今天開始要來介紹生成對抗網路 (Generative Adversarial Networks, GAN)了,這是一個跨時代的生成架構,能生成高質量的圖片。前幾天有稍微介紹GAN以及其變種,今天會更加詳細說明GAN到底在幹嘛,為之後的實作先鋪上一些理論基礎。
GAN一言以蔽之就是使用兩種神經網路,分別為生成器 (Generator)與判別器 (Discriminator)在進行對抗訓練,其訓練be likes:

在旁邊納涼看戲的就是我們這些寫程式的人XD
GAN是在2014年被當時在念蒙特婁大學博士生Ian J. Goodfellow所提出,他也曾在Google Brain擔任研究學者以及在Apple公司擔任過機器學習總監等,真的是非常厲害的人物。在提出GAN以後不到幾年GAN的研究就呈現指數型的增長,反映出GAN在人工智慧、資料生成任務的發展性。
以往圖像生成的任務只訓練一個神經網路進行圖片生成,例如自動編碼器 (Auto Encoder, AE)、Normalizing Flow等,更多的生成模型請參考下圖,這些模型都各有特色。而GAN使用了兩個模型進行訓練,也就是生成器與判別器,這個訓練是非監督式的學習,透過生成器與判別器互相博弈的方式進行學習。使生成器能夠盡量生成可以騙過判別器的數據;而判別器則要盡量能夠分辨出數據是真是假,透過不斷的訓練最後其訓練的目標函數理論上會達到平衡。也就是納許均衡 (Nash Equilibrium)的情況,即生成器無法再提高其欺騙能力,判別器也無法再提高其分辨能力。接著我們就來一個一個名詞解釋,讓各位了解生成器、判別器、納許均衡、目標函數是甚麼。
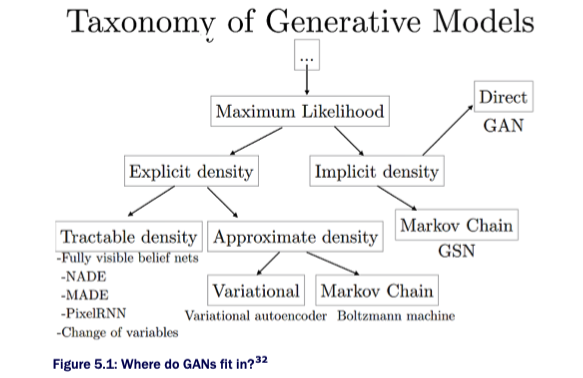
生成模型的種類 (截至2019前)。[圖源]
1.生成器:生成器會從符合常態分布的潛在空間 (Latent Space)中採樣一批數據,也就是雜訊,並輸入至生成器中,透過生成器生成一張假的數據分布,例如圖片、音訊、文本等。並且要嘗試欺騙判別器使判別器認為這些生成圖片是真實的數據。從下圖訓練流程中可以看到生成器的訓練方式。
2.判別器:判別器的目的是從真實數據或生成器產生的數據中分辨出真假,從流程圖中可以看到從資料集 (Dataset)中取出要訓練的真實資料,接著生成器生成的假圖片與真實資料會一起被送入判別器中再由判別器來分辨真假。
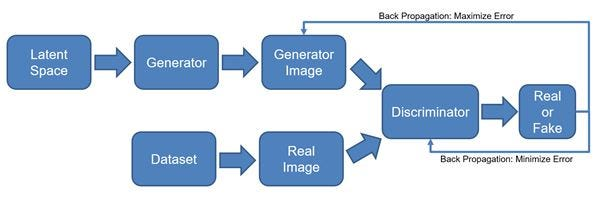
生成對抗網路訓練流程。[圖源]
判別器的目標be likes:
