上篇文章已經介紹了一個客製化的特別監控系統,這篇文章則會是另外一個,希望能夠藉由這2個系統,讓大家可能理解SRE是為了什麼而做監控。
這個監控系統主要是為了監控我們資料庫的異常存取行動,而這來自於我們的這個專案想要導入ISO 27001。如果你不知道ISO 27001是什麼,那你可以把它理解為是一種規範系統符合某種特定的安全標準的規定。
舉個例子, 如果你去買了一個便當,當然你的目標是為了吃便當,但你也不希望你在吃完便當之後因為食材的衛生問題而拉肚子。假設現在有一個便當界的ISO 27001,那符合該規範的便當就必須在製造過程符合一定的規範與標準,比如食材的衛生,便當盒子用料等等。
至於在我們系統上所導入的ISO 27001,就會是遵循一套類似的標準。通過這套標準並不會讓使用者在使用上有什麼明顯的感受差異,但可以比較保證客戶在使用上的安全性。比如比較能保證使用者存取在資料庫的資料不容易被竊取等等。
關於ISO 27001,因為在敝公司也是SRE的主要業務之一,因此比較細節的部分會在之後的文章再與大家分享。
ISO 27001規定我們要針對資料庫的異常登入進行監控,比如在資料庫被攻擊或有任何異常行動的時候,能夠有比較即時的應對措施。
經過與產品經理一連串的討論之後,我們決定的方案是,在資料庫使用者有異常登入的狀況的時候,先立刻關閉該使用者的存取權,等到上班時間再由相關的負責單位通知該帳號的使用者,確認該異常行動的發生成因以及接下來的對應措施。至於異常登入的定義則是5分鐘內有超過10次的登入失敗紀錄。
請參考下圖的架構:
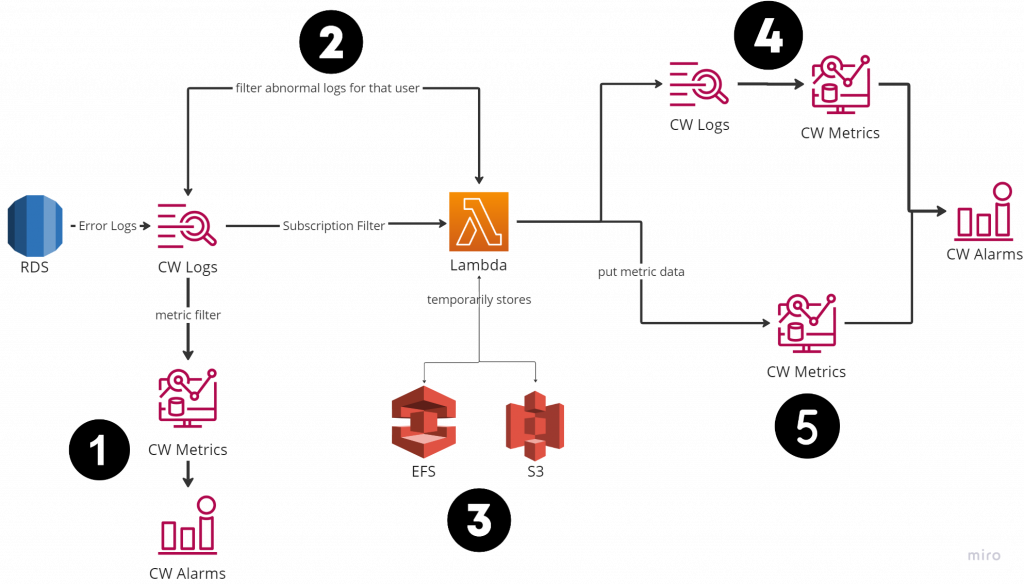
從上圖中可以看到,這邊的架構設計至少有五種路線可以選擇。我們所使用的資料庫是Amazon RDS,因為使用者登入失敗的話,會以錯誤日誌(Error Logs)的形式將登入失敗的資訊存在CloudWatch Logs裡面,因此這邊的架構選擇,就會從CloudWatch Logs開始而有所分歧。
只要有任何的錯誤日誌被觸發,就會啟動這個監控系統的機制。
第一條路,是透過metric filter的方式來直接建立CloudWatch Metrics,再透過CloudWatch Alarm來監控該metrics的異常狀況。這條路因為最單純的關係,原本是最理想的選項,無奈因為無法順利抓出使用者名字的關係而宣告失敗。
無法抓出使用者名稱的原因如下圖:
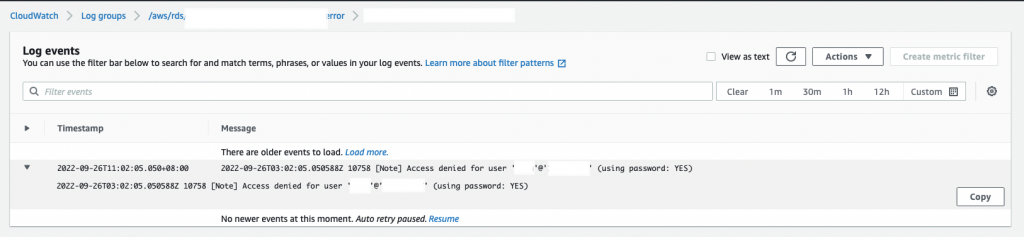
在使用者登入失敗的錯誤日誌裡面,顯示的使用者pattern為’<user_name>’@’<IP_address>’,我們可以透過空格來篩選出我們想要的東西,但因為這裡的使用者名稱與IP中間空格切割,而是以「@」來切割,導致無法成功。
接下來的其它所有選擇,都是透過Subscription Filter來串接Lambda,並在Lambda後面執行不同的加工方式。
因為Lambda每次的觸發都是獨立無狀態的(stateless),但我們的需求是判斷是否達到「5分鐘內登入失敗超過10次的標準」,因為每次登入失敗的觸發都要同時判斷之前登入失敗的狀況,因此一個有狀態的(stateful)需求,所以我們要先想辦法解決這個問題。
