前一篇文章提到了第一波針對 APIGW 的監控修正,但因為最後發現的各種問題,導致我們要進行第二波針對這個監控的修正。
主要是,在某一次緊急的 P0 事件會議中,我們發現該事件的發生理由是因為 APIGW 壞掉了,但我們所建立的監控系統卻沒有正常的被觸發。
事後我們發現,主要是因為監控系統從一開始就沒有被觸發,請見下圖:
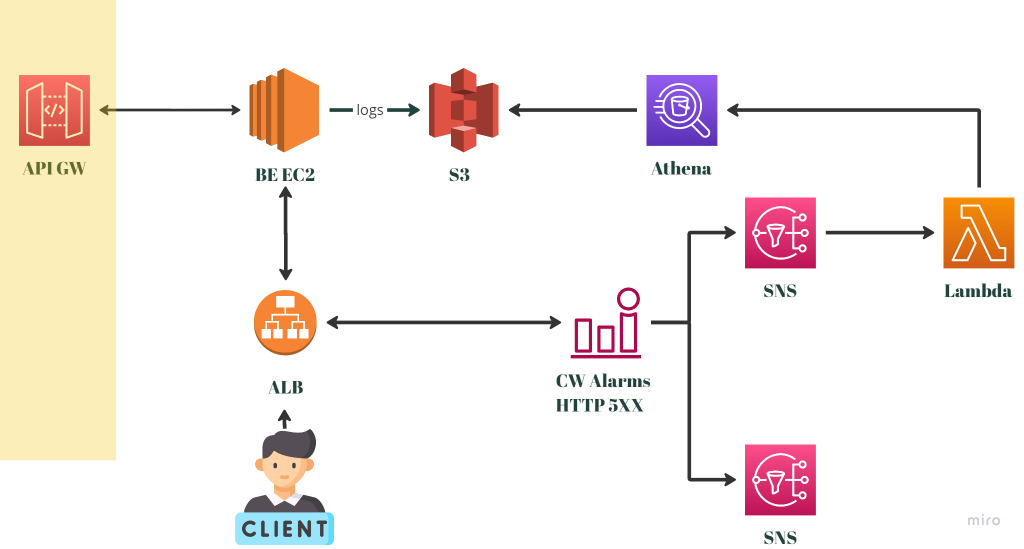
換個說法來講, 5XX HTTP Status Code 跟本沒有上升到異常的數量等級。這是完全沒有預期的狀況,而在經過一連串的確認之後,才發現因為後端在這一支 API 上使用的技術是 GraphQL ,而非一開始預期的 RESTful 。因此,即使在 APIGW 發生問題的狀況之下,後端也是回200的HTTP Status Code。
既然這邊已經確認問題,那接下來就是思考應該怎麼修正目前的監控系統了。
首先最直觀的做法,在上一篇文章也有提到,就是透過 EventBridge 來每 5 分鐘觸發一次 Lambda 。而這個做法最大的問題,就是成本實在太過高昂。那接下來的思考就會是有沒有什麼辦法能夠降低這邊的成本呢?
我們可以再來細究一下成本高昂的原因,成本主要跟據 Athena Query 本身要掃描過的資料範圍。成本高昂的原因是因為我們的系統日誌資料非常龐大,那有沒有辦法降低我們掃描的資料範圍呢?
因此在這邊我們得到了一個另一個解方,就是請後端工程師特別將 APIGW 無法存取的日誌分離出來,用一個獨立的 S3 Bucket 來存放。這樣我們在掃描資料的時候讀好就可以獨立掃描這個部分的資料,因為資料本身相對於系統日誌一定會少非常多,就可以解決成本高昂的問題了。
修改過後的架構會變成如下圖:
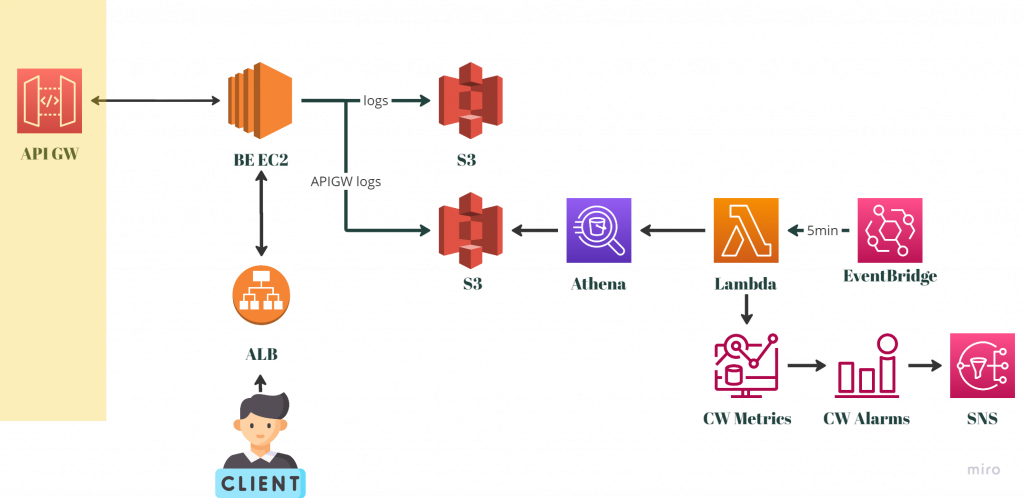
然而,有沒有辦法再進一步節省成本呢?因為 APIGW 的日誌量可能實際上非常的少,發生的頻率甚至遠超過 5 分鐘。換句話來講,我們可能要掃描很多次才會有一筆資料,而每次的白掃描都會是成本的浪費。
因此,我們也思考透過 S3 Event Notification ,也就是 Event Trigger 的方式來觸發 Lambda 。當然在這個狀況下的 Lambda 就不是執行 Athena Query 了,而是直接把拿到的資料作成 CloudWatch Metrics 。
實際上,在書寫這篇文章的當下,我們還沒有決定要使用哪個方式,因為這必須要在上面架構被部署到正式環境之後,再根據觀察到的日誌的頻率,來確定我們要怎麼做。
而且實際上,因為我們整個架構大翻新的關係,未來我們可能會選擇另一個負責收集日誌的方式,而到時候又會是一輪討論和修正。也許筆者這篇文章再晚一點寫的話,就可以有第三波監控修正的文章了呢。
另外一個值得一題的部分,這是我們監控的空窗期。讀者應該可以發現,我們目前針對 APIGW 的監控系統因為其實無法被觸發,相當於是我們其實沒有任何的監控。而未來在日誌收集伺服器下架的那段時間,也可能會發生類似沒有監控的狀況。
因此,我們其實有嘗試著和產品經理討論,單純在這段空窗期上架舊監控系統的可能性。不過從產品經理的角度來看,因為這是被客戶明確拒絕的東西,因此這可能也不是一個可以採用的解決方案。
筆者想分享的事情主要是,其實在建置監控系統的時候,我們不只從技術上會有各種考量和選擇,也會出現很多其他非技術的考量點。而SRE其實是一個會需要花費大量時間與不同團隊溝通的工作,這是如果對這份工作有興趣的人,一定要先知道並理解的事情。
下一篇,想介紹另外一個客製化的特別監控系統。


 iThome鐵人賽
iThome鐵人賽