前一篇提到了 userdata 中透過 AWS CLI 來下達註冊 OpsWorks 的指令,會有失敗的可能性。這篇主要會來分享實驗過程與解決方式。
實驗的第一步,就是先嘗試在開發環境重現這個問題。重現問題本身並不困難,因為觸發條件就只是一次性地大量加開機器而已。因此要做的事情,就是找到需要註冊 OpsWorks 的 EC2 服務,並在該服務的 ASG 中,一次透過大量調整 EC2 的數量(desired capacity)來達到這個目的。而跟據幾次實驗的結果,平均每 12 台 EC2 中,會有 1 台出現註冊失敗的狀況。
提個外話,做為一個超級菜鳥接手的第一個任務,雖然只是這樣開開關關機器,但因為數量龐大的關係,筆者當時其實也是懷著既興奮又忐忑的心情在做這件事呢。真希望未來也能不要忘記像當初這樣的心情。
緊接著就要開始尋找解決方法了。由於第一個能介入的施力點就是 userdata 本身,因此筆者嘗試著在 userdata 中直接引入錯誤處理的機制。具體而言,在註冊 OpsWorks 的指令之後,再加上一個確認註冊成功的指令,而如果確認註冊失敗,則發出要求 EC2 關機(terminate)的指令。
以下分享經過修改後的指令(原本只有 opsworks register 而已):
REGISTER_AND_ASSIGN_OPSWORKS() {
OPSWORKS_INSTANCE_ID=$(/usr/local/bin/aws opsworks register --use-instance-profile --infrastructure-class ec2 --region us-east-1 --stack-id <省略> --override-hostname $sug_hostname --local 2>&1 |grep -o 'Instance ID: .*' |cut -d' ' -f3;);
if [ -z \"$OPSWORKS_INSTANCE_ID\" ] ; then echo 'Failed to register OpsWorks Stack' ; return 1; fi;
# ...(省略以下指令)
}
# ...(省略其它指令)
if ! REGISTER_AND_ASSIGN_OPSWORKS; then echo 'Set EC2 unhealthy'; /usr/local/bin/aws autoscaling set-instance-health --region $EC2_REGION --instance-id $EC2_ID --health-status Unhealthy --no-should-respect-grace-period || { echo 'Error setting instance health status'; exit 1;}; fi"
echo 'End User Data'
雖然這邏輯本身看似簡單,但最一開始筆者其實是還處在連 shell script 都不是非常熟悉的狀況來接手這個工作的。因此,除了仰賴公司前輩的頂力相助外,也因此同時和 ChatGPT 培養了很不錯的感情。事實上一直到現在,筆者都不確定像這樣子的寫法是否可以算是最佳解,如果讀者有任何想法,也都歡迎留言討論!
加上新的指令後,接下來就會是實驗新指令的過程了。
實驗的過程其實也相當單純,一開始出現問題一樣,透過大量加開機器的方式,來確認註冊失敗的機器是否有成功被關機。 比如說,在某次實驗過程中,我一次加開了 30 台的機器,過程如下:
如下圖,在 OpsWorks 的主控台(console)中,我最後只看到 27 台機器,也就是說有 3 台機器是註冊失敗的狀況。
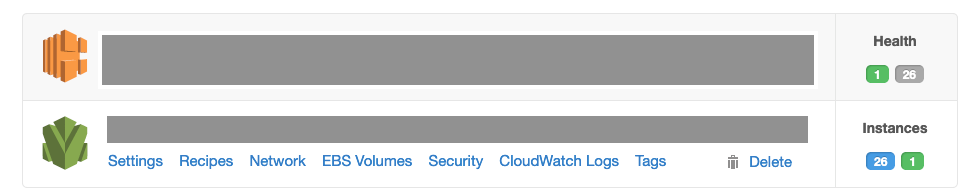