第2條路的做法,是在每次觸發Lambda的時候,回去CloudWatch Logs裡面翻最近5分鐘內的錯誤日誌的資料。比較之後如果符合異常登入的標準,那就會直接聯絡執班工程師來執行後續的行動。在這個解決方案中,登入失敗的狀態是存在CloudWatch Logs中的。
第3條路的做法,則是在觸發Lambda之後,把登入失敗的資料存放在EFS或S3裡面。與上一條路類似,是透過比較之前的資料來判斷是否符合異常登入的標準。
第4條和第5條路都是將異常登入的狀態存放到另外一個CloudWatch Metrics中。不同之處在於,第4條路是跟據Lambda本來就會產生的CloudWatch Logs,來建立相對應的CloudWatch Metrics(當然必須在Lambda中把想要的資訊印出來才行);而第5條路則是直接透過CloudWatch的API來建立CloudWatch Metrics。
我們最後認為第5條路是比較理想的選擇。一開始就先排除了第2條和第3條,因為我們希望監控本身不只是事件觸發而已,最好還能夠有metrics方便隨時查看異常登入的歷史資訊。優先選擇第5條路而非第4條路,這個單純只是因為第5條路在架構上比較單純而已。
雖然在前一段中,我們最後認為第5條路是比較理想的選擇,但實際上我們目前是先使用了第2條路的方式。這主要是因為在一開始建立監控系統的當下,我們還沒有能力根據metrics來動態產生alarm。
會需要動態產生,是因為我們的資料庫使用者會隨著時間而改變。每個使用者都會是一個相對應的metrics。如果我們在每次增減使用者的時候都手動增減與metrics相對應的alarm,那這樣會耗費大量的人力成本。
不過這個問題,在我們公司一個非常厲害的資深前輩,開發出一套能夠動態跟據metrics來產生alarm的系統後就解決了。
另外一個值得分享的事情則是,在ISO 27001被導入之前,其實我們的資料庫是使用同一組共用的帳號密碼來存取的。因此如果我們需要做到對使用者的異常登入行為的監控,前置作業就會是先區分不同的使用者。
雖然這看似簡單,但在龐大而古老的系統面前,任何看似單純的改動都有可能發生意想不到的後果。因此在正式建立這個監控系統之前,我們其實也化了相當多的時間在討論以及POC。
最後則是警報在觸發後的行動。目前是由另外一個負責的團隊來接手警報觸發後的關閉異常帳號的行動,但是這種單純的動作應該要有辦法開發出一個自動化的系統才是更理想的。因此這套系統之後也會朝這個方向改善,而整套架構也許還會再有一些增加與修改。
在這邊筆者想分享給大家的,主要是這種客製化的監控系統,除了技術上的選擇之外,也可能會因為各種原因,而導致必須要先做出一個臨時而且不是那麼完美的版本,等到之後有時間的時候再將它修繕到完美。
這裡所遇到的非技術挑戰,會與上一個特別監控系統所遇到的挑戰截然不同。但無論是哪種挑戰,筆者都希望帶給大家一個重要的心態,就是SRE其實是一個會需要花費大量時間與不同團隊溝通的工作。有時候技術上的考量反而是比較次要的,相信讀者閱讀到這邊,應該也或多或少能夠理解這件事情吧?
從下一篇開始,我們將進入日常維運的系列。


 iThome鐵人賽
iThome鐵人賽