昨天帶各位實作了DDIM模型,不知道各位是否有成功實作出來?今天我們要來看看昨天的DDIM訓練時的損失變化與圖片生成的過程。看完了以後再來分享一下擴散模型訓練上常出現的問題以及未來的展望!
我們來看看損失的變化圖: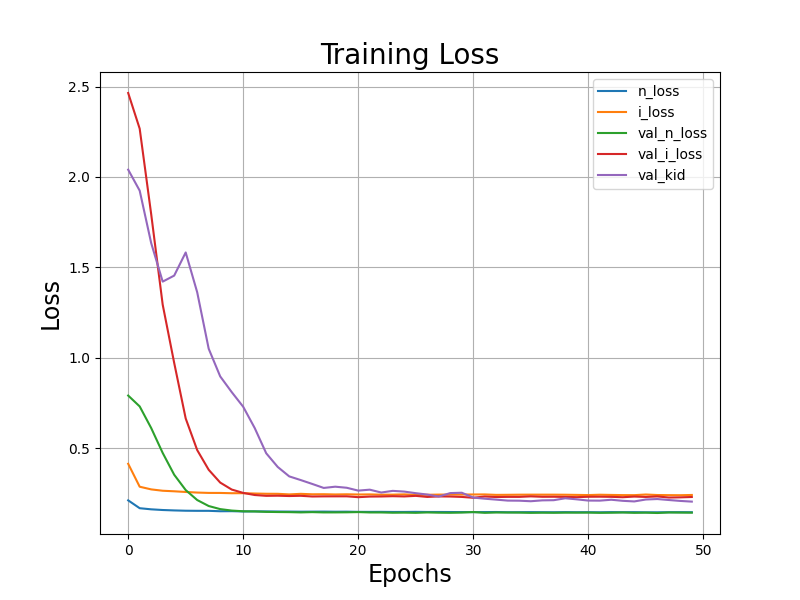
可以看到所有損失都有逐漸降低,而且大約20 epochs模型就收斂了,不過每個epoch會訓練幾萬張的圖片。所以訓練量應該是足夠的。主要看到KID有下降就代表圖片的品質有提高。 n_loss 下降代表模型有學到擴散過程的分布狀態。
接著就是擴散模型訓練過程中生成的圖片了,
Epoch=1。與GAN一樣,第一次訓練當然都是雜訊。
Epoch=5。從雜訊中似乎有新世界即將誕生,雖然圖片還是很亂,但這只是模型還尚未學習到最佳的逆向擴散方式。
Epoch=8。花朵的輪廓已經大致上看的出來了,部分圖片會有一些亂亂的感覺。
Epoch=15。已經可以生成出美麗的花朵圖片~
Epoch=50。基本上都沒什麼變,模型已經收斂了。
另外也有擴散模型訓練過程的圖片變化,這個模型的訓練動畫跟GAN感覺起來不太一樣,感覺有種用魔法來塑型的fu。
這邊再附上資料集不夠、訓練次數不足或者生成任務難度較高的失敗圖片,這些圖片背後都有一個調參數到心累的可憐人QQ:
這些失敗品所使用的資料集來源於此。facades labels→photo
是大麻,我加了大麻。 (這個資料集是昨天範例所使用的資料集)
參數量太少、訓練256x256的圖片後,學到了一些圖片特徵,但沒辦法把這些特徵好好的組合。
這次換訓練資料集太少,模型完全學不到東西,生成了像塗油漆的痕跡。
接著模型參數量太大、層數太多,在某個Epoch梯度爆炸,之後生成的圖無藥可救。圖片像雜訊倒還好,有時候會全黑、全紅、全藍等莫名其妙的狀況發生QQ
最後是調到一個比較好的參數,但目標是想要生成房子的外觀圖片,反倒生成了鬼屋。
擴散模型的生成能力超乎想像,而且聽起來好像非常強大,但是擴散模型有甚麼缺點或者訓練上的問題呢?當然有!現在就來看看目前訓練擴散模型上可能會遇到甚麼問題吧。
前幾天介紹的擴散模型,在圖像生成以外,也有許多應用被發展出來,如以下幾點。這邊會貼上一些來自於CVPR 2023 或者CVPR 2022 的研究,CVPR是計算機視覺中頂尖的研討會,每年都有高質量的研究被提出來,其中就有許多跟擴散模型有關的研究。
其他還有擴散模型的用途真的不勝枚舉,基本上許多最新的研究也都跟擴散模型的發展相關。目前主流的研究成果都還是與圖片、影像生成相關,相信未來也會有更多領域的研究使用擴散模型生成各種資料!
在建立擴散模型的過程,我們使用U-Net來訓練,正當我們認為U-Net已經是極限的時候。這時候另一個模型又殺出來了,那就是現今自然語言處理NLP常會使用的Transformer模型。Scalable Diffusion Models with Transformers 這篇文章在2012年12月刊登上Arxiv,2023年3月發布新版本,算是非常新的版本。該研究使用了Transformer來取代傳統的U-Net,而且性能優於當時所有的擴散模型。所以使用不同的模型來訓練擴散模型也可以訓練出良好的結果,而且可能還有別的功能,非常讓我感到意外。例如今年有一篇文章用擴散模型產生室內空間的2D平面圖,就是使用Transformer模型訓練的。有興趣可以直接看看該研究的論文!
今天帶各位分享了DDIM的訓練過程,以及擴散模型的未來展望等等。擴散模型作為最新的模型雖然文獻量還不是很多,還有許多問題尚待探索。但我覺得生成式AI的發展真的非常快,應該過沒多久這些問題就會被解決,或者基於這些模型的其他變種模型就會被發展出來了。總之這些模型的未來發展真的令人可期!
生成模型的介紹到此告一段落,明天會來介紹生成模型常用的指標。每個指標都有自己的特色以及背景,各位在學會以後就可以拿去評估自己的生成模型啦!

