監督學習(Supervised Learning):這種方法需要一組已標記的訓練數據。算法從這些數據中學習,並建立一個模型,該模型可以預測新數據的輸出值。例如,我們可以使用監督學習來預測房價或識別圖像中的物體。
非監督學習(Unsupervised Learning):這種方法不依賴於標記的訓練數據。而是試圖從數據中找出隱藏的結構或模式。常見的應用包括數據聚類和特徵降維。
強化學習(Reinforcement Learning):這是一種學習方法,其中一個智能體在環境中進行互動,並根據其所採取的行動獲得獎勵或懲罰。目的是找到一種策略,使得智能體在長期內獲得的獎勵最大化。
機器學習的應用範疇相當廣泛,從日常生活的語音助手和推薦系統,到專業領域如生物信息學、金融預測和高級醫療診斷。隨著技術的進步,機器學習將繼續在各種領域中發揮其巨大潛力。
深度學習是機器學習的一個子領域,它專注於使用稱為神經網路的算法。特別是,當這些網路包含很多層時,我們稱之為深度神經網路,這也是深度學習名稱的由來。
深度學習模型由多層非線性處理單元組成,每一層都從前一層學習數據的一些表示。這些層結構化地建立在彼此之上,形成一個層次化的表示。這種層次化的表示方式使得深度學習模型能夠學習非常複雜的模式。
深度學習的一個關鍵優點是它可以自動從原始數據中學習特徵,而不需要人工特徵工程。這使得深度學習在處理高維度和非結構化數據(如圖像、聲音和文本)時非常有效。
深度學習的應用範疇非常廣泛,包括但不限於:圖像識別、語音識別、自然語言處理、生物信息學、藝術、醫學診斷、藥物發現和遊戲等。
然而,深度學習也有其挑戰和限制。例如,深度學習模型通常需要大量的數據和計算資源,並且可能缺乏可解釋性。此外,深度學習模型也可能過度擬合訓練數據,導致在新的、未見過的數據上的性能下降。
生成式AI是一種人工智慧技術,它的目標是創建新的、以前未見過的內容,這些內容可以是圖像、音樂、語音或文字。生成式AI通常使用一種稱為生成模型的機器學習技術,這種模型可以學習數據的潛在分佈,並從中生成新的數據點。
生成對抗網路(Generative Adversarial Networks,GANs)是生成式AI中最知名的技術之一。
GAN由兩部分組成:一個生成器和一個鑑別器。生成器的目標是創建看起來像真實數據的新數據,而鑑別器的目標是區分生成的數據和真實的數據。這兩部分在訓練過程中相互競爭,使得生成器能夠產生越來越逼真的數據。
另一種常見的生成模型是變分自編碼器(Variational Autoencoders,VAEs)。VAEs是一種機器學習模型,它首先將輸入數據編碼成一個潛在空間,然後從這個潛在空間解碼以生成新的數據。VAEs的一個關鍵特性是它們可以學習數據的連續潛在分佈,這使得它們可以生成新的、與訓練數據相似但不完全相同的數據。
不過目前最為讓人注目的就是 Stable Diffusion 以及基於 transformer 的生成式預訓練模型 ChatGPT 以及 LLAMA。
Stable Diffusion 是一種深度學習的文字到圖像生成模型,於2022年發布。它主要用於根據文字的描述生成詳細圖像,儘管它也可以應用於其他任務,如內補繪製、外補繪製,以及在提示詞指導下生成圖生圖的翻譯。它是一種潛在變量模型的擴散模型,由慕尼黑大學的 CompVis 研究團隊開發的各種生成性類神經網絡。 Stable Diffusion 由3個部分組成:變分自編碼器(VAE)、U-Net和一個文字編碼器。與其學習去噪圖像數據(在“像素空間”中),而是訓練VAE將圖像轉換為低維潛在空間。添加和去除高斯噪聲的過程被應用於這個潛在表示,然後將最終的去噪輸出解碼到像素空間中。在前向擴散過程中,高斯噪聲被迭代地應用於壓縮的潛在表徵。每個去噪步驟都由一個包含殘差神經網絡(ResNet)中間的U-Net架構完成,通過從前向擴散往反方向去噪而獲得潛在表徵。最後,VAE解碼器通過將表徵轉換回像素空間來生成輸出圖像。
