再來就可以開始在python裡面使用啦
先導入會用到的套件
from bs4 import beautifulsoup
import requests
我們會先需要取得網頁的html檔(以ptt stock版為例)
url = "https://www.ptt.cc/bbs/Stock/index.html"
content = requests.get(url).text
將獲取到的html解析成soup
soup = BeautifulSoup(content, "html.parser")
html.parser指的是以html的形式解析,還有其他可以使用的解析方式比如說lxml、xml、html5lib等。有些為外部解析,需要下載外部套件如 lxml 和 html5lib
比如我需要得到的是每個文章的標題
按下F12 後找到這個按鈕
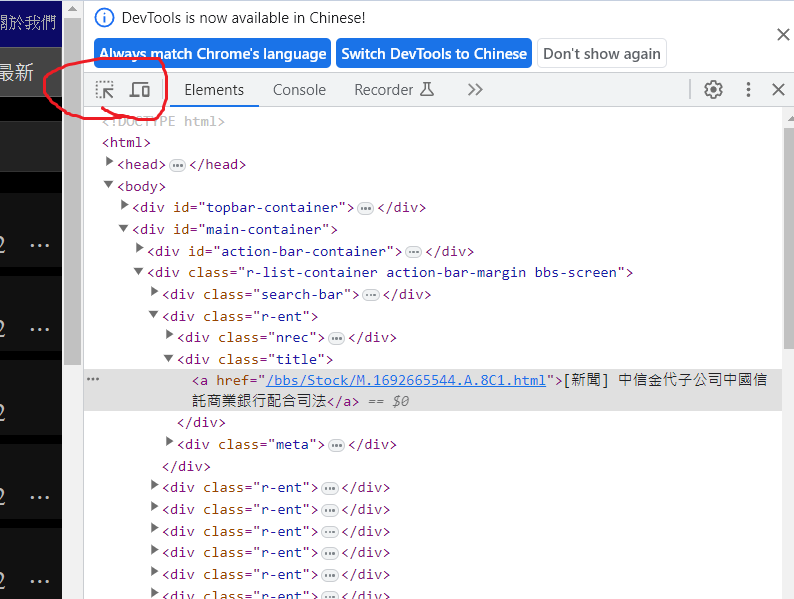
用這個游標點一下標題
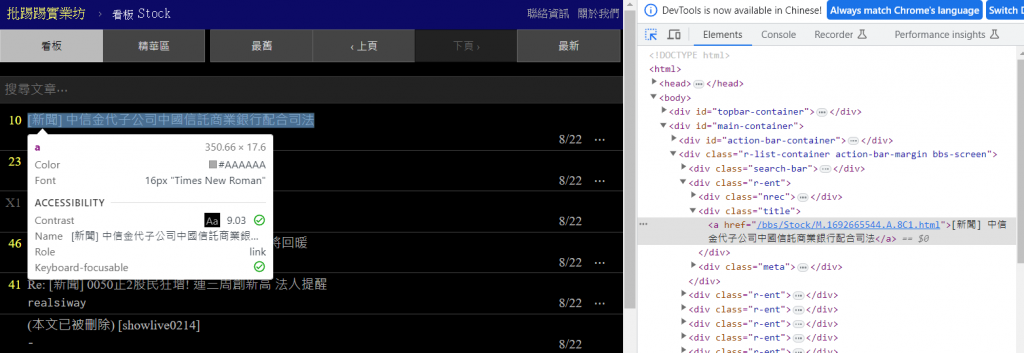
我們可以看到右邊的html碼也出現了深色的部分,那就是我們要找的標籤,這個很重要請記住這一段<div class="title">,再來請多使用這個方法點選其他標題,就會發現所有的標題都有著這一段<div class="title">
將解析後的soup搜尋標籤
first_title = soup.find("div",attrs={"class":"title"})
all_titles = soup.find_all("div",attrs={"class":"title"})
find()和find_all()的差異大家應該都看得很白話吧!find 是搜尋第一筆資料,find_all則是搜尋所有資料並全部儲存起來,attrs有著{'key': 'value'}的用法,用來挑選我們在這個html裡面需要取得什麼,<div class="title">這邊可以看到class為鍵,title為值。
把title印出來試試看
print(first_title)
print('-------------------------------------------------') #分隔線
print(all_titles)
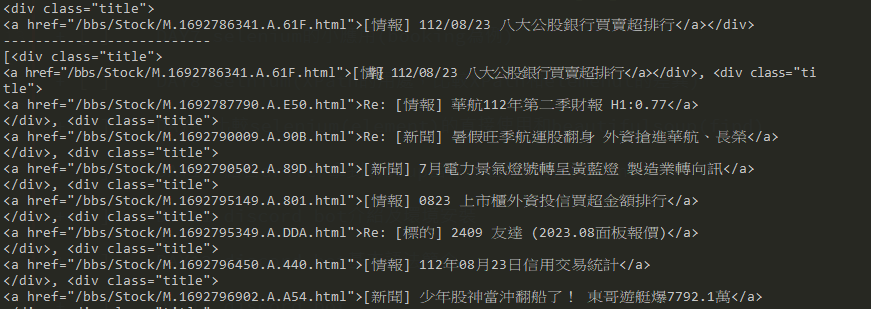
仔細看看可以發現,all_titles是以list包起來的,已經可以看到這大約是我們想要的結果,再來我們只想要裡面的文字,該怎麼做呢~
沒錯那就是使用.text這個方法拉
print(first_title.text)
print('-------------------------------------------------')
for title in all_titles:
print(title.text)
可以看到因為all_titles因為是list,所以會使用for來逐一取出作.text的動作
到這裡,你已經學會用beautifulsoup來做到最基本的爬蟲拉,下一篇我們將會知道beautifulsoup的難處在哪

