介紹了兩個日常維運的系列之後,接下來想分享給各位的,是與部署工具相關的維運。SRE 和 DevOps 有時候相當難區分的地方就在於,維運本身有許多工作難以切割地如此詳細。
雖然敝公司 SRE 與 DevOps 算是兩個不同的團隊,而後者更專注於整個部署流水線的設計,但同樣做為維運相關的團隊,我們彼此間的合作可以算是相當緊密。在未來的文章中,應該也可以看到許多我們團隊間合作的情況。
值得一提的是,這是筆者進入這間公司後接手的第一個大型任務,因此也算是對筆者一個意義重大的工作呢。
這次要介紹的主題,與 AWS OpsWorks 有關。這是一個底層由 Chef 和 Puppet 組合而成的組態管理工具(Configuration as Code)。但讀者其實不用知道太詳細,因為其實筆者在寫這篇文章的時候,這個工具已經被宣告了即將被淘汰的命運。這直接導致了我們必須大幅修改架構並容器化的結果,相關細節也會在之後的文章中再分享給讀者。
在進入主題前,請先細看以下的部署和架構圖:
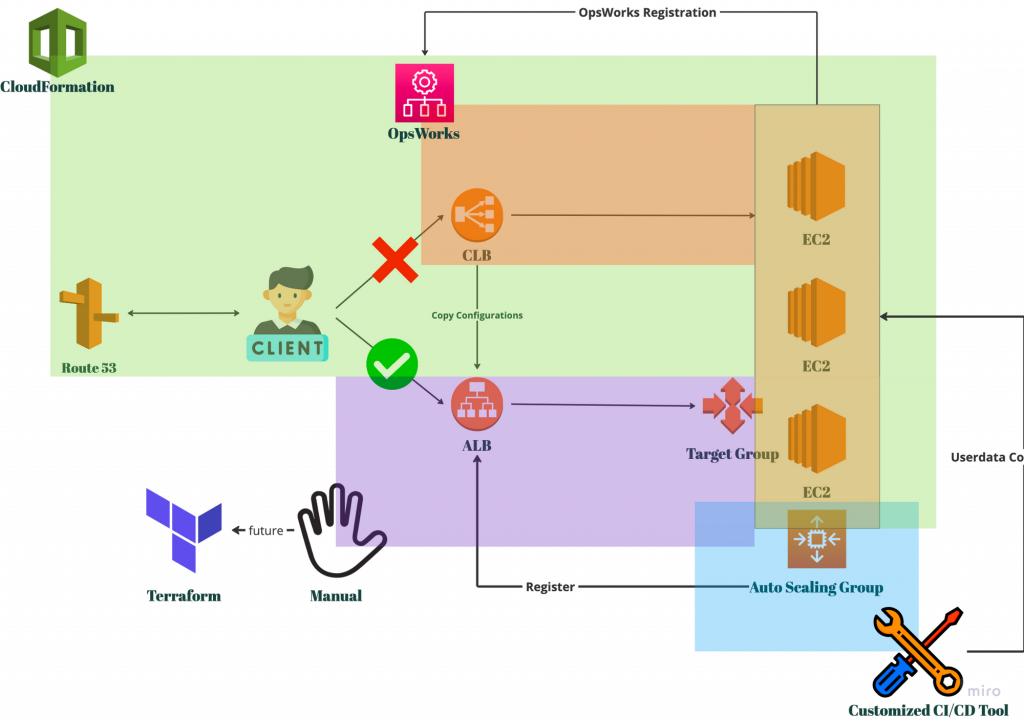
上一個系列中帶各位看到了 Route53、CLB 和 ALB 的部分,這次我們主要聚焦在最右邊的部分。從 EC2 的角度出發,我們的每一台 EC2 都是由 Auto Scaling Group(ASG) 來自動擴展的,而每台 EC2 啟動(launch)的當下,會接收並執行由 ASG 中所定義的 userdata 指令。
所謂的 userdata 就是一連串的系統指令,會要求 EC2 在啟動的時候執行。我們的 userdata 被設定在右下角有標示出來的那個 Customized CI/CD Tool 中,由該工具來管理 ASG 中的各種設定。
userdata 主要的內容,包含了要求 EC2 註冊到 OpsWorks 的 AWS CLI 指令。在 EC2 成功註冊到 OpsWorks 之後,會再透過 OpsWorks 來安裝與程式相關的內容。原本與 CLB 相關的設定也會在此處理,但換到 ALB 之後就沒有了。
以上是整個部署流程架構的簡要介紹,而這裡所面臨到的問題,就是 EC2 在註冊 OpsWorks 的這段指令,有一定的機率會失敗。
註冊失敗會導致的結果是幽靈機器的存在。該幽靈機器被 ASG 開起來後卻沒有註冊到 OpsWorks 上,因此沒有任何程式,相當於是一個空的機器。但因為沒有良好的錯誤處理機制,因此 load balancer 仍然會將流量導向該機器,導致使用者在存取服務的時候有機會遇到錯誤。
原因非常單純,AWS CLI 指令在高頻率地被呼叫時,有機會出現呼叫失敗的狀況。因此這個問題好發於短時間內大量加開機器的情況,因此在熱門活動,比如 promotion 或之前提過的棒球賽,需要加開機器來因應流量的時候,特別容易發生。
這個問題本身沒有特別好的解法,也就是說,註冊失敗導致出現幽靈機的狀況在目前還沒有太好的解決方案。因此我們的解法就會需要達到以下兩個目標:
下一篇文章將會介紹解決方案的研究過程與結果。


 iThome鐵人賽
iThome鐵人賽