基於轉換器的生成式預訓練模型(Generative pre-trained transformers,GPT)是一種大型語言模型(LLM),也是生成式人工智慧的重要框架。首個GPT由OpenAI於2018年推出。GPT模型是基於Transformer模型的人工神經網路,在大型未標記文字資料集上進行預訓練,並能夠生成類似於人類自然語言的文字。截至2023年,大多數LLM 都具備這些特徵,並廣泛被稱為GPT。OpenAI 發布了具有極大影響力的GPT基礎模型,它們按順序編號,構成了「GPT-n」系列。由於其規模(可訓練參數數量)和訓練程度的提升,每個模型相較於前一個都顯著增強。其中最新的模型是 GPT-4,於2023年3月發布。其他的競爭對手就是目前學術開源的 llama ,Falcon 以及 Google 目前推出的Bard 了。
生成式AI的應用非常廣泛,包括創建新的藝術作品、生成逼真的人臉圖像、創建新的音樂、生成寫作文本、設計新的分子結構等。然而,生成式AI也引發了一些道德和社會問題,例如深假(deepfakes)的問題,這是使用生成式AI技術創建的假新聞或假視頻。
深度學習在許多領域都有廣泛的應用,以下是一些主要的例子:
圖像識別和處理:深度學習被廣泛用於圖像識別、物體檢測、人臉識別、圖像分割等任務。例如,自動駕駛車輛使用深度學習來識別道路、車輛、行人等。
語音識別和生成:深度學習被用於語音識別(例如,將語音轉換為文字)和語音生成(例如,文字轉語音)。這種技術被用於語音助手(如蘋果的 Siri、亞馬遜的 Alexa)和語音識別系統。
自然語言處理:深度學習被用於理解和生成自然語言。這包括情感分析(判斷文本的情感),機器翻譯(將一種語言的文本翻譯成另一種語言),和文本生成(例如,生成新聞文章或故事)。
醫學影像診斷:深度學習被用於分析醫學影像,如 X 光片、MRI 掃描和 CT 掃描,以幫助醫生診斷疾病。
藥物發現和基因組學:深度學習被用於預測藥物的可能效果,以及分析基因數據以了解疾病的基因因素。
遊戲:深度學習被用於訓練遊戲AI,例如 AlphaGo,這是一個能夠打敗人類世界冠軍的圍棋AI。
推薦系統:深度學習被用於推薦系統,例如預測用戶可能感興趣的產品或服務。這種技術被用於許多線上平台,如 Netflix、Amazon 和 YouTube。
這只是深度學習應用的一部分,隨著技術的進步,其應用領域將會更加廣泛。
生成式AI在許多領域都有廣泛的應用,以下是一些主要的例子:
圖像生成:生成式AI可以用於創建新的、逼真的圖像或修改現有的圖像。例如,生成對抗網路(GANs)可以用於生成逼真的人臉圖像,或將一種風格的圖像轉換為另一種風格(稱為風格轉換)。
文本生成:生成式AI可以用於生成自然語言文本,例如寫作文章、生成詩歌、劇本或故事,甚至創作新的對話和劇本。
音樂生成:生成式AI可以用於創作新的音樂,包括旋律、和聲和節奏。
語音生成:生成式AI可以用於生成逼真的語音,這在語音合成、語音助手和語音轉換等應用中非常有用。
藥物發現:生成式AI可以用於生成新的化學結構,這可能導致新藥的發現。
深度假人(Deepfakes):這是生成式AI的一種較為爭議的應用,它可以創建逼真的假視頻或音頻,使人們看起來像是在說或做他們從未說過或做過的事情。
