人工智慧是目前科技界與學術界都致力研究的領域,而其中人工智慧中又以機器學習 (Machine learning, ML)為一大子領域,而後機器學習又包含深度學習 (Deep Learning, DL)、監督式學習,非監督式學習、半監督式學習、強化學習等。而生成式AI目前包含在深度學習裡面,所以要學習生成式AI就必須具備一些深度學習的知識喔!
深度學習基本上是透過建立類神經網路 (Neural Network, NN),這個類神經網路相當於一個包含數以萬計參數的函數,透過固定的輸入去計算預測結果,並使用預測結果與正確答案計算誤差再透過反向傳播,調整並優化參數藉此讓這些固定的輸入經過神經網路以後可以得到與正確答案相近的結果。
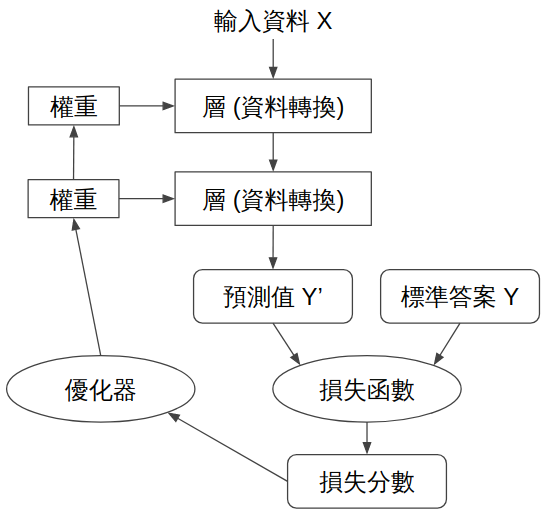
類神經網路訓練流程。圖源
間單來說類神經網路學習的流程如下:
隨機初始化參數、建立類神經網路模型
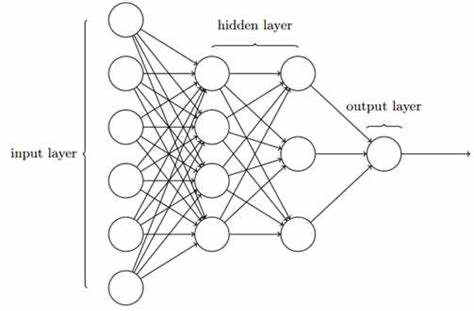
這部分就是根據自己定義的模型去隨機初始化所有權重參數。雖然是隨機,但隨機方式也是大有學問在,通常會採用一些機率分佈的方式來隨機化參數,使訓練過程不會過於不可控。類神經網路的架構大致如下圖:會有輸入層 (Input Layer)、隱藏層 (Hidden Layer)、輸出層 (Output Layer),可以看到每一層都有很多神經元。
根據輸入資料計算出預測結果
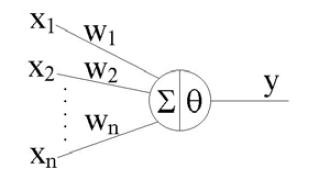
輸入資料都是固定的,所以類神經網路要根據這些資料輸入以及本身神經元的權重等計算結果,這結果就是類神經網路的預測值,訓練目標就是讓預測值與真實答案越接近越好。輸入資料就是各位要分析的資料集 (Dataset),這些資料在建立神經網路前會先進行資料預處理。下圖是輸入資料在經過一個神經元的情況。
首先輸入資料在經過每個神經元會進行加權,x1w1就是第一個神經元的加權,通常在計算加權過後還會加上一個偏差bias,結果就會變成x1w1+b1,接著這些加權過後的結果再相加 (Σ)並經過激活函數θ計算,成為這個神經元的輸出。
預測結果與正確答案計算誤差
因為初始化參數是隨機的,所以正常來說第一次預測結果一定都有誤差。誤差的部分通常也會根據不同需求採用不同函數去計算誤差。誤差函數又稱損失函數 (Loss Function)。
| 任務類型 | 損失函數 |
|---|---|
| 迴歸分析 | 均方誤差 (Mean Square Error, MSE)、平均絕對誤差 (Mean Absolute Error, MAE) |
| 分類問題 | 交叉熵 (Cross Entropy) |
根據誤差反向傳播計算所有權重的梯度
這部分會牽扯到偏微分計算,對於入門者是比較不友善的部分,但簡單來說就是根據誤差去計算梯度,梯度的功能就是讓神經網路知道接下來優化的方向為何。
反向傳播就類似當你在玩遊戲,但一直贏不了,這時候就會根據角色選擇、開技能的時間等去做微調,慢慢微調情況以能夠通關。在這過程中就類似反向傳播的概念。
透過優化器更新所有參數的值
知道優化方向後就要根據優化器去實際更新權重了,優化器的用意是根據不同方式去優化神經網路,使神經網路收斂。優化器參數沒設定好則容易導致神經網路無法收斂或者陷入局部最佳解。不同優化方式也有優缺點,目前較常使用的是ADAM、SGD等。
局部最佳解就像當你在爬山,目標是最高點,你爬到了一座山頂,當你以為你已經爬到頂峰了以後卻發現旁邊的山更高,這時候你就勢必要下山再往另一座山攀爬。但神經網路不知道旁邊的山是不是更高,所以有時候會為了保險起見就待在目前這個山峰上,不另外做探險,這就是局部最佳解的概念。
重複步驟2~5 ,直到訓練結束
接著就是重複這些步驟,直到設定的訓練時間結束。接著就可以分析模型的效能了,通常有許多評估方法可以使用,以良好的分析訓練出來模型的能力。
| 任務類型 | 評估方法 |
|---|---|
| 分類問題 | 準確率、Recall、Precision、F1 score |
| 回歸問題 | MSE、MAE |
| 圖像生成模型 | FID、KID、LPIPS、PSNR、SSIM |
通常訓練時的資料都會分為訓練資料、驗證資料、測試資料。訓練資料就是要讓神經網路訓練的資料;驗證資料就是在訓練中要驗證神經網路學習狀況的資料 (驗證資料通常會從訓練資料拆分);最後訓練完會再使用測試資料來評估模型訓練的情況好不好。
換句話說訓練資料就是在上課時老師教學的東西;驗證資料就是老師上完課以後隨機提問,小考的部分;而測試資料就是學習完後期中期末考的內容,即用來評估是不是真的有學習到東西。
若是把課本的內容記的滾瓜爛熟,但在考試時無法應用自如,即過度擬和 (over-fitting);課本內容沒學習好,考的也亂七八糟即低度擬和 (under-fitting)。所以對於訓練以及之後的評估都要做好,才能完整分析神經網路的能力!
以上就是類神經網路的基本介紹,其中數學概念等並非這次的重點,故省略這些篇幅。類神經網路是深度學習中必備的技術。那要如何建立類神經網路呢?其實有許多深度學習框架可以使用,對於想入坑的人來說是非常方便的工具,目前較常見的深度學習框架有:Tensorflow、Keras、Pytorch、Mxnet等等,他們都是在Python上使用的。本系列文章都會使用Tensorflow與Keras,明天會開始介紹這兩個套件的基本用法等知識。


 iThome鐵人賽
iThome鐵人賽