3.目標函數:基本上生成器訓練與判別器訓練都是使用交叉熵,因為無論是生成器要騙判別器生成圖片為真的圖片還是判別器要分辨真假圖片時都會經過判別器判斷真假,而在判斷真假時算是分類任務,此時會使用的就是交叉熵。但是生成器與判別器對目標函數的優化目標不同 (生成器要最小化、判別器要最大化),所以就會變成對抗式的訓練。根據原始論文 中所提及的目標函數如下: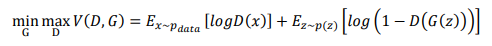
雖然看起來很複雜,但其概念就是如同上面說明的一樣。其中x是真實圖像;z是雜訊;Pdata是真實數據分佈,x~Pdata代表從真實數據中取出一批資料x; pz(z) 是雜訊分佈,同理 z~pz(z) 就代表從常態分佈的雜訊中取出一批雜訊z; D(x) 是判別器對 x 的真假判斷機率; G(z) 是生成器根據雜訊生成的圖像。前面的項次是將目標函數理解為交叉熵損失函數,它衡量了判別器對真實圖像和生成圖像的分類能力。當判別器固定、在訓練生成器時,生成器會嘗試最小化這個函數,也就是讓判別器對生成圖像的判斷機率越接近1越好。
D(G(z)) 接近1時,代表判別器判斷生成資料是真實資料,此時log(1-D(G(z))) 就會變成負數,另外log D(x) 可以忽略,因為訓練生成器並不會丟真實資料進去判別器。當1-D(G(z)) 趨近0,此時目標函數就會變成負的。
當生成器固定、在訓練判別器時,判別器會嘗試最大化這個函數,也就是讓判別器對真實圖像的判斷機率越接近1越好。
log D(x) 要趨近1,代表判別器判斷真實資料為真實資料。
而對生成圖像的判斷機率越接近0越好 。
log(1-D(G(z))) 要趨近0,D(G(z)) 就要接近0,代表判別器判斷生成資料是假資料。
上述兩個項目都趨近於1,代表判別器在努力最大化目標函數;生成器則是要讓結果盡可能變為負數,也就是最小化目標函數。生成器要最小化目標函數、判別器要最大化目標函數,此時就形成了一個博弈的過程,此時不斷訓練之後理論上就會達到一個平衡點,也就是等等要介紹的納許均衡。
這邊我再附上 log D(x) 與 log(1-D(G(z))) 的圖,方便各位直觀的從圖片中看出GAN的目標,藍色線代表生成的假圖片經過判別器判斷的結果;橘色線是真實圖片經過判別器判斷的結果,橫軸是判別器的判斷 (判別器是二元分類,所以會用sigmoid激活函數,值會在0~1之間),縱軸是這個判斷放到目標函數中的結果值。對於生成器來說只需要注意藍色線,此時若生成圖片經過判別器判斷為真 (D(G(z))=1)代表生成器可以以假亂真了,那看藍色線在1的位置時為最低點。接著對於判別器來說判斷生成圖片為假 (D(x)=0)時看藍色線可知在最高點、真實圖片為真 (D(x)=1)時看橘色線也在最高點。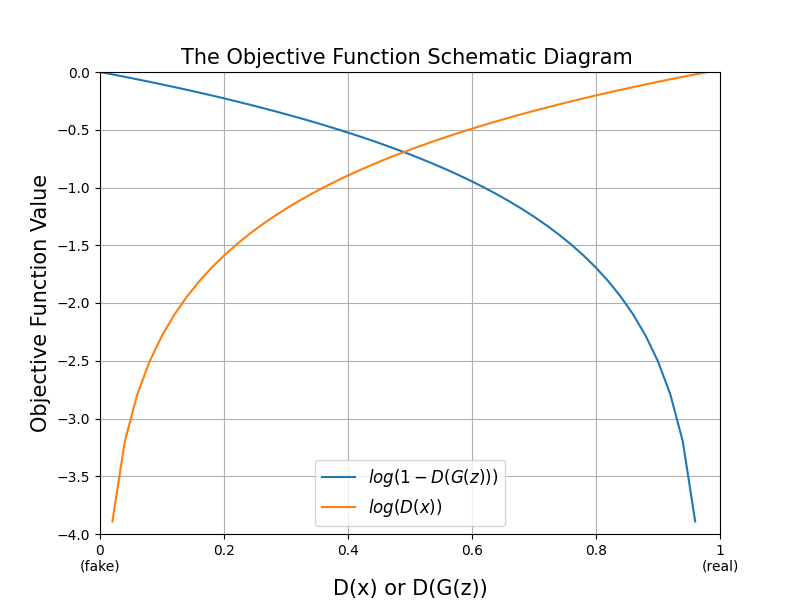