藝術和設計:生成式AI可以用於創建新的藝術作品,或者幫助設計新的產品和建築。
這只是生成式AI應用的一部分,隨著技術的進步,其應用領域將會更加廣泛。然而,生成式AI也引發了一些道德和社會問題,例如深度假人的問題,這需要我們在使用這種技術時謹慎考慮。
人工神經網路(Artificial Neural Network,縮寫為ANN)是模仿生物神經網路的計算系統,用於估算或近似函數。以下是人工神經網路的基礎概念:
每個神經元接收一或多個輸入,將它們加權總和,然後通過一個激活函數(如Sigmoid、ReLU等)產生輸出。
神經元可以組成層。
通常有三種層:輸入層、隱藏層和輸出層。
每個輸入都有一個權重,這些權重在訓練過程中調整以改善模型的預測。
偏置是神經元的一個額外輸入,通常有一個固定值(如1),它的權重也會在訓練過程中調整。
決定神經元是否應該被激活。
常見的激活函數包括Sigmoid、ReLU、Tanh等。
從輸入層開始,資料通過網路,最終在輸出層產生預測。
衡量模型的預測與實際值之間的差異。
訓練的目的是最小化這個損失。
一種算法,用於根據損失函數的梯度調整網路的權重和偏置。
用於更新網路中的權重和偏置以最小化損失。
常見的優化器包括梯度下降、Adam、RMSprop等。
透過多次的前向傳播和反向傳播,不斷調整權重和偏置以最小化損失。
過擬合是指模型在訓練數據上表現得太好,但在新的、未見過的數據上表現不佳。
正則化是一種技術,用於防止過擬合,例如L1和L2正則化。
這只是人工神經網路的基礎概念。實際上,神經網路的領域非常廣泛,包括卷積神經網路(CNN)、遞歸神經網路(RNN)等多種變體和技術。
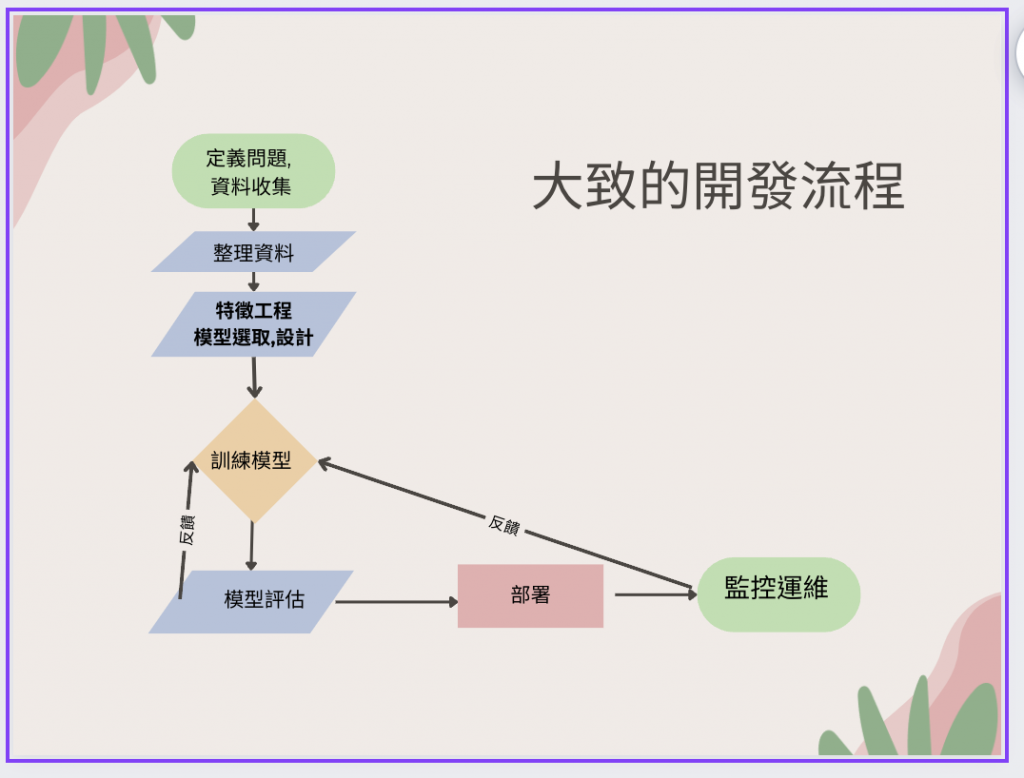
大體上跟下列的流程大同小異
深度學習和生成式AI的開發流程有許多相似之處,但由於它們的目標和應用場景不同,也存在一些差異。以下是這兩者的開發流程:
1.1. 數據收集:
根據問題定義,收集相關的數據。
數據可以是圖像、文本、語音等。
1.2. 數據預處理, 清理資料:
數據清洗:去除噪音和異常值。
特徵工程:選擇和構建適當的特徵。
數據標準化和正規化。
1.3. 模型設計,特徵工程:
選擇適當的神經網路架構,如CNN、RNN等。
定義損失函數和優化器。
1.4. 模型訓練:
使用訓練數據訓練模型。
監控訓練過程,避免過擬合。
1.5. 模型評估:
使用驗證數據集評估模型的性能。
調整模型參數以優化性能。
1.6. 模型部署:
將訓練好的模型部署到生產環境。
監控模型的實際性能。
2.1. 數據收集:
與深度學習相似,首先需要收集數據。
2.2. 數據預處理:
與深度學習的預處理步驟相似。
2.3. 模型設計:
選擇適當的生成模型,如GAN、VAE等。
定義生成器和鑑別器(對於GAN)。
2.4. 模型訓練:
訓練生成器生成逼真的數據。
訓練鑑別器區分真實數據和生成數據。
2.5. 模型評估:
使用多種指標評估生成數據的質量和多樣性,如FID、Inception Score等。
2.6. 應用和部署:
將生成模型應用於實際場景,如圖像生成、數據增強等。
與深度學習相似,也可以將模型部署到生產環境。
總的來說,無論是深度學習還是生成式AI,開發流程都強調了數據的重要性、模型的設計和訓練、以及模型的評估和部署。不過,具體的技術和方法可能會因應用場景和目標而有所不同。
附帶一提:
下面是 Andrew Ng的演講影片以及其他相關比較有趣的內容



 iThome鐵人賽
iThome鐵人賽