緊接著,我在 EC2 的主控台觀察到有 3 台機器因為被 ASG 判定不健康(unhealthy)而處於關機中(terminating)的狀態。隨著關機的完成,ASG 為了符合 30 台機器的需求,又另外加開了 3 台機器。
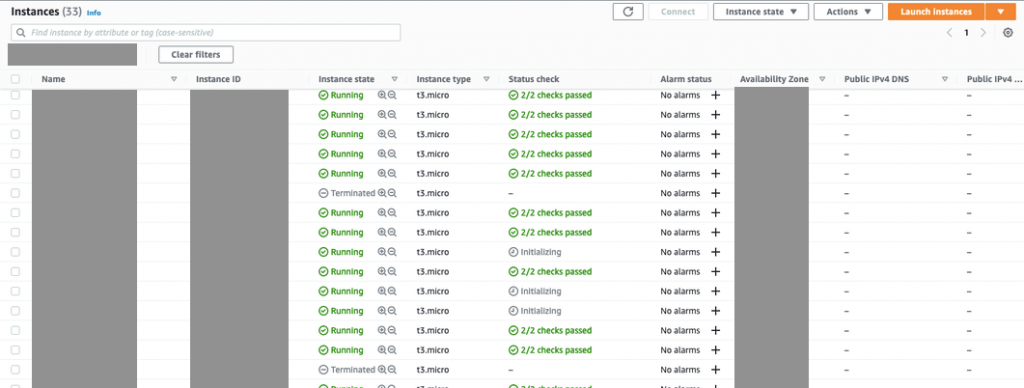
可以在下圖中看到,機器(Instances)的數量總共是 33 台(原本的 30+3 台),其中包含了已經被關機的機器,以及正在開機中(initializing)的機器。
最後,我們回到OpsWorks的主控台,會發現新的 3 台機器成功註冊到 OpsWorks 了。如下圖:

值得一提的是,讀者可以在上圖中看到,其實有一台機器是處在亮紅燈的狀況。也就是雖然有成功註冊 OpsWorks,但卻在註冊後發生問題。這個問題在當下並沒有找出原因,不過筆者懷疑這可能是 Ubuntu 伺服器的問題,並與之後的某次重大 P0 事件有關係。相關的討論會留到那個時候再與讀者分享。
到此為此,我們成功得到了「在幽靈機出現後有效關閉(terminate)的方法」。然而,我們接下來還會需要處理另一個問題,也就是「避免流量被導入幽靈機的方法」。而我們所使用的方式,就是 AWS 提供的 Lifecycle Hooks。
所謂的 Lifecycle,就是在說 EC2 做為一台虛擬機器的一生。如同人有生老病死或冠婚葬祭一樣,EC2 也有屬於它的好幾個生命週期或人生階段。請參考以下這張圖(來源為AWS文件:Instance lifecycle - Amazon Elastic Compute Cloud):
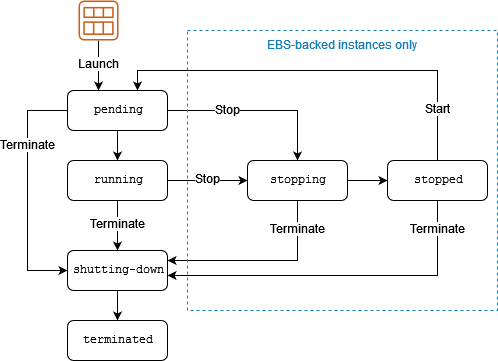
因為一台 EC2 真正能夠接收流量的階段,是進入 running 的階段,因此我們所要做的事情,就是在要求機器「只有在成功註冊 OpsWorks 」之後,才能進入這個階段。 Lifecycle Hooks 這個功能,就是協助我們將 EC2 卡在某個指定階段,並在符合特定條件後才被允許進入下一個階段。
換言之,我們透過 Lifecycle Hooks,在 EC2 啟動(launch)並進入等待(pending)的階段時卡住它,並將「允許 EC2 進入下一個階段」的指令放在 OpsWorks 中。如此一來,只有成功註冊 OpsWorks 的機器,才能獲得該指令並進入 running 的階段,也才能進一步接收流量。至於註冊失敗的機器,就會因為卡住太久而 timeout (一樣是可以在 Lifecycle hooks 中設定),並自動被 ASG 給移除。關於 Lifecycle hooks,也可以參考 AWS 的官方文件:Amazon EC2 Auto Scaling lifecycle hooks - Amazon EC2 Auto Scaling
這邊也分享 OpsWorks 中的「允許 EC2 進入下一個階段」指令如下,其實也就是另一個 AWS CLI Command 而已:
aws --region ${region} autoscaling complete-lifecycle-action --lifecycle-hook-name ${lifecycle} --auto-scaling-group-name ${asg} --lifecycle-action-result CONTINUE --instance-id ${ec2_instance_id}
到此,我們算是解決了這邊的所有主要問題。可以透過以下的流程圖,來複習一下整個過程:
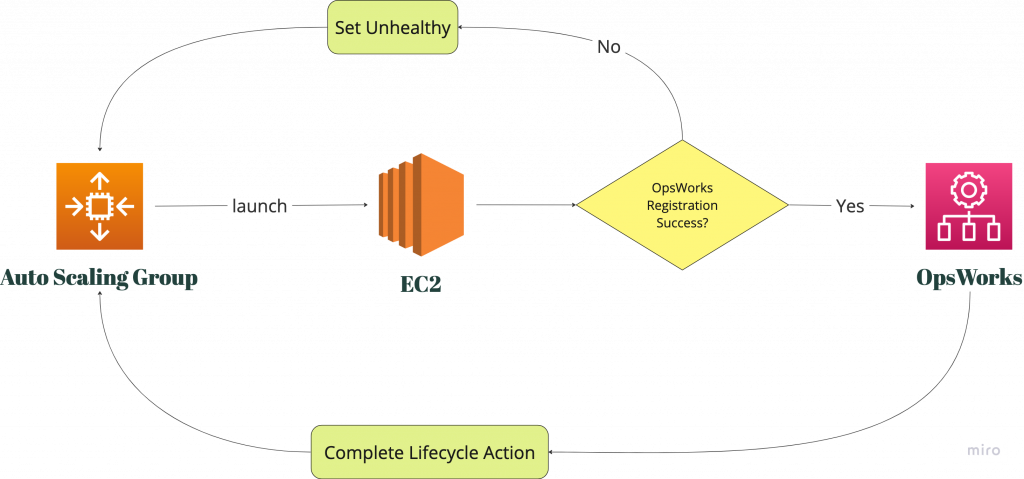
下一篇會分享尚待解決的小問題,以及整個過程中筆者認為值得一提的事情。


 iThome鐵人賽
iThome鐵人賽