不過基本上訓練還是以設定交叉熵等損失函數為準,目標函數只是使用數學的語言來告訴我們GAN是如何運作的、損失函數如何設定,以及理論上的建模。
4.納許均衡:納許均衡是賽局理論中的一個重要概念,它指的是在一個非合作賽局中,每個參與者都選擇了自己的最佳策略,並且沒有人能通過改變策略來提高自己的收益。換句話說,納許均衡是一種平衡狀態,使所有參與者都能接受結果。
舉例來說,囚徒困境是一個著名的賽局理論例子,它描述了兩個共犯被捕後面臨的選擇。假設兩個共犯A和B被分別關押在不同的房間,不能互相溝通。警方給他們各自提出了一個交易:如果A揭發B,而B保持沉默,那麼A可以立即獲釋,而B要坐牢10年;如果B揭發A,而A保持沉默,那麼B可以立即獲釋,而A要坐牢10年;如果他們都揭發對方,那麼他們都要坐牢8年;如果他們都保持沉默,那麼他們都要坐牢1年。這個賽局可以用以下的表格來表示:
| B揭發 | B沉默 | |
|---|---|---|
| A揭發 | A坐8年牢, B坐8年牢 | A獲釋, B坐10年牢 |
| A沉默 | A坐10年牢, B獲釋 | A坐1年牢, B坐1年牢 |
在這個賽局中,無論B選擇什麼策略,A都會傾向於選擇揭發,因為這樣可以使A減少自己的刑期;同理,無論A選擇什麼策略,B也都會傾向於選擇揭發。因此,這個賽局的納許均衡是兩個共犯都選擇揭發對方。然而,這個結果並不是對他們最有利的。如果他們都能夠信任對方並保持沉默,那麼他們都只需要坐牢1年,這是一個最優的結果。但在缺乏溝通和合作的情況下,他們都會出於自利而選擇揭發,從而陷入囚徒困境。
5.對抗網路:對抗網路是指將生成模型與判別模型接在一起,並透過固定判別器的方式來訓練生成器,因為生成器在訓練時還是要讓判別器判斷生成圖片的真假 (但希望都是判斷為真),所以會將生成器的輸出直接接到判別器的輸入,這個模型即為對抗模型。
講了那麼多到底GAN如何訓練,這邊幫各位總結一下,GAN的訓練步驟大致如下:
這只是GAN在正常流程下訓練的步驟,當然不同的GAN可能有一點差別,不過基本上流程就是這樣,其餘細節我將會在未來待各位實作。
以上今天就是GAN開始實作前的最後一次補充了,希望各位都有理解GAN的原理。之後就會帶各位實際的操作啦,明天會向各位分享我在開發GAN的一些習慣與流程,我將會簡單的介紹生成模型在開發上的流程,這是我在寫過幾個模型之後整理出來的SOP,雖然習慣上都一定會有差異,但希望可以讓對寫生成模型沒有頭緒的人一點參考。後天會帶各位建立一個基本的GAN模型,用於生成mnist手寫數字圖片資料集。若是對寫程式有興趣的人希望兩天後實際寫生成模型時你能夠有所收穫。
“The best way to learn deep learning is to do deep learning.” — Ian J. Goodfellow

