這邊舉一個簡單的例子,先到booking
比如說我今天要抓取第一個飯店的名稱,比照之前的操作,點開F12找到選定的游標後點選飯店名稱
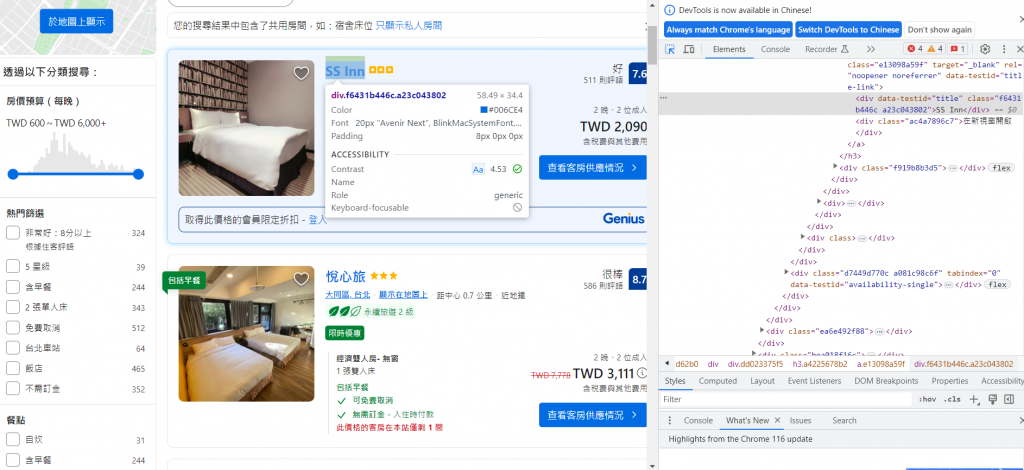
這裡可以看到我們要的東西已經看到了data-testid="title",跟上次一樣將url改成booking,以及attrs條件替換成data-testid="title"
url = f'https://www.booking.com/searchresults.zh-tw.html?ss=台北&checkin=2023-08-10&checkout=2023-08-12&group_adults=2&no_rooms=1&group_children=0'
content = requests.get(url).text
soup = BeautifulSoup(content, 'html.parser')
all_titles = soup.find_all("div",attrs={"data-testid":"title"})
for title in all_titles:
print(title.text)
讓我們試試看結果如何

其實很簡單,因為這些<div>他並非是靜態的html,而是由javascript生成出來的,所以requests沒有辦法抓取到這些資料,requests是不會經過網頁渲染就回傳網址內的html。許多現代網站使用JavaScript來動態生成內容,例如通過AJAX請求獲取數據並在頁面上動態顯示。BeautifulSoup僅在解析原始HTML時有效,對於在客戶端生成的內容無能為力。
無法執行JavaScript: BeautifulSoup不執行JavaScript代碼,這意味著如果網站使用JavaScript來修改或添加內容,BeautifulSoup無法模擬這些操作,因此無法獲取這些動態生成的內容。
事件處理和互動性: 動態網頁可能包含互動元素,如下拉菜單、點擊按鈕等,這些互動性的操作可能會導致網頁內容的變化。BeautifulSoup無法模擬這些互動,因此無法獲取基於互動產生的內容。
動態載入: 一些網站使用動態載入技術,僅在用戶滾動到某個位置時才載入額外的內容。這種情況下,BeautifulSoup只能獲取當前可見區域的內容,無法獲取所有動態載入的數據。
BeautifulSoup對於解析靜態網頁非常有效。但是當面對動態生成內容、互動性和JavaScript操作時,它的功能受到限制。如果需要處理動態網頁,可能需要考慮使用其他工具,比如Selenium,它可以模擬瀏覽器行為,包括執行JavaScript和處理動態生成的內容。
不過沒有關係,因為下一篇就要開始介紹selenium啦

